南京大学高阳团队 | 具身智能体中因果行动赋权的高效强化学习
不管是奖励密集的任务,还是奖励稀疏的任务,CAE都能更快地学会怎么做,而且成功率更高。本文旨在赋予智能体类似人类的因果推理能力,通过挖掘状态、行动与奖励间的因果关系,减少无效探索,显著提升学习效率,为智能体在真实复杂环境中的应用提供新思路。CAE的工作原理就像是给机器人配了一个“智能过滤器”:它先分析哪些状态是机器人能控制的(比如手臂的位置),哪些是无关的(比如旁边风吹的声音),然后根据任务奖励(
南京大学高阳团队 | 具身智能体中因果行动赋权的高效强化学习
原创 SCIS 中国科学信息科学 2025年04月27日 12:01 北京


研究团队
曹宏业, 霍静, 高阳:南京大学
冯帆:香港城市大学

研究意义
在机器人、自动驾驶等具身智能体的开发中,强化学习(RL)因其试错学习能力被广泛应用。然而,传统强化学习方法存在两大瓶颈:一是忽视状态与行动间的因果关系,导致探索效率低下;二是面对复杂环境时(如高维状态、稀疏奖励),需要海量交互数据,成本高昂。例如,机器人抓取篮球时,若错误关联无关状态,可能导致反复失败。人类却能通过因果推理快速抓住关键因素(如篮球位置、抓握时机)。本文旨在赋予智能体类似人类的因果推理能力,通过挖掘状态、行动与奖励间的因果关系,减少无效探索,显著提升学习效率,为智能体在真实复杂环境中的应用提供新思路。

