数据处理使用的三个主要库之Pandas库
(1)当你的处理逻辑复杂时,用lambda就不够了,此时你可以定义一个函数,然后用apply来调用它。return '优秀'return '及格'else:return '不及格'df['成绩分类'] = df['成绩'].apply(classify_score)这样我们就给“成绩”列加了一个“分类”列,非常适合批量数据标签化、规则判断等。(2)对每行应用自定义函数(axis=1)return
一.Pandas简介
1.什么是pandas
(1)Pandas 是 Python 中最流行的数据处理和分析库之一,它提供了:
高性能的数据结构:如 Series 和 DataFrame;
强大的数据操作工具:比如筛选、排序、分组、透视、缺失值处理等
名字由来:Pandas 的名字来源于 “Panel Data”(面板数据),用于表示多维结构化数据。
(2)关键特点:
| 特性 | 说明 |
| 快速且高效 | 操作数据时运行速度快 |
| 结构清晰 | 类似 Excel 或数据库的表格 |
| 易于集成 | 和 NumPy、Matplotlib、Scikit-learn 配合良好 |
| 适用于各种格式的数据 | CSV、Excel、SQL、JSON、剪贴板等都能处理 |
2.能解决什么问题
Pandas 是为了解决 结构化数据分析 而诞生的,主要应对的是 Excel / SQL 表格级别的任务,在以下场景中极为常见:
| 场景 | 示例 |
| 数据读取 | 从 CSV、Excel、数据库中读取数据 |
| 数据清洗 | 删除重复值、处理缺失值、标准化列名等 |
| 数据分析 | 分组统计、透视表、描述性分析 |
| 数据变换 | 新增列、重命名、排序、类型转换 |
| 数据导出 | 将处理结果保存为 CSV/Excel |
3.Pandas与NumPy的关系
Pandas 实际上是 构建在 NumPy 之上的更高层工具库,两者经常搭配使用,但功能和定位不同。
| 对比项 | NumPy | Pandas |
| 数据结构 | ndarray(一维/多维数组) | Series(一维)、DataFrame(二维) |
| 索引机制 | 只能用位置索引 | 支持标签索引(更像 Excel 表头) |
| 数据处理能力 | 偏数学计算,适合数值数组 | 偏数据分析,适合表格型数据 |
| 应用场景 | 科学计算、矩阵运算 | 数据清洗、数据探索、数据分析 |
| 示例 | np.mean(arr) | df['销售额'].mean() |
如果你把 NumPy 当作“计算引擎”,那么 Pandas 就像是“操作数据的 Excel 表格工具箱”,既能和 NumPy 配合计算,又提供了更高层次的灵活性。
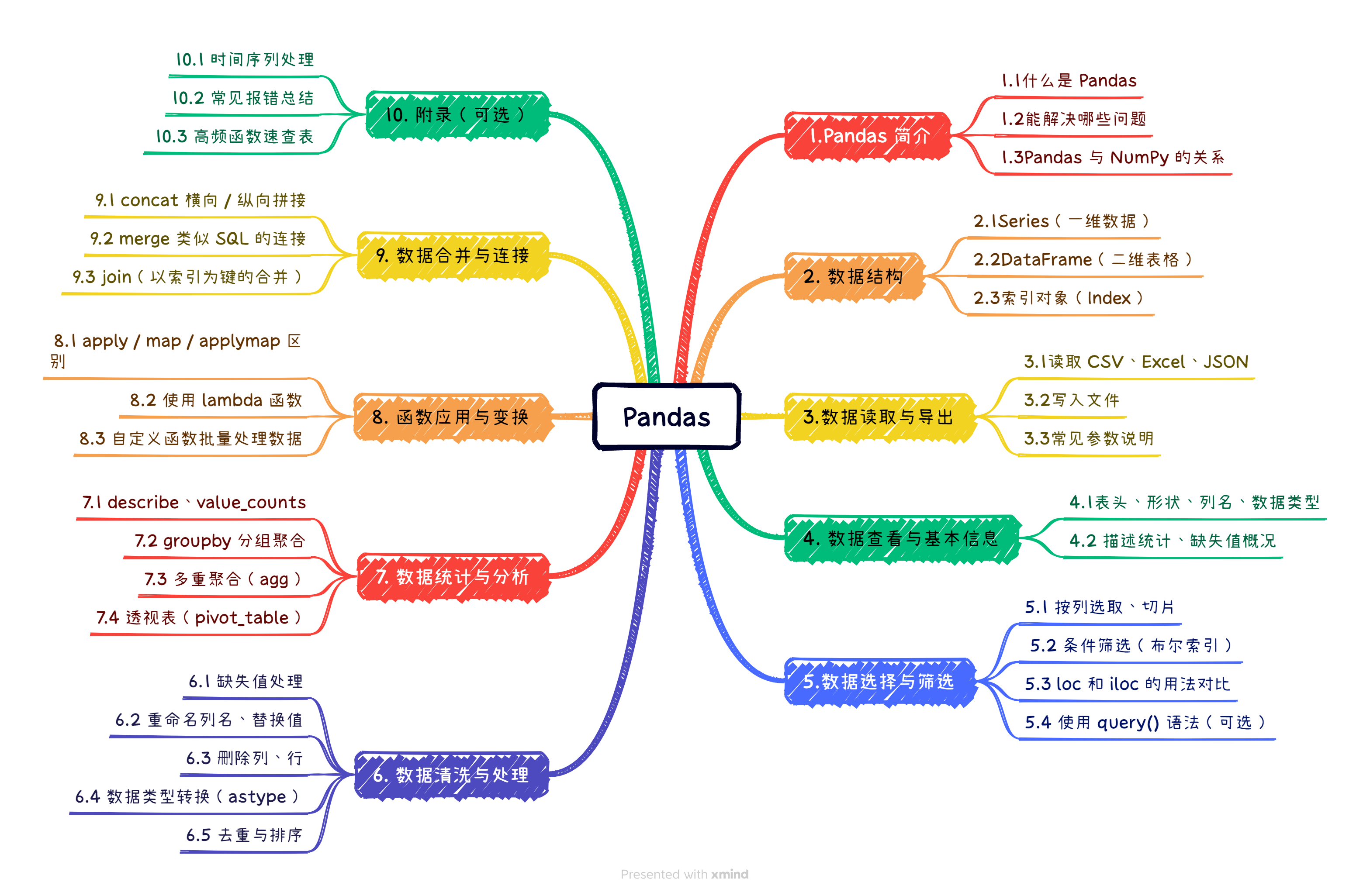
二.数据结构
1.Series(一维数据)
(1)Series 是 Pandas 中的一种一维数据结构,可以看作是带标签的数组,类似于 Python 中的列表(list),但每个元素都有一个“索引”
(2)结构:索引(index) -> 值(value)
import pandas as pd
s = pd.Series([10, 20, 30])
print(s)
#输出
#0 10
#1 20
#2 30
#dtype: int64
s = pd.Series([10, 20, 30], index=['a', 'b', 'c'])
#a 10
#b 20
#c 30
#dtype: int64(3)常用操作
| 操作 | 代码 | 说明 |
| 获取值 | s['a'] | 返回10 |
| 切片 | s[0:2] | 返回前两个元素 |
| 加减 | s + 5 | 每个元素加5 |
| 筛选 | s[s > 15] | 选出大于15的值 |
2.DataFrame(二维数据)
(1)DataFrame 是 Pandas 中最常用的二维表格型数据结构,你可以把它想象成:类似 Excel 表格 或 数据库表,一张包含“行”和“列”的数据表
(2)结构
