任务最高提升75%!ScaleDP:将扩散策略扩展至10亿参数模型,并用于机器人操作
扩散策略(Diffusion Policy)是一种用于学习端到端视触觉机器人控制的强大技术工具。通常情况下,扩散策略具有可扩展性(scalability),这也是深度神经网络的一个关键特征,通常意味着模型规模的增加会带来性能的提升。然而,本文的观察表明,在Transformer架构中的扩散策略(DP-T)在扩展时表现出困难,哪怕是少量增加层数也会导致训练效果的下降。
任务最高提升75%!ScaleDP:将扩散策略扩展至10亿参数模型,并用于机器人操作
原创 Minjie Zhu 具身智能之心 2024年10月31日 08:16 上海

写在前面&ScaleDP的概览
扩散策略(Diffusion Policy)是一种用于学习端到端视触觉机器人控制的强大技术工具。通常情况下,扩散策略具有可扩展性(scalability),这也是深度神经网络的一个关键特征,通常意味着模型规模的增加会带来性能的提升。然而,本文的观察表明,在Transformer架构中的扩散策略(DP-T)在扩展时表现出困难,哪怕是少量增加层数也会导致训练效果的下降。为了解决这一问题,本文提出了一个用于视触觉学习的可扩展扩散Transformer策略(Scalable Diffusion Transformer Policy),简称ScaleDP。方法引入了两个模块,改善了扩散策略的训练动态,并使网络能够更好地处理多模态的动作分布。
首先,我们发现DP-T存在梯度过大的问题,导致扩散策略的优化不稳定。为了解决这个问题,本文将观察的特征嵌入进行分解,并通过多个仿射层(affine layers)整合到Transformer块中。此外,本文还采用了非因果注意力机制(non-causal attention),该机制允许策略网络在预测过程中“看到”未来的动作,从而减少累积误差。我们证明了提出的方法成功地将扩散策略的模型规模从1千万(10 million)参数扩展到10亿(1 billion)参数。这个新的模型称为ScaleDP,能够有效扩展模型规模,并提高性能和泛化能力。
