一种模仿学习方法来训练机器人,而无需进行实际的人类演示
背景大多数人可以通过观察他人仅执行一次任务来学习如何完成给定任务。但是,被编程为通过模仿人类学习的机器人通常需要在一系列人类演示中进行训练,然后才能有效地复制所需的行为。研究人员最近能够使用元学习方法,让机器人观察单个人类演示,从而教机器人执行新任务。但是,这些学习技术通常需要现实世界中的数据,这些数据可能昂贵且难以收集。为了克服这一挑战,伦敦帝国理工学院的一组研究人员开发了一种新方法...
背景
大多数人可以通过观察他人仅执行一次任务来学习如何完成给定任务。但是,被编程为通过模仿人类学习的机器人通常需要在一系列人类演示中进行训练,然后才能有效地复制所需的行为。
研究人员最近能够使用元学习方法,让机器人观察单个人类演示,从而教机器人执行新任务。但是,这些学习技术通常需要现实世界中的数据,这些数据可能昂贵且难以收集。
为了克服这一挑战,伦敦帝国理工学院的一组研究人员开发了一种新方法,该方法无需使用现实世界中的人类演示,即可在机器人中进行一次仿制学习。他们的方法在arXiv上预先发表的一篇论文中提出,使用称为任务嵌入式控制网络(TecNets)的算法,该算法允许人工代理从单个或多个演示中学习如何完成任务,以及人工生成的训练数据。

该机器人具有在模拟中从人类推断动作的能力,然后可以从真实世界中的单个人类演示中学习新任务。
经过训练,我们能够在现实世界中部署一个系统,该系统可以在一次真实世界的人类演示之后以新的配置执行以前看不见的任务。在上图中总结了我们的方法,该方法是在仿真和现实世界中对推送和放置任务进行评估的。我们证明,与在实际数据上训练的系统相比,我们能够获得类似的结果。此外,我们证明了我们的方法对于人类演示者和执行任务的机器人代理之间的视觉域转换(例如,背景完全不同)仍然保持稳健。
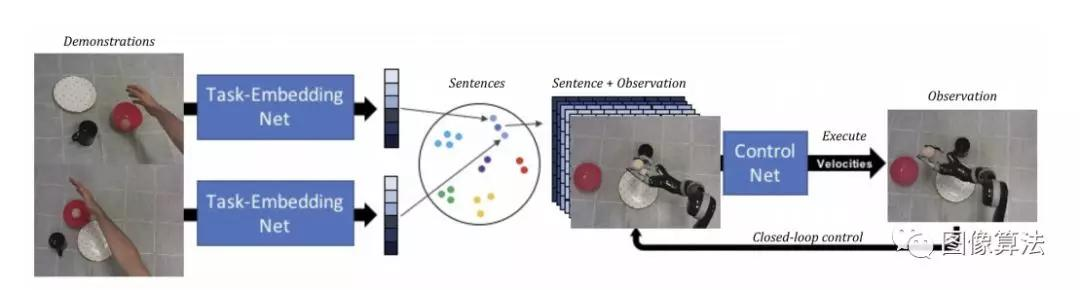
上图中作者使用任务嵌入式控制网络(TecNets)来从单个人类演示中学习任务。人类演示的图像被嵌入到任务的紧凑表示中,然后在以闭环方式通过控制网络发送之前,将其扩展并连接(从通道)到该任务的新配置中的最新观察结果, 联合优化任务嵌入网络和控制网络以产生丰富的嵌入。
相关工作
模仿学习的目的是通过观察主持人来学习任务,大致可分为两个关键领域:
- 行为克隆,即代理学习从观察到给定演示的动作的映射。
- 逆向强化学习,代理人尝试估计描述给定示范的奖励函数。在这项工作中,我们专注于前者。行为克隆的大部分工作都是在一组配置空间轨迹上进行的,这些轨迹可以通过远程操作,运动学教学,人类演示者上的传感器,运动计划器甚至直接观察人类来收集。在后者上进一步扩展,通过观察人类的学习,以前是通过人工设计的人类动作和机器人动作之间的映射,视觉活动识别和明确的手部跟踪来实现的,最近,该系统还通过从人类单个视频通过 端到端训练有素的系统。
单发和少发学习是在测试时从少量示例中进行学习的范例,并且已在图像识别社区中进行了广泛的研究。作者的方法基于James等, 它属于度量学习领域
度量学习中有很多工作,包括Matching Networks,在给定标记的示例称为支持集和无标记的示例称为查询集的情况下,Matching Networks在学习的嵌入空间上使用注意力机制来生成加权最近邻分类器。
原型网络是相似的,但是不同之处在于它们通过实例,原型代表每个类别,并使用平方的欧几里德距离而不是余弦距离。在单发学习的情况下,匹配网络和原型网络变得等效。
模拟到真实的方法试图解决模拟与真实世界之间视觉和动态方面的明显领域差距,从而减少了对昂贵的真实数据收集的需求。已经显示出不可能在两个领域之间天真地转移技能,这导致了在计算机视觉和机器人技术中大量尝试转移方法的尝试。
将随机纹理,照明和摄像机位置应用于模拟场景的领域随机化在众多基于视觉的机器人应用中取得了巨大的成功,这种方法使在这些随机场景上运行的算法对于在现实世界中出现的域差异变得不变。
RCAN不是直接对随机图像进行操作,而是一种最新方法,它可以将随机渲染的图像转换为等效的非随机规范化版本,从而在复杂的从模拟到真实的抓取任务中产生出色的结果。其他作品未对RGB图像进行操作,而是使用深度图像来跨越域间隙。但是,在我们的任务中,推断机器人需要与之交互的对象时,尤其是当对象的几何形状非常相似时,对象的颜色是重要的功能。在我们的工作中,我们表明可以利用域随机化来转移从人类演示中推断行动的能力。
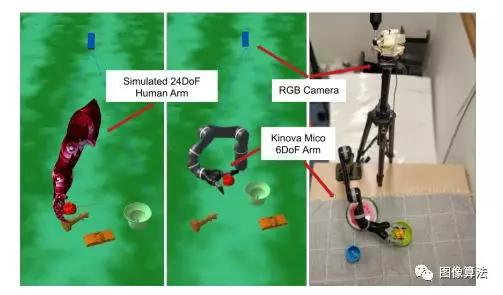
将域随机化应用于模拟人手臂时得到的变化示例