| 索引(index) | 列A | 列B |
| 0 | 10 | 100 |
| 1 | 20 | 200 |
import pandas as pd
data = {
'产品': ['A', 'B', 'C'],
'价格': [100, 150, 200]
}
df = pd.DataFrame(data)
print(df)
# 产品 价格
#0 A 100
#1 B 150
#2 C 200
(3)常用操作
| 操作 | 代码 | 说明 |
| 查看表头 | df.head() | 默认前5行 |
| 取某列 | df['价格'] | 返回Series |
| 取多列 | df['产品',‘价格’] | 返回DataFrame |
| 筛选 | df[df['价格']>120] | 条件筛选 |
| 添加列 | df['折扣价'= df['价格']*0.9] | 新增列 |
| 删除列 | df.drop('列名', axis=1) | 删除列 |
import pandas as pd
data = {
'产品': ['A', 'B', 'C', 'D'],
'价格': [100, 150, 200, 120],
'销量': [30, 45, 20, 40]
}
df = pd.DataFrame(data)
print(df)
#输出
# 产品 价格 销量
#0 A 100 30
#1 B 150 45
#2 C 200 20
#3 D 120 40
df.head()
#输出
# 产品 价格 销量
#0 A 100 30
#1 B 150 45
#2 C 200 20
#3 D 120 40
df['价格']
#0 100
#1 150
#2 200
#3 120
#Name: 价格, dtype: int64
df[['产品', '销量']]
# 产品 销量
#0 A 30
#1 B 45
#2 C 20
#3 D 40
df[df['价格'] > 120]
#1 B 150 45
#2 C 200 20
df['折扣价'] = df['价格'] * 0.9
# 产品 价格 销量 折扣价
#0 A 100 30 90.0
#1 B 150 45 135.0
#2 C 200 20 180.0
#3 D 120 40 108.0
df.drop('销量', axis=1, inplace=True)
# 产品 价格 折扣价
#0 A 100 90.0
#1 B 150 135.0
#2 C 200 180.0
#3 D 120 108.0
df.sort_values(by='价格', ascending=False)
# 产品 价格 折扣价
#2 C 200 180.0
#1 B 150 135.0
#3 D 120 108.0
#0 A 100 90.0
df['价格'].mean() # 平均价格
df['价格'].max() # 最大价格
df['价格'].sum() # 总价格
3.索引对象(Index)
(1)Index 是 Pandas 中的索引结构,用来标识数据的“标签”。在 Series 和 DataFrame 中,索引就像是数据的“行名”或“行号”,用于快速定位数据。
s = pd.Series([10, 20, 30], index=['x', 'y', 'z'])
print(s.index)
#输出
#Index(['x', 'y', 'z'], dtype='object')
(2)索引作用
| 功能 | 示例 |
| 定位数据 | s['x'] 或 df.loc['x'] |
| 对齐操作 | 不同Series相加时根据index自动对齐 |
| 自定义索引 | 可以用任意可哈希对象作为索引 |
(3)注意事项
索引可以重复,但不推荐(影响 groupby 等操作)
可以通过 df.set_index('列名') 设置某列为索引
可以通过 df.reset_index() 还原为默认索引
本节小结:
三.数据读取与导出
1.读取 CSV、Excel、JSON
读取 CSV、Excel、JSON 文件
#读取CSV文件
