用Python构建高效法律文本爬虫:从国家法律法规数据库获取结构化法律数据
·
一、项目背景与意义
爬取国家法律法规数据库是为了获取法律数据(宪法、法律、行政法规、监察、司法解释、地方性法规)以实现项目的法律查询功能。
二、技术架构解析
2.1 核心组件示意图
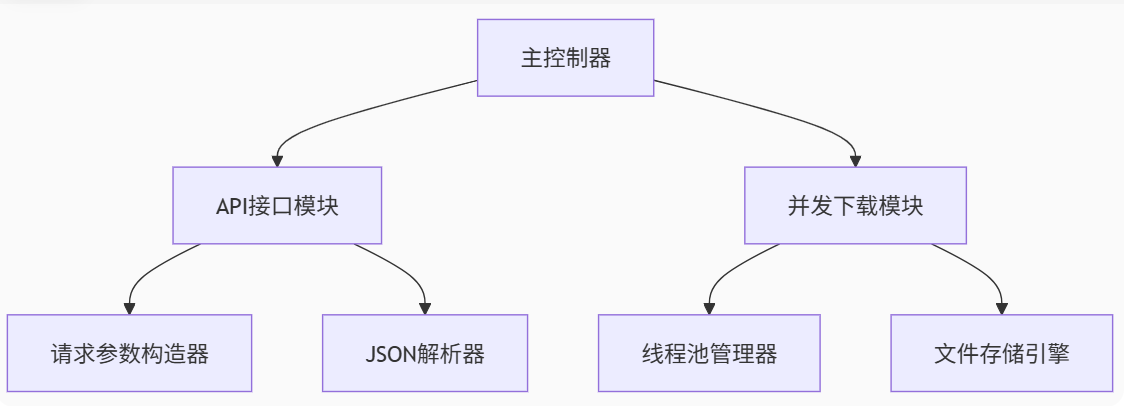
2.2 关键技术栈
-
请求模拟:Requests库实现Header伪装
-
并发处理:ThreadPoolExecutor线程池
-
数据解析:多层JSON结构解析
-
异常处理:请求重试与错误日志
-
文件管理:自动化目录创建
三、核心代码剖析
3.1 智能请求头配置
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36...'
}通过完整的浏览器UA模拟,有效绕过基础反爬机制
3.2 动态参数构造
params = {
'type': t,
'searchType': 'title;vague',
'sortTr': 'f_bbrq_s;desc',
'page': '1',
'size': '10',
'_': str(int(time.time() * 1000))
}时间戳参数保证每次请求的唯一性,防止缓存
3.3 三级采集流程
-
列表采集:获取法律文件元数据
-
详情抓取:提取PDF下载路径
-
文件下载:二进制流存储
3.4 并发控制模型
with ThreadPoolExecutor(max_workers=5) as executor:
futures = []
for id in id_pool:
futures.append(executor.submit(download_task))
for future in futures:
future.result()双队列模式保证任务有序执行
四、部署与使用指南
4.1 环境要求
-
Python 3.8+
-
依赖库:requests, concurrent.futures
-
磁盘空间:建议预留10GB+
4.2 文件存储结构
├── flfg ├── xzfg ├── jcfg ├── sfjs ├── dfxfg └── xf
5 完整代码:
import requests
import os
import time
from concurrent.futures import ThreadPoolExecutor
# 设置请求头,模拟浏览器行为
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
# 定义要爬取的法律文件类型
type = [
'flfg', # 法律法规
'xzfg', # 行政法规
'jcfg', # 监察法规
'sfjs', # 司法解释
'dfxfg' # 地方性法规
]
# 定义API接口地址
url = 'https://flk.npc.gov.cn/api/?' # 法律文件列表的API地址
detail_url = 'https://flk.npc.gov.cn/api/detail' # 法律文件详细信息的API地址
download_base_url = 'https://wb.flk.npc.gov.cn' # 文件下载的基础URL
# 创建对应的文件夹
for t in type:
if not os.path.exists(t):
os.mkdir(t) # 如果文件夹不存在,则创建
def fetch_data(url, params, headers):
"""发送GET请求并返回JSON数据"""
try:
response = requests.get(url, params=params, headers=headers)
response.raise_for_status()
return response.json()
except requests.RequestException as e:
print(f"Failed to fetch data: {e}")
return None
def fetch_detail(id):
"""获取文件详细信息"""
data = {'id': id}
try:
response = requests.post(detail_url, data=data, headers=headers)
response.raise_for_status()
return response.json()
except requests.RequestException as e:
print(f"Failed to fetch detail for id {id}: {e}")
return None
def download_file(url, path, name):
"""下载文件并保存"""
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
with open(path + '/' + name, mode='wb') as f:
f.write(response.content)
print(f"File saved: {path}/{name}")
except requests.RequestException as e:
print(f"Failed to download file: {e}")
# 爬取不同类型法律文件
def process_type(t):
data = {
'type': t,
'searchType': 'title;vague',
'sortTr': 'f_bbrq_s;desc',
'gbrqStart': '',
'gbrqEnd': '',
'sxrqStart': '',
'sxrqEnd': '',
'sort': 'true',
'page': '1',
'size': '10',
'_': str(int(time.time() * 1000))
}
response_json = fetch_data(url, params=data, headers=headers)
if not response_json:
return
id_pool = [(item['id'], item['title']) for item in response_json['result']['data']]
with ThreadPoolExecutor(max_workers=5) as executor:
futures = []
for id_and_title in id_pool:
id, title = id_and_title
detail_data = fetch_detail(id)
if not detail_data:
continue
download_url = download_base_url + detail_data['result']['body'][0]['path']
name = detail_data['result']['body'][0]['path'].split('.')[-1]
futures.append(executor.submit(download_file, download_url, t, title + '.' + name))
for future in futures:
future.result()
# 爬取宪法内容
def process_constitution():
if not os.path.exists('xf'):
os.mkdir('xf')
response_json = fetch_data(xf_url, params={}, headers=headers)
if not response_json:
return
with ThreadPoolExecutor(max_workers=5) as executor:
futures = []
for i in range(0, 7):
id = response_json['result']['data'][i]['id']
title = response_json['result']['data'][i]['title']
detail_data = fetch_detail(id)
if not detail_data:
continue
download_url = download_base_url + detail_data['result']['body'][0]['path']
name = detail_data['result']['body'][0]['path'].split('.')[-1]
futures.append(executor.submit(download_file, download_url, 'xf', title + '.' + name))
for future in futures:
future.result()
if __name__ == "__main__":
with ThreadPoolExecutor(max_workers=5) as executor:
executor.map(process_type, type)
process_constitution()
DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)