下图是模拟和现实世界的设置。左边是24 DoF臂,中间是6 DoF Kinova Mico臂。两者都应用了域随机化。在右侧,我们可以看到Kinova Mico的实际设置。观察来自模拟和现实世界中的单肩RGB相机。
下图我们在现实世界中评估模型的三个任务。左:将一个物体放置在一个带有两个干扰器的容器中,对人类和机器人使用相同的相机姿势,并使用相同的背景。居中:与左侧相同的放置任务,但在人类演示和机器人执行之间发生了区域转移(桌子上有布)。右:用一个干扰物将一个物体推向目标,人和机器人的相机姿势相同,背景相同。

看看放置(a)和推送(b)域的真实测试集,对于放置区域(a),放置对象位于顶部,放置对象(由碗,盘子,杯子和盆子组成)位于底部。

结果
在我们的实验中,作者尝试回答以下问题:
(1)TecNets是否可以学习演示者与代理之间的域转换?换句话说,我们的方法能否学习给定演示者示例的任务的嵌入,以及从演示者域到代理域的映射以进行控制?
(2)完成所有训练后,是否可以从真实的人类演示中学习任务?
(3)我们的方法与另一种先进的单次人类模仿学习方法相比如何?我们考虑对DAML进行了两个实验,即放置和推动,以便将我们的方法与其结果进行比较。
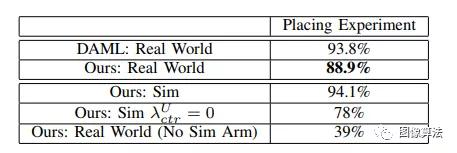
表中是一次性完成放置实验,依然可达到DAML相当的性能。
结论
该团队在模拟和现实世界中都评估了这种新的一次性学习方法,并使用它训练机器人来完成涉及放置和推动对象的任务。值得注意的是,他们的学习方法所取得的成果可与使用更传统的基于模仿学习的方法所取得的成果相提并论,尽管它需要在人工生成的视频而非真实的人类演示上训练机器人。
研究人员在论文中写道:“我们希望进一步研究可以从模拟转移到现实的各种人类行为。“例如,在这项工作中,我们已经证明了可以转移人的手臂,但是同样的方法在包括人的整个躯干在内的也会起作用吗?”
论文源码下载地址:关注“图像算法”微信公众号 回复“TecNets”

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)