df = pd.read_csv('文件路径.csv')
import pandas as pd
df = pd.read_csv('data/sales.csv')
print(df.head())
#读取Excel文件
df = pd.read_excel('文件路径.xlsx', sheet_name='Sheet1')
df = pd.read_excel('data/sales.xlsx', sheet_name='Q1')
#读取JSON文件
df = pd.read_json('文件路径.json')
df = pd.read_json('data/sample.json')
csv常用于读取 Excel 导出的表格、清洗后的数据等。JSON 格式常用于网络爬虫、API 返回的数据。
2.导出数据
导出为csv文件、excel文件、JSON文件
#导出为CSV文件
df.to_csv('保存路径.csv', index=False, encoding='utf-8')
df.to_csv('output/result.csv', index=False, encoding='utf-8-sig')
#导出为excel文件
df.to_excel('保存路径.xlsx', index=False)
df.to_excel('output/result.xlsx', index=False)
# 导出为 JSON 文件
df.to_json('保存路径.json', orient='records', force_ascii=False)
df.to_json('output/result.json', orient='records', force_ascii=False)
注:index=False:不保存索引列;encoding='utf-8-sig':防止中文乱码(特别是写给 Excel 用)
3.常见参数说明(encoding, header, index_col等)
这些参数可以帮你灵活应对文件中各种“坑爹格式”:
| 参数名 | 作用 | 常用设置 |
| encoding | 设定编码格式,避免乱码 | 'utf-8', 'gbk', 'utf-8-sig' |
| header | 指定哪一行是表头 | 0(默认第一行),或None表示无表头 |
| index_col | 指定哪一列为索引列 | 0表示用第一列为索引;也可传列名 |
| usecols | 选定读取的列 | ['产品',‘价格’] |
| nrows | 只读取前n行 | nrows=100 |
| skiprows | 跳过前几行再读 | skiprows=2 |
| na_values | 指定哪些值视为缺失值 | ['N/A', '-', 'null'] |
df = pd.read_csv(
'data/销售数据.csv',
encoding='utf-8-sig',
skiprows=2,
index_col='产品编号',
usecols=['产品编号', '名称', '销量', '单价']
)
本章小结:
| 类型 | 读取 | 写入 |
| CSV | read_csv() | to_csv() |
| Excel | read_excel() | to_excel() |
| JSON | read_json() | to_json() |
注:遇到中文乱码用 encoding='utf-8-sig' 或 encoding='gbk';若 Excel 表头不是第一行,用 header=行号;若第一列是 ID,可以用 index_col=0。
四.数据查看与基本信息
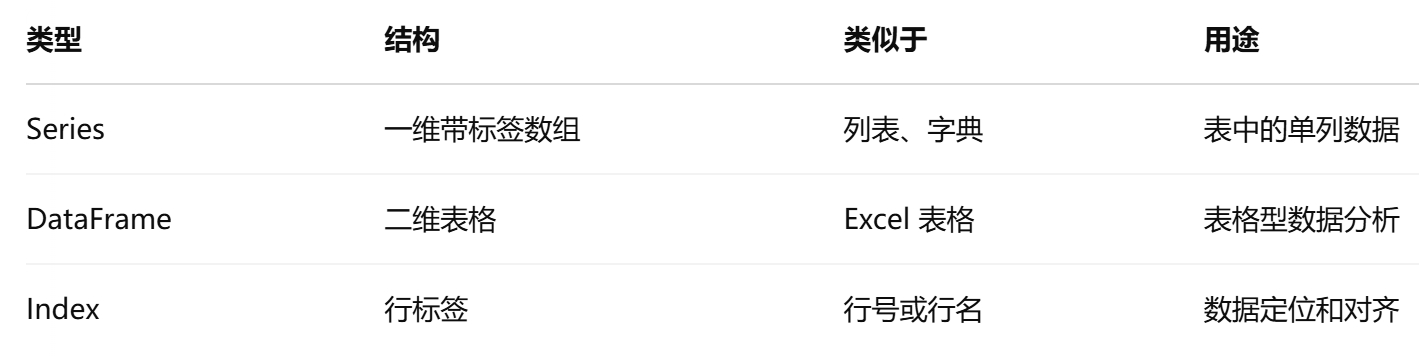
1.表头、形状、列名、数据类型
(1)查看前几行/后几行
df.head(n=5) # 默认查看前 5 行
df.tail(n=5) # 查看后 5 行
#示例
df.head()
#输出
# 产品 类别 销量 单价
#0 A 食品 30 5.5
#1 B 饮料 45 3.0
#2 C 食品 20 4.0
#...
