大数据毕业设计python+spark高考志愿填报推荐系统 高考用户画像系统 高考分数线预测系统 高考可视化 知识图谱 高考爬虫 计算机毕业设计 机器学习 深度学习 人工智能 数据可视化
大数据毕业设计python+spark高考志愿填报推荐系统 高考用户画像系统 高考分数线预测系统 高考可视化 知识图谱 高考爬虫 计算机毕业设计 机器学习 深度学习 人工智能 数据可视化
·
高考大数据目前4个版本:
【本网页所在的视频属于V3.0.0完整版录屏】
V1.0.0(丐帮版,推荐采用手动推荐)
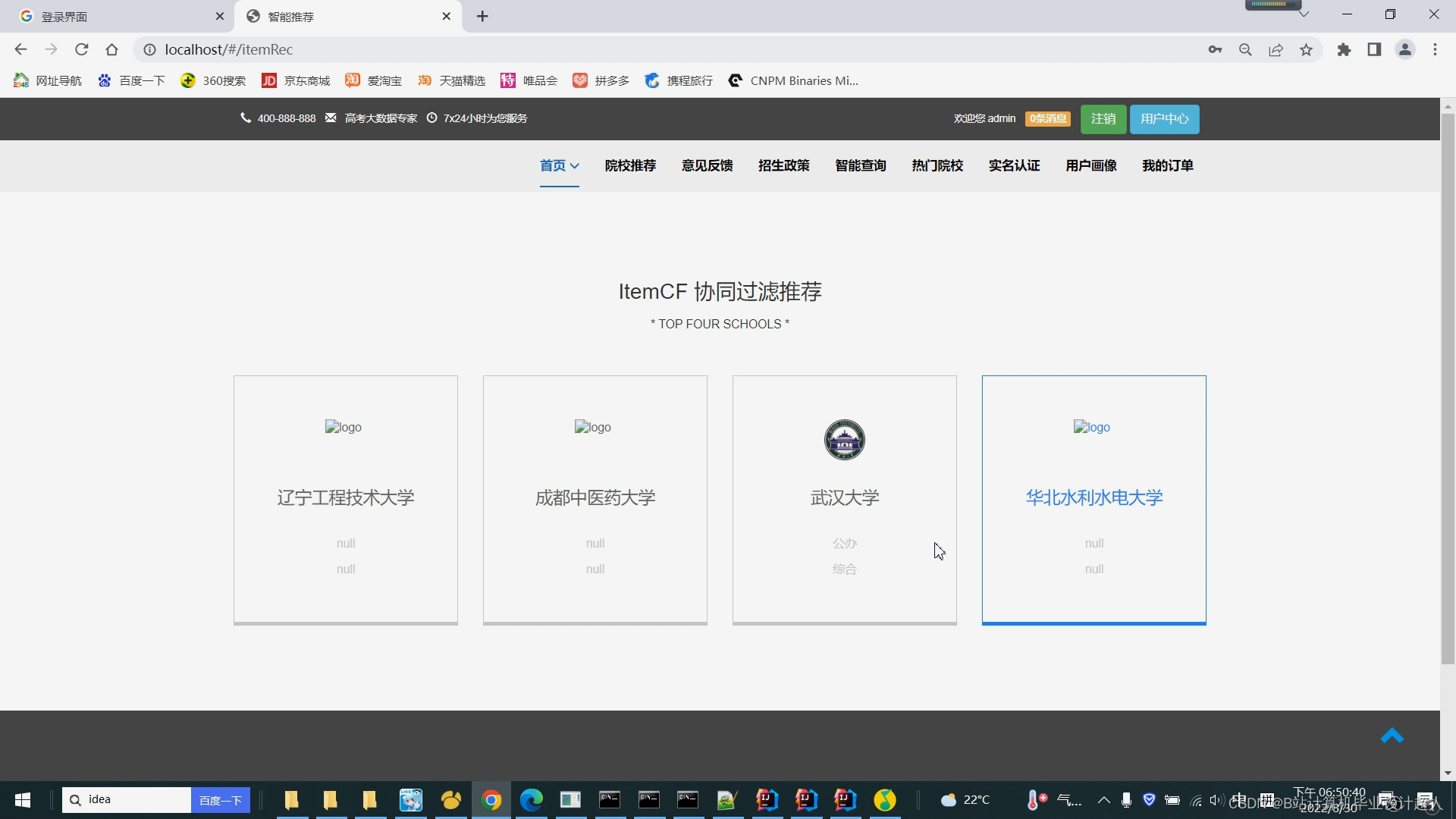
V2.0.0(中配版,推荐采用手动推荐+协同过滤,无爬虫、无lstm情感分析)
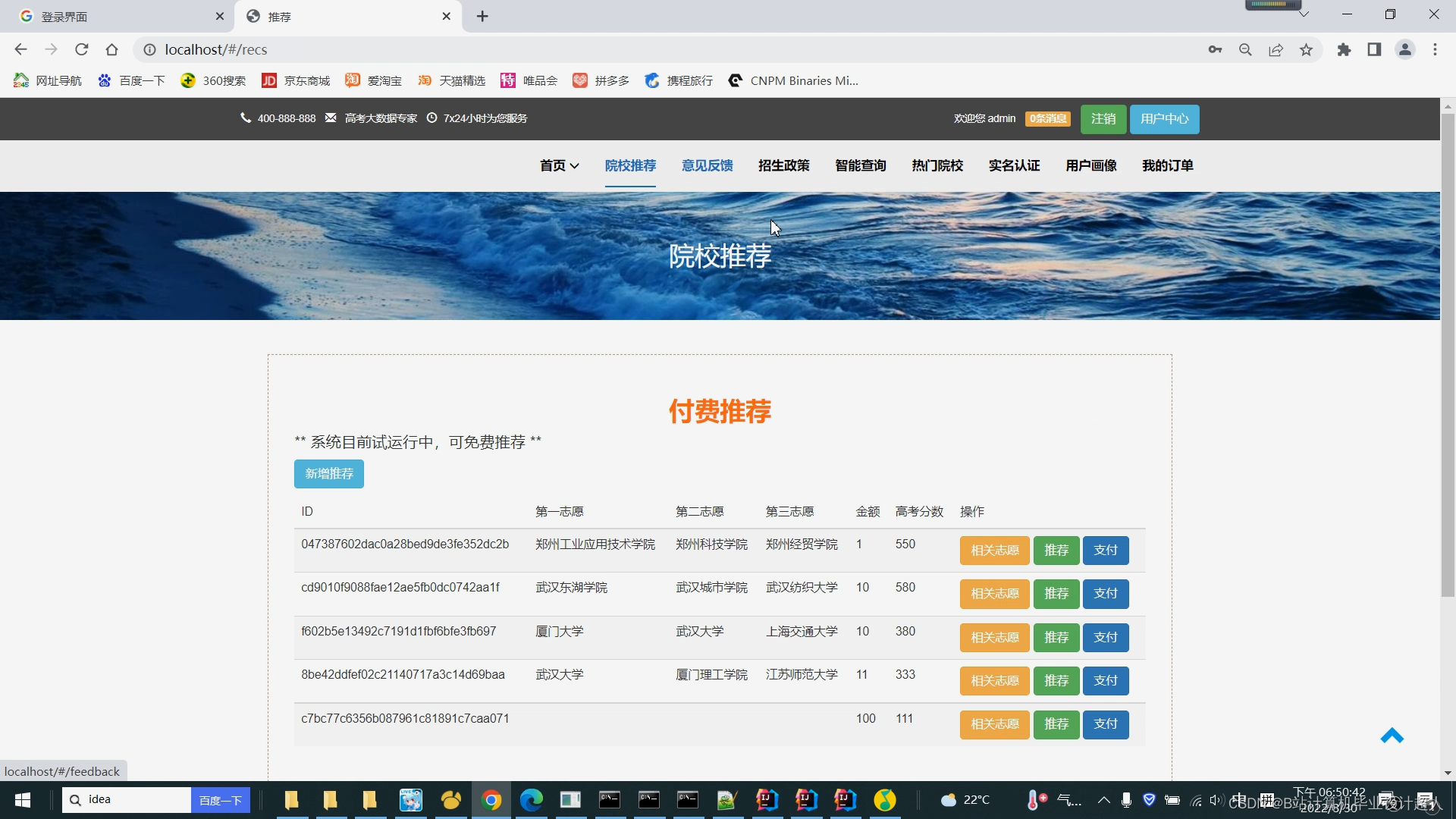
V3.0.0(完整版,推荐、爬虫、lstm情感分析一应俱全)
V4.0.0(具备1.0 2.0 3.0的功能以外新增4种深度学习推荐算法 知识图谱 vmvare Linux虚拟机 hive数据仓库 spark实时计算 海量亿级高考数据爬虫 分数线预测 模拟志愿填报)