在MetaWorld的50项不同任务中对ScaleDP进行了基准测试,结果表明,我们最大的ScaleDP在性能上比DP-T平均提高了21.6%。在7个实际的机器人任务中,ScaleDP在四个单臂任务中的平均提升为36.25%,在三个双臂任务中提升了75%。我们相信,这项工作为扩展视触觉学习(visuomotor learning)模型的规模奠定了基础。
ScaleDP的设计思路
扩散模型在多个领域的前沿进展中已占据了主导地位,包括图像、音频、视频和3D生成等。具体来说,去噪扩散概率模型(Denoising Diffusion Probabilistic Models, DDPMs)因其逆转随机微分方程(Stochastic Differential Equation)的方法而广受认可。这一技术利用了逐步引入布朗运动的随机去噪过程,在生成输出的过程中起到了重要作用。最近,扩散模型的强大能力在机器人领域中也得到了体现,作为模仿学习的一部分。它已成为机器人学习中最受欢迎的策略之一,推动了一系列在技能学习、导航以及视觉表示方面的改进。
学术界普遍认为,一个有效的方法应具备可扩展性:随着模型规模和训练数据的增加,模型的性能和泛化能力也应相应提升。这一特性,即扩展定律(scaling laws),在诸如语言建模和计算机视觉等机器学习领域取得了显著进展,特别是在大型语言模型的成功应用上。在机器人领域,构建一个能够遵循扩展定律的机器人模型同样是一个重要的目标。然而,扩散策略(Diffusion Policy, DP)是否能够像其他领域中的Transformer模型一样扩展,目前尚未得到深入研究。因此,在本研究中,我们探讨了diffusion transformer在视触觉策略学习中的可扩展性。