用途:快速浏览数据长相、字段名是否正确、有没有乱码
(2)查看表格大小(几行几列)
df.shape
#输出
#(1000, 5) # 表示 1000 行 5 列
用途:了解数据规模(数据量大小是否适合建模?内存是否能承受?)
(3)查看列名
df.columns
#输出
#Index(['产品', '类别', '销量', '单价', '日期'], dtype='object')
用途:查看字段名,有助于后续选列、重命名、清洗
(4)查看每列的数据类型
df.dtypes
#输出
#产品 object
#类别 object
#销量 int64
#单价 float64
#日期 datetime64[ns]
#dtype: object
用途:判断列是否能参与数学运算;如果出现 object 类型的数字列,可能需要转换
| 类型 | 含义 | 示例 |
| object | 字符串 | “苹果”,“A类” |
| int64 | 整数 | 1,45 |
| float64 | 小数 | 3.14, 100.5 |
| datetime64 | 日期时间 | 2023-01-01 |
| bool | 布尔值 | True, False |
(5)更详细的结构信息:info()
df.info()
#输出
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000 entries, 0 to 999
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 产品 1000 non-null object
1 类别 1000 non-null object
2 销量 998 non-null int64
3 单价 1000 non-null float64
4 日期 999 non-null datetime64[ns]
用途:同时查看:每列缺不缺值(non-null),数据类型,总共有多少列和多少行
2.描述统计、缺失值概况
(1)描述性统计信息:describe() (默认只分析数值列)
df.describe()
#输出
销量 单价
count 998.000000 1000.000000
mean 34.567890 5.432100
std 10.123456 1.234567
min 10.000000 2.500000
25% 27.000000 4.500000
50% 35.000000 5.500000
75% 42.000000 6.300000
max 60.000000 8.000000
#用于统计字符串列
df.describe(include='object')
用途:快速了解分布(均值、中位数、最大值等),判断是否有异常值或离群点
(2)查看缺失值(是否有缺失?有多少?)
a.每列的缺失值个数
df.isnull().sum()
#输出
产品 0
类别 0
销量 2
单价 0
日期 1
b.缺失值占比
df.isnull().mean().round(3) * 100
#输出
产品 0.0
类别 0.0
销量 0.2
单价 0.0
日期 0.1
本章小结:
五.数据选择与筛选
在 Pandas 中,“数据选择与筛选”就像从一张大桌子上挑出你想看的数据。
1.按列选取、切片
(1)选择单列(Series)和选择多列
df['列名']
#示例
df['销量']
#输出
0 100
1 120
2 80
...
#示例
df[['列1', '列2']]
df[['产品', '销量']]
(2)行切片(根据位置)
df[起始索引:结束索引]
#示例
df[0:5] # 前 5 行
注:和 Python 切片一样,包含起始、不包含结束
2.条件筛选(布尔索引)
布尔筛选 = "我要选出满足条件的数据"
#语法形式
df[ df['列名'] 条件 ]
#示例
df[df['销量'] > 100]
#多条件筛选
df[ (df['销量'] > 100) & (df['单价'] < 10) ]
3.loc 和 iloc 的用法对比
| 方法 | 说明 | 索引方式 | 是否包含末尾 | 推荐用途 |
| loc[] | 按标签/名称取 | 行标签、列名 | 包含末尾 | 推荐用于明确名称 |
| iloc[] | 按 位置 取 | 行号、列号 | 不包含末尾 | 推荐用于数字索引 |
df.loc[0:3, ['产品', '销量']]
#取第0-3行(包含3),只取‘产品’和‘销量’这两列df.iloc[0:3, 0:2]
#0:3 表示取第 0、1、2 行(不包含第 3 行)
#0:2 表示取第 0、1 列(不包含第 2 列)4.使用 query() 语法(可选)
query() 是一种 SQL 风格的筛选写法,更自然、代码更短。
df.query("销量 > 100 and 单价 < 10")
#等价于
df[(df['销量'] > 100) & (df['单价'] < 10)]
示例展示:
| 产品 | 类别 | 销量 | 单价 |
| A | 食品 | 100 | 5.5 |
| B | 饮料 | 200 | 3.0 |
| C | 食品 | 80 | 6.5 |
示例 1:选择“产品”和“销量”列的前两行
df[['产品', '销量']].head(2)