本文工作
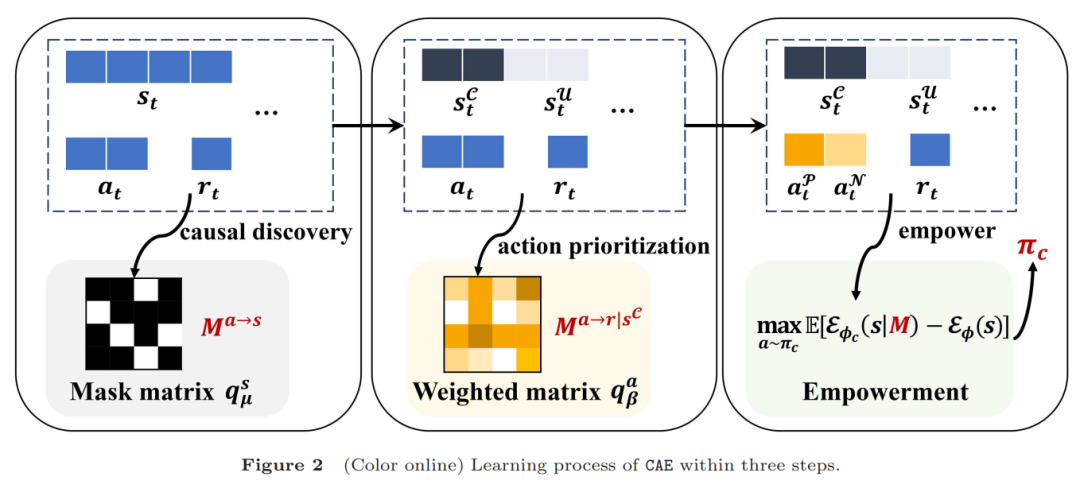
为了解决强化学习效率低的问题,本文提出了一个新方法:因果动作赋能(Causal Action Empowerment, CAE)。简单来说,这个方法让机器人不再盲目试错,而是学会找到哪些状态和动作真正对任务结果有因果关系,然后重点关注这些关键点。CAE的工作原理就像是给机器人配了一个“智能过滤器”:它先分析哪些状态是机器人能控制的(比如手臂的位置),哪些是无关的(比如旁边风吹的声音),然后根据任务奖励(比如是否投篮成功)重新调整机器人的动作优先级,最后通过一种“赋能”机制鼓励机器人多尝试那些能带来大影响的动作。
本文的创新点如下:
(1) 因果关系挖掘:传统方法不关心动作和结果之间的因果联系,而CAE能找出哪些动作对任务有用,减少无效探索。
(2) 奖励引导行动优先:通过奖励引导和因果分析,CAE让机器人优先尝试那些“高回报”的动作,同时提高它对环境的控制能力。
(3) 广泛验证效果:作者在25个不同任务中测试了CAE,比如让机器人手臂抓东西、让虚拟角色跑跳等,结果证明它在各种情况下都能比传统方法学得更快、更稳定。
实验结果
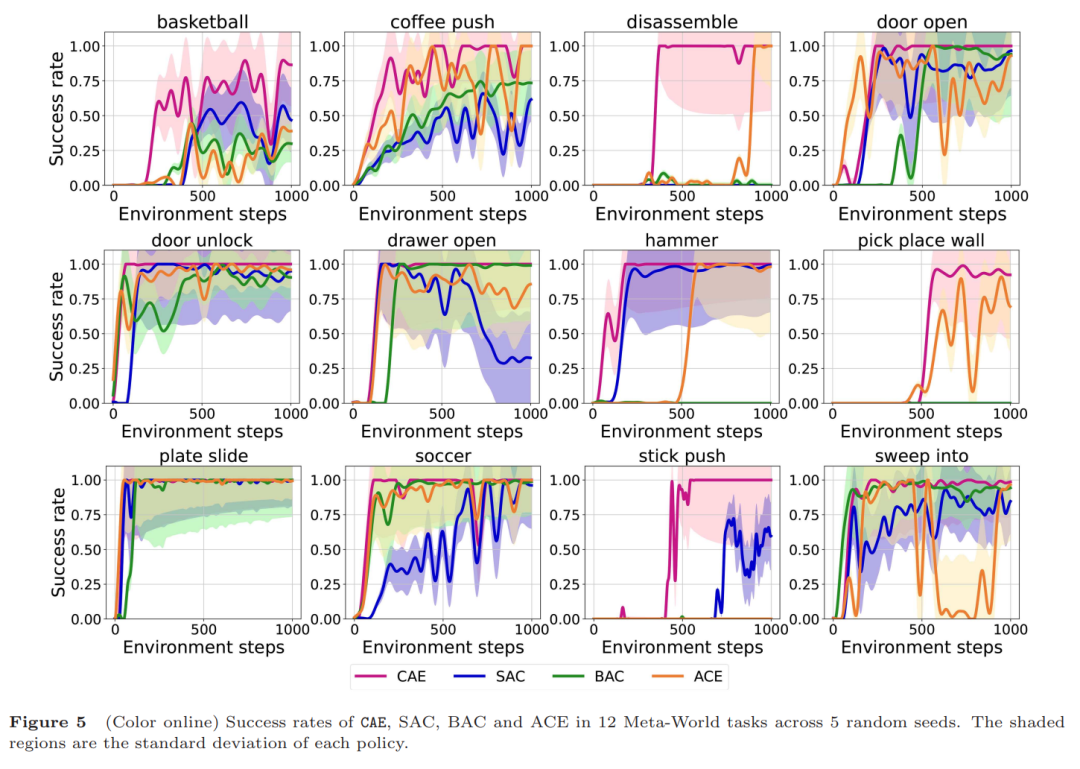