我们首先对现有的Transformer架构中的扩散策略(DP-T)进行了分析。为了评估DP-T的可扩展性,在MetaWorld上进行了初步研究(更多细节见第III-A节)。评估结果表明,与之前在扩散策略中的发现一致,扩展DP-T并未带来性能提升,无论是增加深度还是增加头部数量,模型规模的增加反而可能对任务产生负面影响。例如(见图1),DP-T在使用八层时,在MetaWorld中达到了80.1%的成功率。然而,当层数增加到十二时,成功率下降到78.4%,进一步增加到十四层时,成功率降至74.6%。
通过进一步分析,我们发现Transformer架构无法扩展的原因在于,由于观察融合模块(observation fusion module)中的大梯度,导致训练不稳定。通过用多个仿射层替代传统的交叉注意力融合方法,我们能够对参数分布进行归一化,从而为DP-T带来良好的训练动态。为了进一步提升模型的泛化能力,这里提出移除掩码注意力(masked attention),让模型能够“看到”过去的动作和未来的轨迹。这对于学习视触觉策略尤为有利,因为轨迹预测通常比测试时使用的轨迹要长得多。例如,扩散策略预测十个时间步内的动作,但实际只使用第一个时间步的动作。允许模型观察未来的轨迹可以使其在预测过程中对累积误差更加鲁棒。
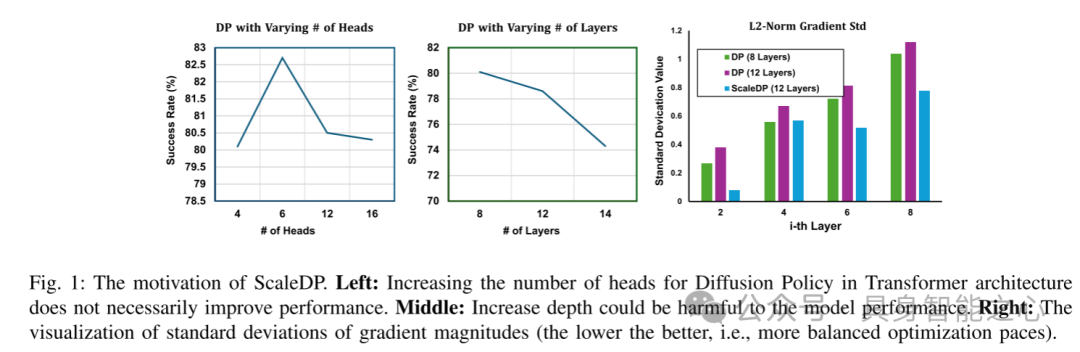
图1:ScaleDP的动机。左图:在Transformer架构中增加扩散策略的注意力头数量不一定能提升性能。中图:增加模型深度可能对模型性能产生不利影响。右图:梯度幅度标准差的可视化(数值越低越好,表示优化步伐更加平衡)。
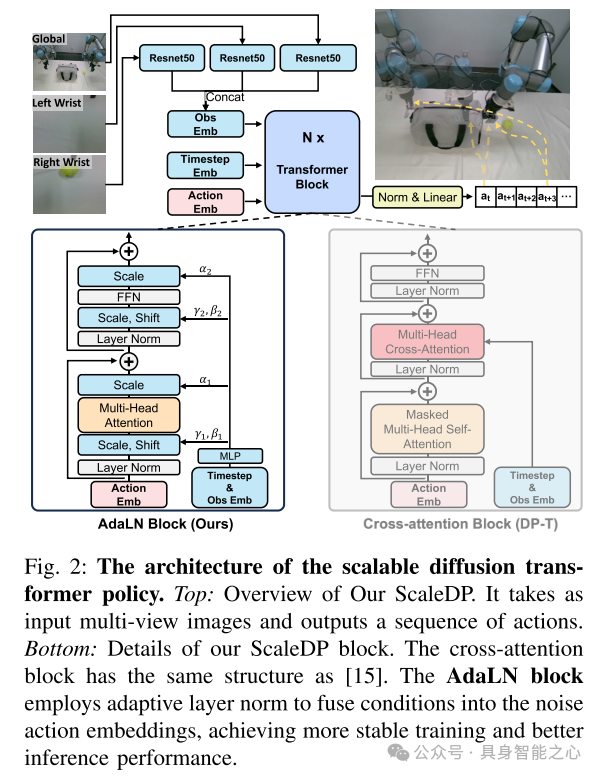
图2:可扩展diffusion transformer policy的架构。上图:提出的ScaleDP的概览。它以多视角图像作为输入,并输出一系列动作。下图:ScaleDP模块的详细结构。交叉注意力模块的结构与相同。AdaLN模块采用自适应层归一化(Adaptive Layer Norm),将条件信息融合到噪声动作嵌入中,从而实现更稳定的训练和更好的推理性能。
ScaleDP的实验验证