示例 2:筛选“销量大于100”的产品
df[df['销量'] > 100]
示例 3:使用 .loc[] 精准选取
df.loc[1:2, ['产品', '单价']]
示例 4:用 query() 筛选“饮料类且单价<4”的产品
示例 4:用 query() 筛选“饮料类且单价<4”的产品本章小结:

六.数据清洗与处理
数据清洗是数据分析中最关键的一步,没有干净整齐的数据,后续分析都是“空中楼阁”。
1.缺失值处理(isnull, dropna, fillna)
(1)检查缺失值:isnull()、isna()
df.isnull() # 返回布尔矩阵,缺失为 True
df.isnull().sum() # 查看每列有多少缺失值
(2)删除缺失值:dropna()
df.dropna() # 删除所有含缺失值的行
df.dropna(axis=1) # 删除含缺失值的列
可选参数:how='any'(默认):只要一行中有缺失就删;how='all':整行全是缺失才删;subset=['列1', '列2']:只检查部分列。
(3)填充缺失值:fillna()
df.fillna(0) # 缺失值填 0
df['列'].fillna(df['列'].mean()) # 用均值填充
df.fillna(method='ffill') # 前向填充
df.fillna(method='bfill') # 后向填充
2.重命名列名、替换值
(1)重命名列名:rename()
df.rename(columns={'旧列名': '新列名'}, inplace=True)
#示例
df.rename(columns={'Product': '产品', 'Sales': '销量'})
(2)替换数据值:replace()
df['列名'].replace({'旧值1': '新值1', '旧值2': '新值2'})
#示例
df['等级'].replace({'A': '优秀', 'B': '良好'})
3.删除列、行
(1)删除列
df.drop(['列1', '列2'], axis=1, inplace=True)
(2)删除行
df.drop([0, 1], axis=0, inplace=True) # 删除第 0 和 1 行
注:axis=0 表示行,axis=1 表示列
inplace=True 表示直接修改原数据,否则要重新赋值
4.数据类型转换(astype)
数据类型不一致会导致很多分析或模型报错
df['列名'] = df['列名'].astype(int) # 转换为整数
df['列名'] = df['列名'].astype(float) # 转为浮点数
df['列名'] = df['列名'].astype(str) # 转为字符串
df['时间列'] = pd.to_datetime(df['时间列']) # 转为时间格式
5.去重与排序
(1)去重:drop_duplicates()
df.drop_duplicates() # 默认按所有列判断是否重复
df.drop_duplicates(subset='列名', keep='first')
参数说明:subset: 指定列判断重复;keep='first':保留第一个;keep='last':保留最后一个;keep=False:全部去除
(2)排序:sort_values()
df.sort_values(by='列名', ascending=True)
df.sort_values(by=['列1', '列2'], ascending=[True, False])
参数说明:by:要排序的列名或列名列表;ascending:是否升序,布尔值或布尔列表
(3)按索引排序:sort_index()
df.sort_index()
(4)示例:处理销售数据表
# 缺失值处理
df['销量'] = df['销量'].fillna(df['销量'].mean())
# 重命名列
df.rename(columns={'Product': '产品'}, inplace=True)
# 删除无用列
df.drop('备注', axis=1, inplace=True)
# 类型转换
df['销量'] = df['销量'].astype(int)
# 去重
df.drop_duplicates(subset='产品', keep='first', inplace=True)
# 排序
df.sort_values(by='销量', ascending=False, inplace=True)
本章小结:

七.数据统计与分析
1.基本统计方法
(1)describe():快速概览数值型数据统计特征
它返回:计数、均值、标准差、最小值、四分位数、最大值
df.describe()
#示例
df = pd.DataFrame({
'销售额': [120, 250, 300, 400, 150],
'利润': [10, 50, 60, 80, 30]
})
df.describe()
#输出
| 销售额 | 利润
count | 5.0 | 5.0
mean | 244.0 | 46.0
std | ... | ...
min | 120.0 | 10.0
25% | ... | ...
50% | ... | ...
75% | ... | ...
