常见的 OCT 眼底疾病数据集(OCT2017、Eye OCT Datasets、OCTDL、RetinalOCT_Dataset-C8、RETOUCH和OCTA-500)
本文旨在介绍几个常用的OCT数据集,包括OCT2017、Eye OCT Datasets、OCTDL、RetinalOCT_Dataset-C8、RETOUCH和OCTA-500,分析它们的特点、用途和适用场景,为研究人员在选择合适的数据集时提供参考。:该数据集包含500只眼睛的OCT和OCTA两种模态的三维数据,六种投影图像,四种文本标签(年龄、性别、左右眼、疾病类型)以及两种分割标签(视网膜大
文章目录
前言
随着医学影像技术的快速发展,光学相干断层扫描(OCT)已成为眼科疾病诊断的重要工具。OCT技术通过高分辨率的断层成像,能够清晰地显示视网膜结构,为医生提供精确的病变信息。然而,手动分析OCT图像耗时耗力,且对医生的专业知识要求较高。因此,基于深度学习的自动化OCT图像分析方法应运而生,旨在提高诊断效率和准确性。
为了推动这一领域的研究与应用,多个公开的OCT数据集被发布,涵盖了不同疾病类型、不同扫描设备和不同分辨率的OCT图像。这些数据集为研究人员提供了丰富的实验资源,促进了基于深度学习的OCT图像分类、分割和疾病诊断技术的发展。
本文旨在介绍几个常用的OCT数据集,包括OCT2017、Eye OCT Datasets、OCTDL、RetinalOCT_Dataset-C8、RETOUCH和OCTA-500,分析它们的特点、用途和适用场景,为研究人员在选择合适的数据集时提供参考。
一、数据集介绍
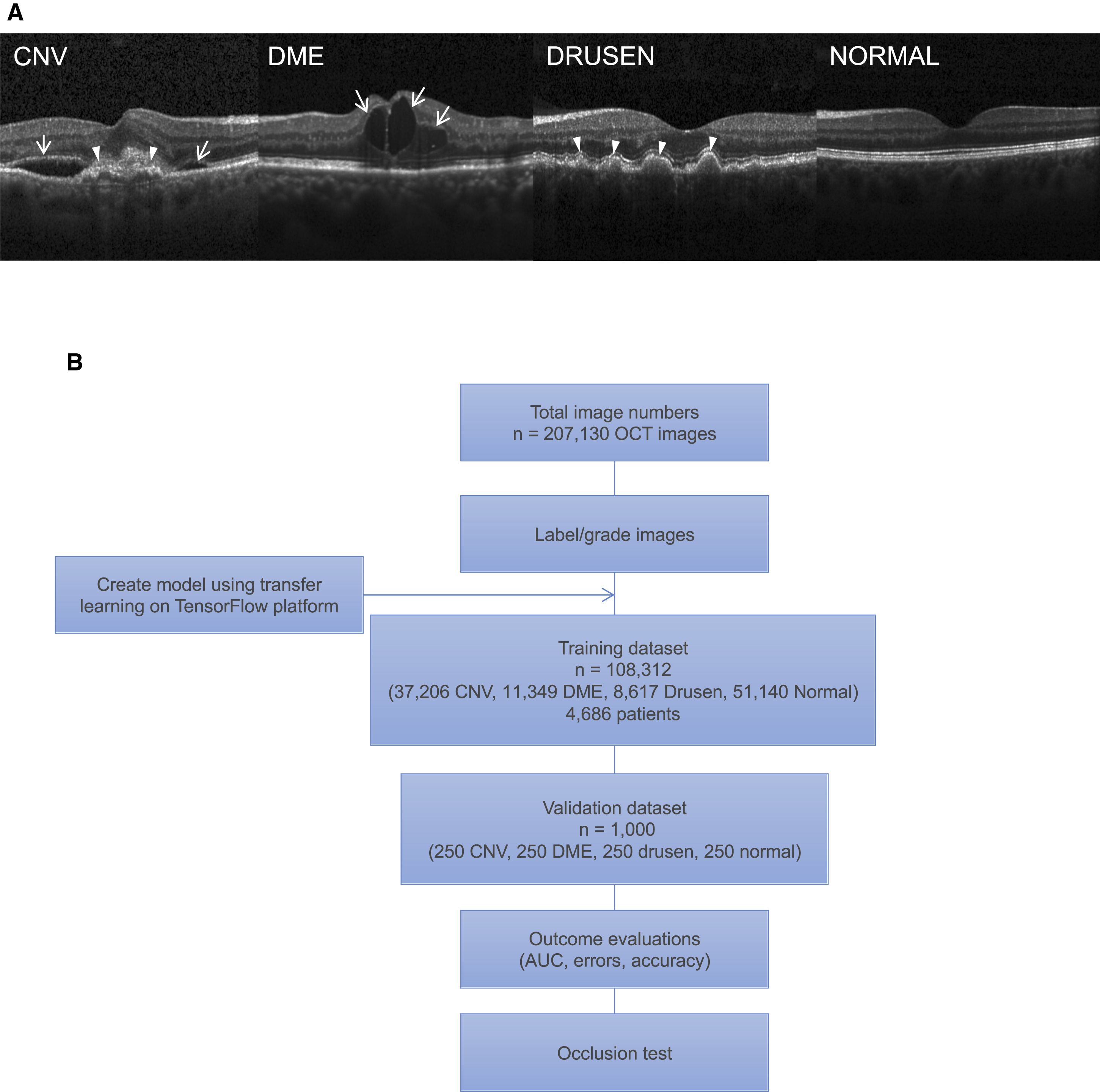
1.OCT2017 眼部疾病分类数据集
样本数量:108,312
检测部位:眼部(眼底)、胸部
疾病类型:脉络膜新生血管(CNV)、糖尿病性黄斑水肿(DME)、玻璃膜疣(DRUSEN)、正常(NORMAL)等
用途:视网膜病变相关模型的训练与测试
特点:
- 数据规模大,适合大规模深度学习训练。
- 包含多部位数据(眼部+胸部X线图像),但胸部数据可能对OCT视网膜疾病分类任务干扰较大,需注意数据筛选。
- 疾病类型覆盖常见视网膜病变,适合构建通用分类模型。
数据集情况:
数据集分为 3 个文件夹(train、test、val),并包含每个图像类别(NORMAL、CNV、DME、DRUSEN)的子文件夹。有 84,495 张 X 射线图像 (JPEG) 和 4 个类别(NORMAL、CNV、DME、DRUSEN)。
图像被标记为 (疾病)-(随机患者 ID)-(该患者的图像编号)并分为 4 个目录:CNV、DME、DRUSEN 和 NORMAL。
2.Eye OCT Datasets 眼部 OCT 数据集
样本数量:
- 正常:50例
- 干性年龄相关性黄斑变性(AMD):48例
- 糖尿病性黄斑水肿(DME):50例
扫描参数:
- 轴向分辨率:3.5μm
- 扫描尺寸:8.9×7.4mm²
- A扫描数量:512或768
- B扫描数量:每体积19、25、31或61
用途:视网膜OCT图像分析、病变分割与分类
特点:
- 数据来自真实临床场景,分辨率高,适合精细病变分割任务。
- 样本量较小,可能需结合数据增强技术(如旋转、平移)提升模型泛化能力。
- 包含干性AMD等罕见病数据,适合研究特定疾病分类。
数据集情况:
带有眼底图像的OCT数据集的集合,可进行各种分析和后处理步骤的实验。该数据集是从德黑兰的Noor Eye Hospital获得的,由50个正常,48个干性AMD和50个DME OCT组成。

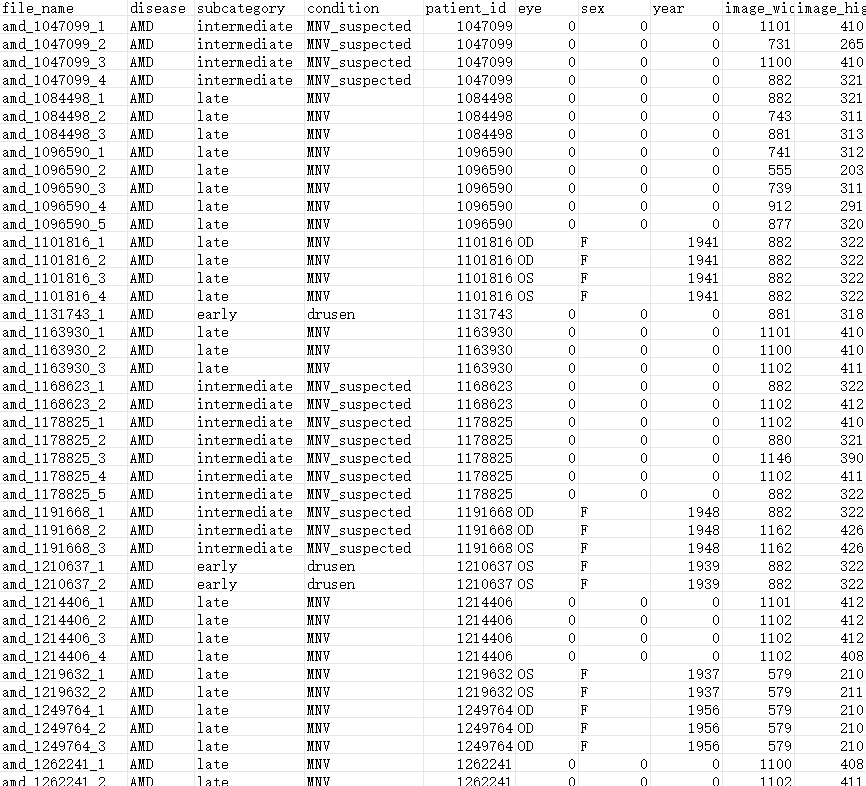
3.OCTDL 视网膜 OCT 图像数据集
样本数量:2000张
疾病类别:
- 年龄相关性黄斑变性(AMD):1231张
- 糖尿病性黄斑水肿(DME):147张
- 视网膜前膜:155张
- 正常:332张
- 视网膜动脉阻塞:22张
- 视网膜静脉阻塞:101张
- 玻璃体黄斑界面疾病:76张
用途:视网膜疾病分类与病理分析
特点:
- 疾病类别丰富,涵盖多种罕见病(如视网膜动脉阻塞),适合构建多分类模型。
- 样本量适中,适合中等规模深度学习任务。
- 数据标注清晰,适合直接用于分类任务。
数据集情况:
图像文件 (380 MB):包含 2000 多个常见图像格式的 OCT 图像,7大类数据。
OCTDL_metadata.csv (107 KB):一个 CSV 文件,其中包含每张图片的详细元数据,包括:
file_name:图像文件的名称。disease:原发疾病类别。subcategory:更具体的子分类(如果适用)。condition:与疾病相关的特定情况。patient_id:患者的唯一标识符。eye:指示是左眼还是右眼。sex:患者的性别。year:拍摄图像的年份。image_width:图像的宽度(以像素为单位)。image_height:图像的高度(以像素为单位)。