图3:为了评估ScaleDP的广泛可扩展性,我们在双臂UR5机器人和Franka机械臂上进行了实验。
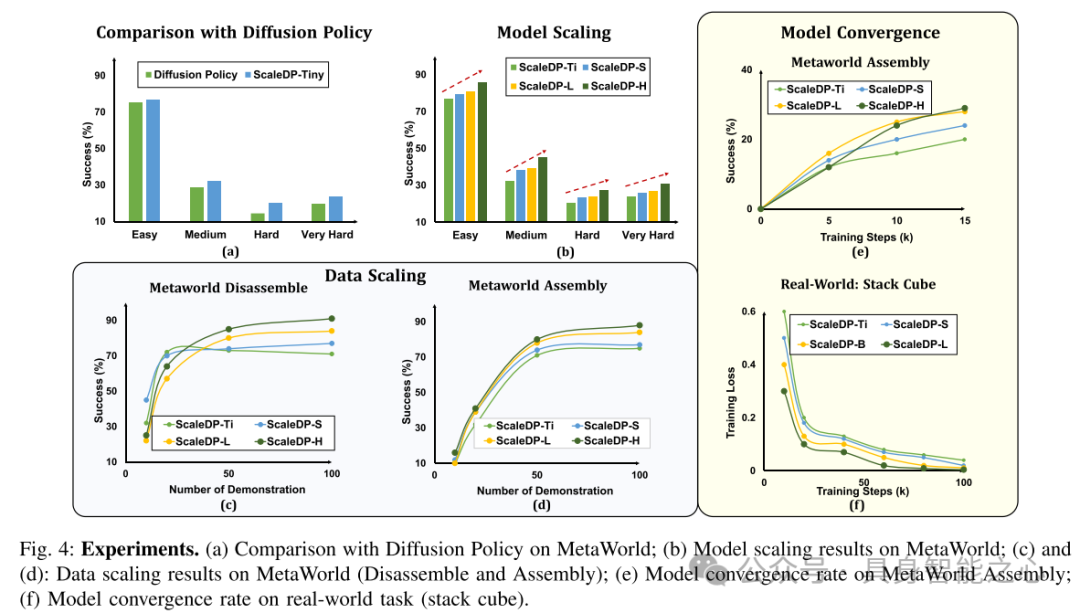
图4:实验结果。(a) 与Diffusion Policy在MetaWorld上的性能对比;(b) 模型在MetaWorld上的扩展结果;(c) 和 (d):在MetaWorld上不同数据量的扩展结果(拆卸和组装任务);(e) 模型在MetaWorld组装任务中的收敛速度;(f) 模型在实际任务(叠立方体)中的收敛速度。
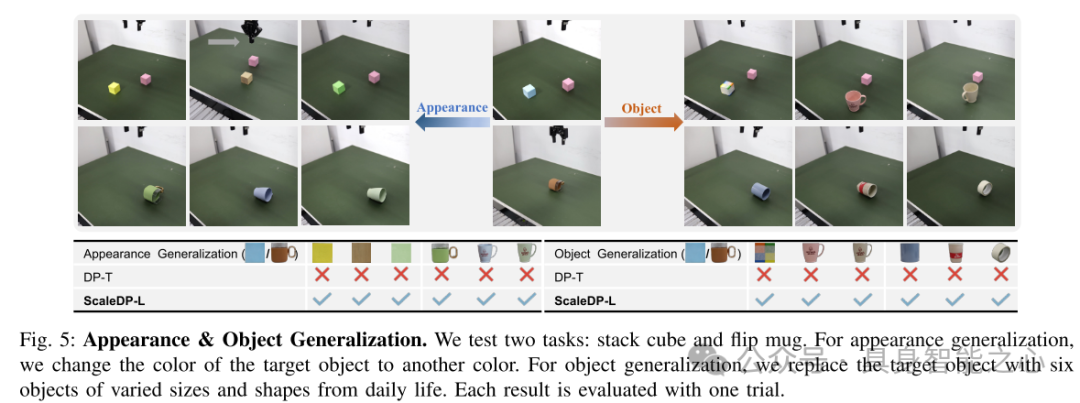
图5:外观与物体泛化。我们测试了两个任务:叠立方体和翻转杯子。对于外观泛化测试,本文将目标物体的颜色更换为其他颜色。对于物体泛化测试,本文将目标物体替换为日常生活中六个不同尺寸和形状的物体。每个结果通过一次试验进行评估。
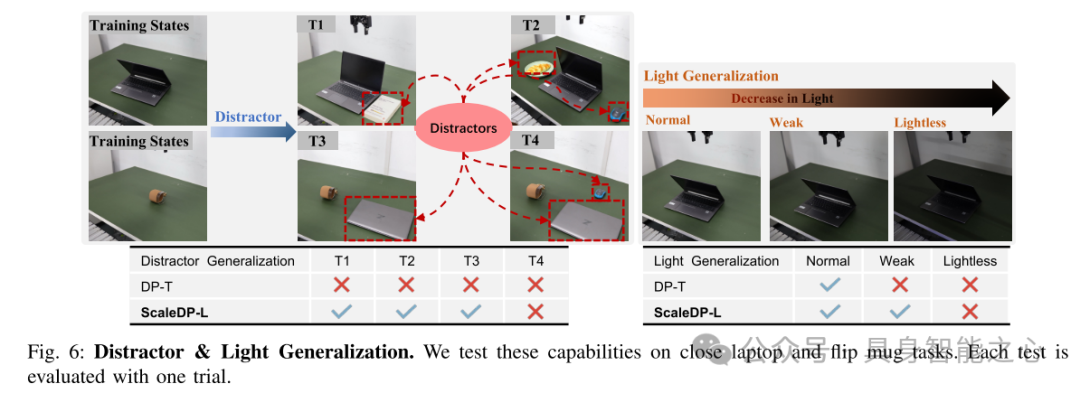
图6:干扰物与光照条件的泛化测试。本文在关闭笔记本电脑和翻转杯子任务上测试了这些泛化能力。每次测试通过一次试验进行评估。
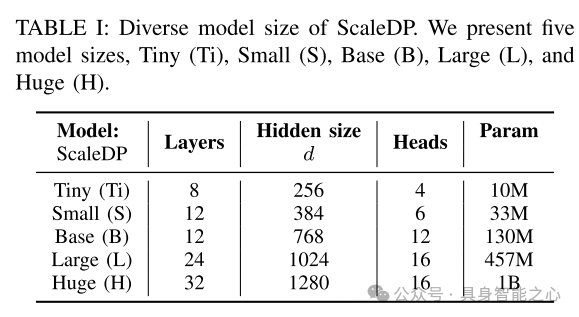
表1:ScaleDP的不同模型规模。本文展示了五种模型规模:Tiny(Ti),Small(S),Base(B),Large(L),以及Huge(H)。
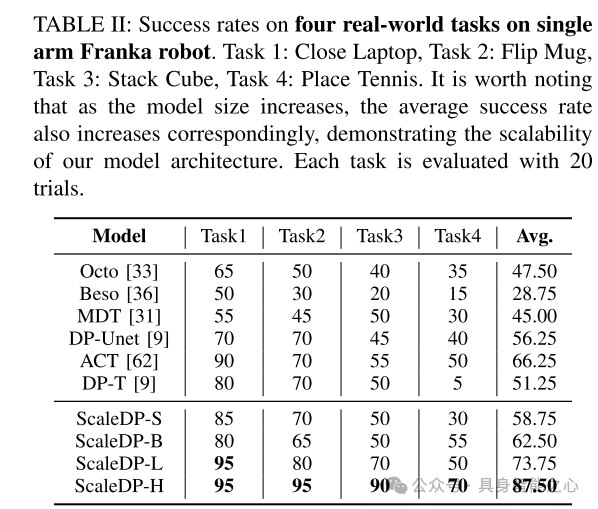
表2:单臂Franka机器人在四个实际任务中的成功率。任务1:关闭笔记本电脑,任务2:翻转杯子,任务3:叠立方体,任务4:放置网球。值得注意的是,随着模型规模的增加,平均成功率也相应提高,展示了我们模型架构的可扩展性。每个任务通过20次试验进行评估。
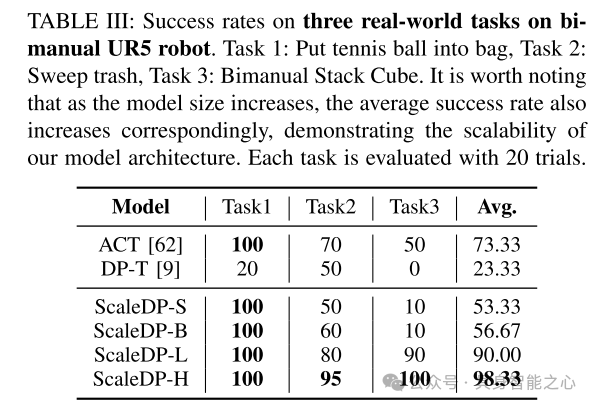
表3:双臂UR5机器人在三个实际任务中的成功率。任务1:将网球放入袋中,任务2:清扫垃圾,任务3:双臂叠立方体。值得注意的是,随着模型规模的增加,平均成功率也相应提高,展示了本文模型架构的可扩展性。每个任务通过20次试验进行评估。