max | 400.0 | 80.0(2)value_counts():统计某列中各个值出现的频次(用于分类数据)
df['类别'].value_counts()
#示例
df = pd.DataFrame({'产品': ['A', 'A', 'B', 'B', 'C', 'A']})
df['产品'].value_counts()
#输出
A 3
B 2
C 1
2.groupby 分组聚合
groupby() 是分析中非常常用的方法,相当于 Excel 中的“按某列分类,然后汇总”。
df.groupby('列名').mean()
它的作用是:将数据按某列的值分组,然后对其他数值列自动求平均值(或你指定的聚合函数)。
df = pd.DataFrame({
'城市': ['北京', '北京', '上海', '上海', '广州'],
'销售额': [300, 200, 400, 350, 150]
})
df.groupby('城市').sum()
#输出
销售额
城市
北京 500
上海 750
广州 150
.mean():求均值;.max():求最大值;.min():求最小值;.count():计数;.size():分组的大小(每组多少条)
3.多重聚合(agg)
当你想对每列使用不同的聚合方式,就用 agg() 方法。
基本语法:
df.groupby('分组列').agg({
'销售额': ['mean', 'sum'],
'利润': ['max', 'min']
})
#示例
df = pd.DataFrame({
'部门': ['A', 'A', 'B', 'B', 'B'],
'销售额': [100, 200, 300, 400, 500],
'利润': [10, 20, 30, 40, 50]
})
df.groupby('部门').agg({
'销售额': ['sum', 'mean'],
'利润': ['max', 'min']
})
输出为:

4.透视表(pivot_table())
pivot_table() 是更高级、灵活的分组统计方式,可以对多维数据进行聚合分析。
pd.pivot_table(df, index='行', columns='列', values='数值列', aggfunc='sum')
参数说明:index:表示行索引;columns:表示列分类;values:需要聚合的数据列;aggfunc:聚合函数(如 'sum', 'mean', 'count')
df = pd.DataFrame({
'城市': ['北京', '北京', '上海', '上海', '广州'],
'年份': [2022, 2023, 2022, 2023, 2022],
'销售额': [300, 200, 400, 350, 150]
})
pd.pivot_table(df, index='城市', columns='年份', values='销售额', aggfunc='sum')
输出:

本节小结:

八.函数应用与变换
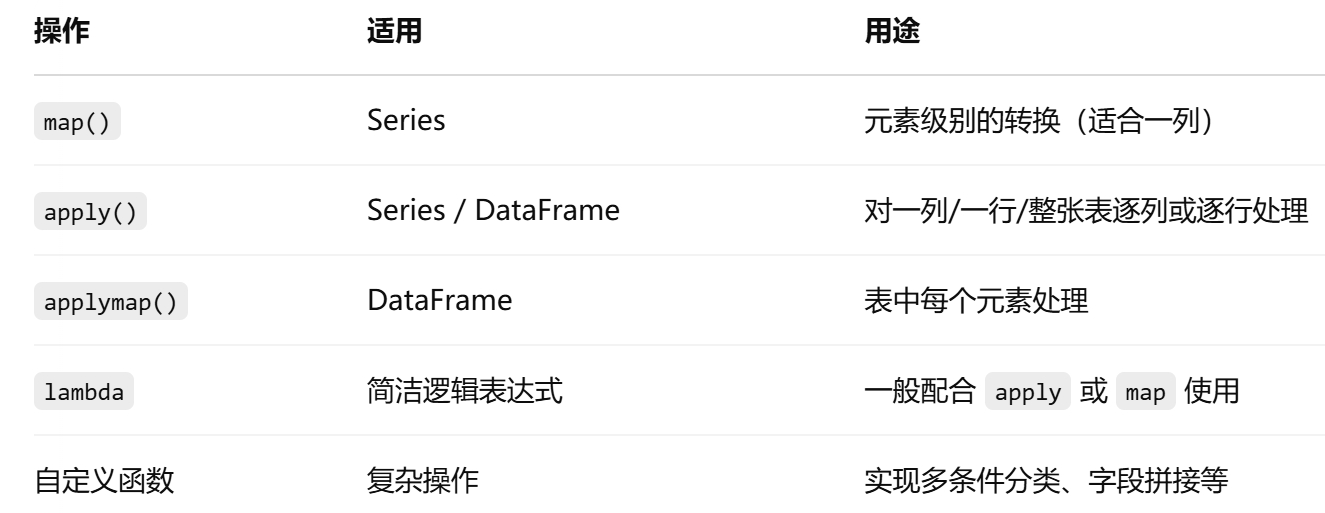
1.apply / map / applymap 区别
这三个函数看起来相似,但用法和应用场景不同,总结如下:
| 方法名 | 作用对象 | 用法 | 作用 |
|---|---|---|---|
| map() | Series(一列) | series.map(func) | 逐个元素映射 |
| apply() | Series 或 DataFrame | series.apply(func) / df.apply(func, axis=1/0) |
对每个元素(或行/列)整体应用函数 |
| applymap() | 仅限 DataFrame | df.applymap(func) | 对整张表的每个单元格应用函数 |
(1)map() 示例:适合一列数据元素的转换
s = pd.Series([1, 2, 3])
s.map(lambda x: x**2)
#输出
0 1
1 4
2 9
dtype: int64
(2)apply() 示例:既可用于 Series,也可用于 DataFrame
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6]
})
# 对列求最大值(列操作,axis=0)
df.apply(np.max, axis=0)
#输出
A 3
B 6
dtype: int64