import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
# 读取学生数据集,包括学生的成绩、兴趣爱好、专业倾向等特征
student_data = pd.read_csv('student_data.csv')
# 数据预处理
X = student_data.drop(columns=['major_preference']) # 特征变量
y = student_data['major_preference'] # 目标变量
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练随机森林分类器模型
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
rf_model.fit(X_train, y_train)
# 进行志愿推荐
student_features = [...] # 学生的特征,包括成绩、兴趣爱好等
predicted_major_preference = rf_model.predict([student_features])
# 输出推荐结果
print(f"根据您的特征,推荐的专业倾向为: {predicted_major_preference[0]}")
在这个示例中,我们假设学生数据集包含了一些学生的特征变量(如成绩、兴趣爱好等)以及目标变量‘major_preference’,表示学生的专业倾向。我们使用随机森林分类器来训练模型,并利用该模型对学生进行专业倾向的推荐。
实际的高考志愿填报推荐系统可能需要更复杂的特征工程和模型调优,还可能需要考虑学校专业的排名、就业前景等因素。因此,您可以根据具体情况对代码进行进一步优化和调整。请确保数据集的质量和特征选择对于模型的性能至关重要。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 12
12 0
0- 0



 已为社区贡献199条内容
已为社区贡献199条内容

所有评论(0)