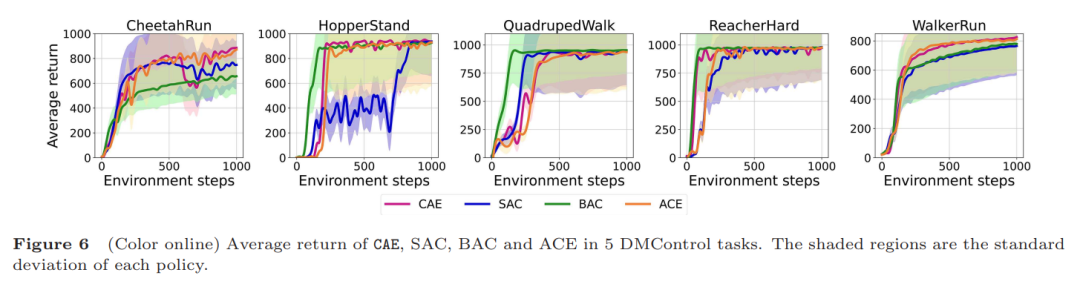
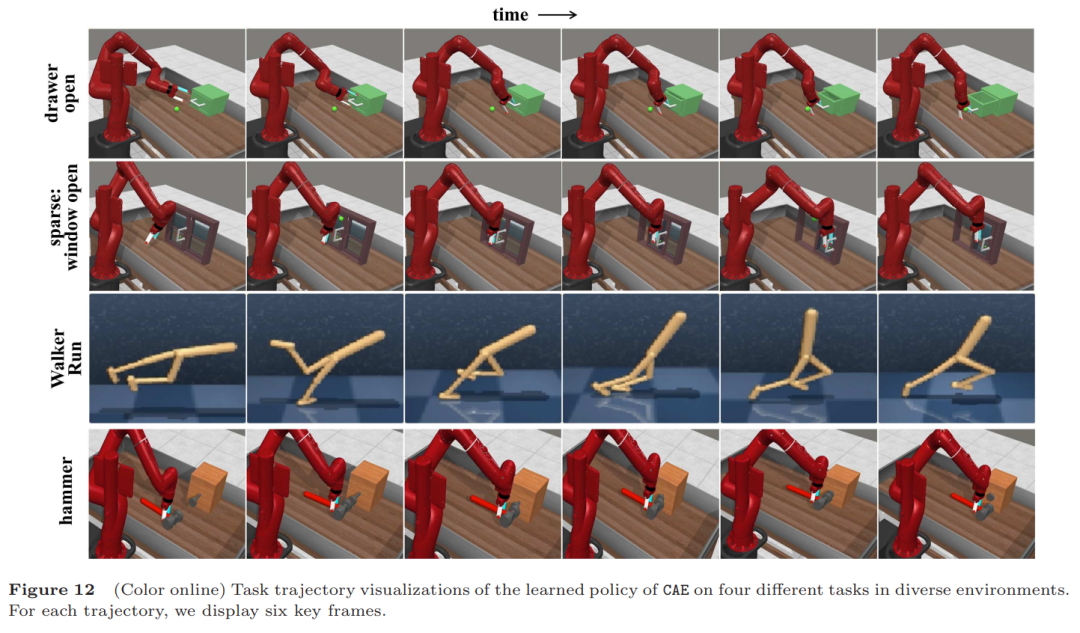
为了验证CAE的效果,作者在5种不同的模拟环境中做了大量实验,总共涵盖25个任务。这些任务既有简单的(比如移动物体),也有复杂的(比如让虚拟角色完成跑步或跳跃)。他们把CAE跟其他强化学习方法(比如SAC、ACE等)做了对比,结果显示CAE的表现更出色。不管是奖励密集的任务,还是奖励稀疏的任务,CAE都能更快地学会怎么做,而且成功率更高。比如在投篮任务中,CAE能更快找到正确的投篮姿势;在跑步任务中,它能让虚拟角色更快学会平稳奔跑。实验中还发现, CAE对参数变化鲁棒,且在多任务学习中(如MT10)成功率比传统方法提高10%以上,展现强适应性。实验表明,CAE通过因果推理与赋权机制,显著降低样本需求,为复杂场景下的智能体学习提供高效解决方案。

相关阅读
王耀南院士团队 | AI大模型驱动的具身智能人形机器人技术与展望

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 18
18 0
0- 0



 已为社区贡献80条内容
已为社区贡献80条内容

所有评论(0)