(3)applymap() 示例:DataFrame 每个元素都处理(只适合 DataFrame)
df.applymap(lambda x: x**2)
#输出
A B
0 1 16
1 4 25
2 9 36
2.使用 lambda 函数
lambda 是 Python 的匿名函数,用于编写简单逻辑处理函数,非常适合 apply()、map() 搭配使用。
#语法格式
lambda 参数: 返回值表达式
#示例
# 把一列中的值是否为奇数转为布尔值
df = pd.DataFrame({
'A': [1, 2, 3]
})
df['A'].apply(lambda x: x % 2 == 1)
#输出
0 True
1 False
2 True
Name: A, dtype: bool
3.自定义函数批量处理数据
(1)当你的处理逻辑复杂时,用 lambda 就不够了,此时你可以定义一个函数,然后用 apply 来调用它。
def classify_score(x):
if x >= 90:
return '优秀'
elif x >= 60:
return '及格'
else:
return '不及格'
df['成绩分类'] = df['成绩'].apply(classify_score)
这样我们就给“成绩”列加了一个“分类”列,非常适合批量数据标签化、规则判断等。
(2)对每行应用自定义函数(axis=1)
def combine_name(row):
return row['姓'] + row['名']
df['全名'] = df.apply(combine_name, axis=1)
本节小结:
九.数据合并与连接
1.concat 横向 / 纵向拼接
(1)功能:把两个或多个 DataFrame 直接拼接在一起(按行 / 按列)
(2)语法结构:
pd.concat(objs, axis=0, join='outer', ignore_index=False)
参数解释:objs:一组 DataFrame 或 Series,组成列表;axis=0:按行拼接(默认),相当于“上下叠加”;axis=1:按列拼接,相当于“左右并排”;ignore_index=True:重建索引;join='outer':默认并集(保留所有列),'inner' 为交集
(3)示例:
#示例 1:纵向拼接(axis=0)
import pandas as pd
df1 = pd.DataFrame({'A': [1, 2], 'B': [3, 4]})
df2 = pd.DataFrame({'A': [5, 6], 'B': [7, 8]})
pd.concat([df1, df2], axis=0, ignore_index=True)
#输出
A B
0 1 3
1 2 4
2 5 7
3 6 8
# 示例 2:横向拼接(axis=1)
pd.concat([df1, df2], axis=1)
#输出
A B A B
0 1 3 5 7
1 2 4 6 8
注意:没有自动对列名做区分,可以手动加上 keys 参数生成多层列名。
2.merge 类似 SQL 的连接
(1)功能:基于一列(或多列)相同的字段,将两个 DataFrame 像 SQL一样合并
(2)语法结构:
pd.merge(left, right, how='inner', on=None)
参数解释:left, right:要合并的两个 DataFrame;how:连接方式,有('inner':交集(默认);'outer':并集;'left':以左表为主;'right':以右表为主);on:指定用作连接的列名
(3)示例:
df1 = pd.DataFrame({'ID': [1, 2, 3], 'Name': ['张三', '李四', '王五']})
df2 = pd.DataFrame({'ID': [1, 2, 4], 'Score': [90, 85, 88]})
pd.merge(df1, df2, on='ID', how='inner')
#输出
ID Name Score
0 1 张三 90
1 2 李四 85
只保留了 ID 相同的数据行(ID=3、4 被丢弃)
| 连接方式 | 结果说明 |
| inner | 两边都有的保留 |
| outer | 所有数据保留,缺失用 NaN 补 |
| left | 保留左边全部,右边能对上就对上 |
| right | 保留右边全部,左边能对上就对上 |
3.join(以索引为键的合并)