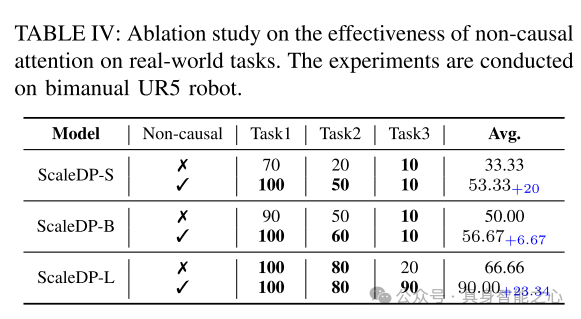
表4:非因果注意力在实际任务中的有效性消融研究。实验在双臂UR5机器人上进行。
最后总结下
我们探讨了Transformer架构在扩散策略(Diffusion Policy)中的应用。发现条件融合中的大梯度问题是Transformer架构中的根本挑战。我们提出的架构通过引入多达10亿参数的模型规模,促进了更有效的训练。初步研究表明,将更多参数融入扩散Transformer策略模型,可以带来在小规模模型中未观察到的特性。我们的方法是首次尝试在基于扩散的模仿学习中扩展模型规模,相信这将成为未来研究的重要方向。
引用:
@misc{zhu2024scalingdiffusionpolicytransformer,
title={Scaling Diffusion Policy in Transformer to 1 Billion Parameters for Robotic Manipulation},
author={Minjie Zhu and Yichen Zhu and Jinming Li and Junjie Wen and Zhiyuan Xu and Ning Liu and Ran Cheng and Chaomin Shen and Yaxin Peng and Feifei Feng and Jian Tang},
year={2024},
eprint={2409.14411},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2409.14411},
}
“具身智能之心

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 25
25 0
0- 0



 已为社区贡献80条内容
已为社区贡献80条内容

所有评论(0)