CSV文件标签
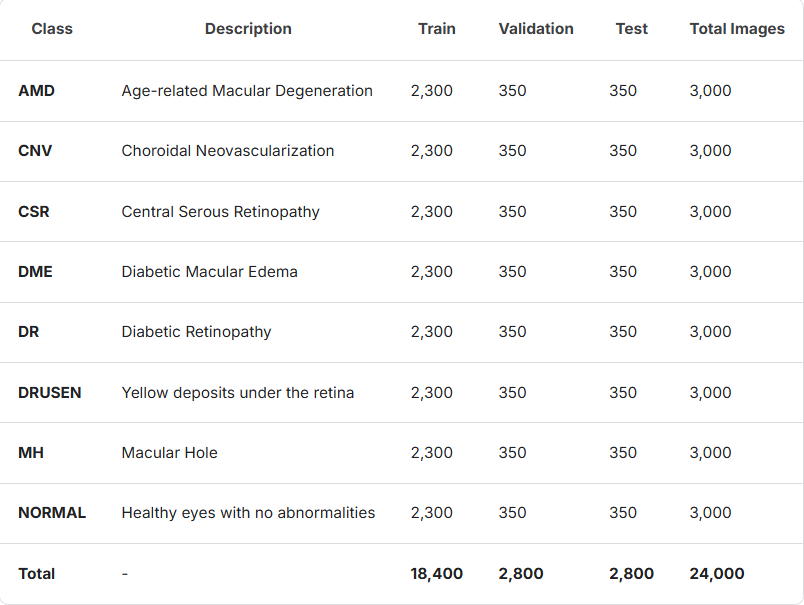
4.RetinalOCT_Dataset - C8数据集
数据集包含 24,000 张高质量的视网膜 OCT 图像,分为 8 个视网膜疾病类别。它旨在支持使用机器学习和深度学习技术进行视网膜疾病分类的研究和模型训练。
数据集情况:
数据集分为 8 个类,每个类代表一种特定的视网膜状况。以下是每个类的详细信息,包括可用于训练、验证和测试的图像数量:
- 图像总数:24,000
- 格式:JPEG
- 尺寸:不同
每个文件夹都包含 8 个类的子文件夹,以及相应的图像。
- /train
-- /[类文件夹:AMD、CNV、CSR、DME、DR、DR、DRUSEN、MH、NORMAL] - /val
-- /[类文件夹:AMD、CNV、CSR、DME、DR、DR、DR DR、MH、NORMAL] - /test
-- /[类文件夹:AMD、CNV、CSR、DME、DR、DR、DRUSEN、MH、NORMAL]
5. RETOUCH 眼底疾病分类数据集(2019)
样本数量:12张3D-OCT图像
疾病类别:视网膜内液(IRF)、视网膜下液(SRF)和色素上皮脱离(PED)。
数据特点:
- 专注于视网膜液体检测与分割(如视。网膜内液体、视网膜下液体)。
- 包含多设备采集的3D OCT数据,适合跨设备模型训练
用途:视网膜液体分割与分类
特点:
- 适合需要精细分割的任务(如液体区域定位)。
- 数据复杂度高,需结合3D卷积网络处理。
数据集情况:
图像像素
- 设备 Cirrus:512 * 1024 * 128 * 24
- 设备 Spectralis:512 * 496 * 49 * 24
- 设备 Topcon:512 * 650 / 885 * 128 / 64 * 22
图像数据文件:oct.raw 和 oct.mhd
标签文件:reference.raw 和 reference.mhd
训练数据划分:
- 设备 Cirrus:volume 0 ~ 19 用于训练,共 2560 张;20 ~ 23 用于测试,共 512 张。
- 设备 Spectralis:volume 0 ~ 19 用于训练,共 980 张;20 ~ 23 用于测试,共 196 张。