(1)功能:以索引为主键,将两个 DataFrame 合并
(2)语法结构:
df1.join(df2, how='left', on=None)
用法说明:只适用于 DataFrame 合并;默认以左表索引为键,右表的索引或指定列来连接
(3)示例
df1 = pd.DataFrame({'A': [1, 2, 3]}, index=['x', 'y', 'z'])
df2 = pd.DataFrame({'B': [4, 5]}, index=['x', 'y'])
df1.join(df2, how='left')
#输出
A B
x 1 4.0
y 2 5.0
z 3 NaN
本节小结:

十.附录
1.时间序列处理(to_datetime, resample)
时间序列数据在金融、传感器、气象、日志等场景中非常常见。Pandas 提供了一整套强大的时间处理工具。
(1)pd.to_datetime():将字符串或数字转换为时间格式
import pandas as pd
# 示例 1:基本用法
df = pd.DataFrame({'date': ['2024-01-01', '2024-01-02', '2024-01-03']})
df['date'] = pd.to_datetime(df['date'])
# 示例 2:带时间格式的转换
pd.to_datetime('20240101', format='%Y%m%d') # 输出:2024-01-01 00:00:00
转换后这一列就变成了 datetime64[ns] 类型,可以进行时间索引、提取年月日、时间差等操作。
(2)时间列的操作
df['year'] = df['date'].dt.year
df['month'] = df['date'].dt.month
df['weekday'] = df['date'].dt.weekday # 周一是0
(3)resample():对时间索引进行重采样(类似于 groupby)
df = pd.DataFrame({
'date': pd.date_range('2024-01-01', periods=10, freq='D'),
'value': range(10)
}).set_index('date')
df.resample('3D').sum()
resample('3D') 表示每3天为一组,求和(或均值、最大值等)
常用频率参数:

2.常见报错总结
以下是初学者最常遇到的 Pandas 报错:
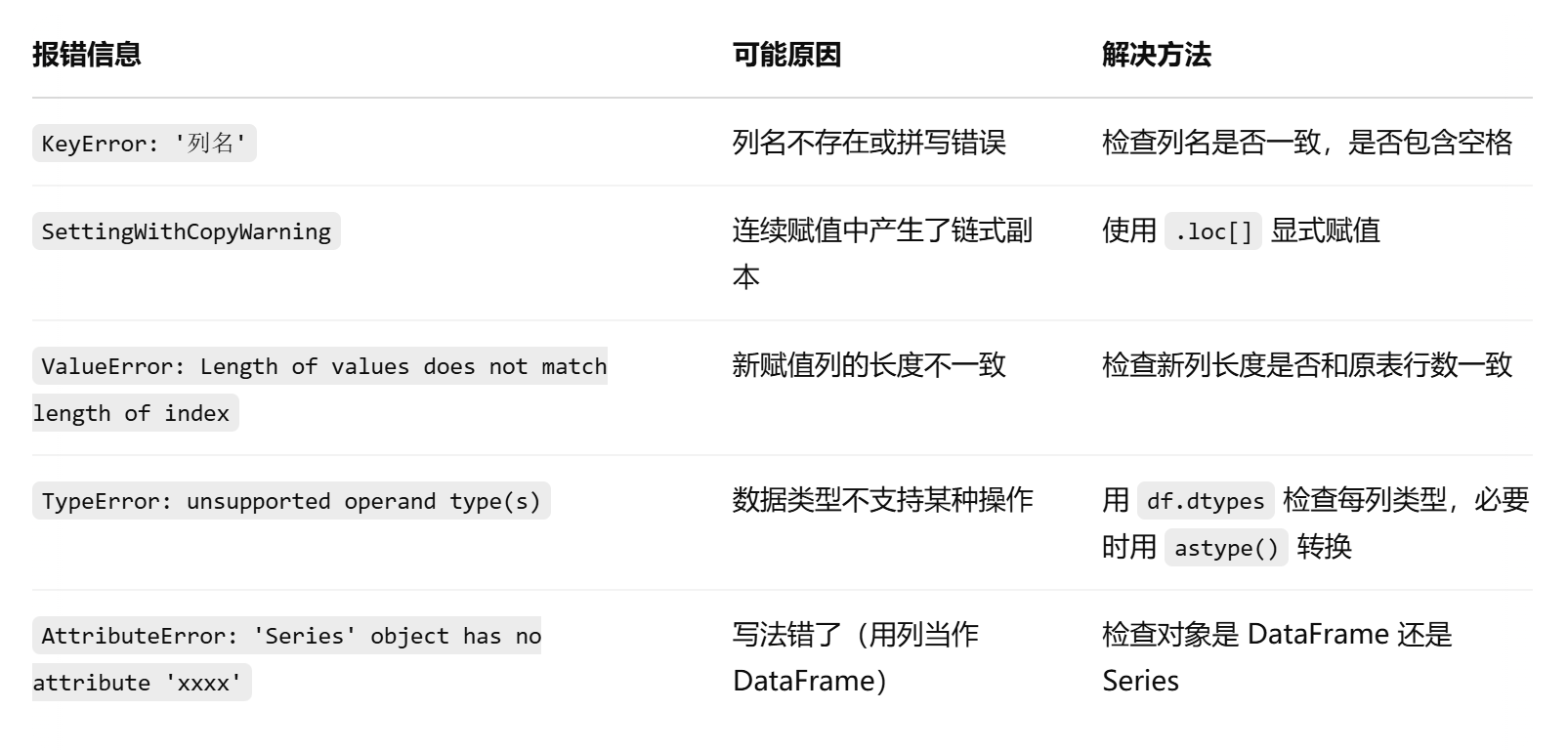
# 错误方式(可能产生 SettingWithCopyWarning)
df[df['age'] > 18]['name'] = '成人'
# 正确方式(使用 loc)
df.loc[df['age'] > 18, 'name'] = '成人'
3.高频函数速查表
这张表可以作为你做分析或写代码时的随手备查表:
| 类别 | 函数 | 功能 |
| 读取/写入 | read_csv() / to_csv() |
读写 CSV 文件 |
| 概览 | head() / info() / describe() |
查看数据结构和统计信息 |
| 选择 | loc[] / iloc[] |
位置或标签选取 |
| 过滤 | df[df['列'] > x] | 条件筛选行 |
| 缺失值 | isna() / fillna() / dropna() |
缺失值检测与处理 |
| 分组 | groupby() / agg() |
分组聚合操作 |
| 排序 | sort_values() | 按列排序 |
| 去重 | drop_duplicates() | 删除重复行 |
| 合并 | concat() / merge() / join() |
多表拼接 |
| 时间处理 | to_datetime() / resample() |
时间字段处理 |
| 应用函数 | apply() / map() / lambda |
对列或行进行处理 |
| 数据类型 | astype() | 类型转换 |
| 行列 | shape / columns / index |
获取维度和标签信息 |

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 19
19 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)