- 设备 Topcon:volume 0 ~ 18 用于训练,共2304 张;19 ~ 21 用于测试,共 384 张。*注:volume 7 和 13 分别只有 64 张。
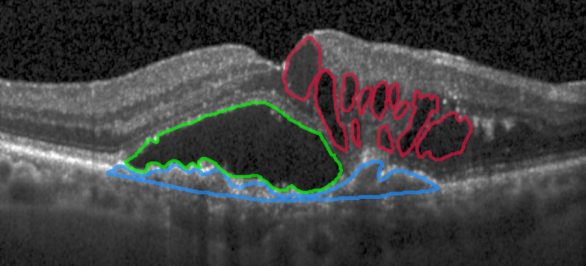
6. OCTA-500 眼底疾病分类数据集(2020)
数据特点:
- 包含500只眼睛的OCT和OCTA三维数据。
- 提供六种投影图像和七种分割标签(如大血管、毛细血管、FAZ区域等)。
用途:视网膜血管分割与疾病分类
特点:
- 适合需要血管分割的任务(如糖尿病视网膜病变)。
- 数据维度高,需结合3D或多模态网络处理。
- 数据集总大小约80GB,适用于多模态的图像和注释、文本标签和分割标签的研究
数据集情况:该数据集包含500只眼睛的OCT和OCTA两种模态的三维数据,六种投影图像,四种文本标签(年龄、性别、左右眼、疾病类型)以及两种分割标签(视网膜大血管、无血管区)。
二、数据集选择建议
大规模训练多分类训练:OCT2017、RetinalOCT_Dataset - C8
高分辨率分割:Eye OCT Datasets
多分类与罕见病:OCTDL
液体分割:RETOUCH
血管分割与分类:OCTA-500
三、总结
本文对六个常用的OCT数据集进行了详细介绍,包括OCT2017、Eye OCT Datasets、OCTDL、RetinalOCT_Dataset-C8、RETOUCH和OCTA-500。这些数据集在样本数量、疾病类型、数据特点和应用场景上各有侧重,为基于深度学习的OCT图像分析提供了丰富的实验资源。
-
OCT2017:数据规模大,适合大规模深度学习训练,涵盖常见视网膜病变类型,但包含部分胸部X线图像,需注意数据筛选。
-
Eye OCT Datasets:数据来自真实临床场景,分辨率高,适合精细病变分割任务,但样本量较小,需结合数据增强技术。
-
OCTDL:疾病类别丰富,涵盖多种罕见病,适合构建多分类模型,样本量适中,标注清晰。
-
RetinalOCT_Dataset-C8:包含24,000张高质量OCT图像,分为8个疾病类别,适合大规模多分类训练。
-
RETOUCH:专注于视网膜液体检测与分割,包含多设备采集的3D OCT数据,适合精细分割任务。
-
OCTA-500:包含500只眼睛的OCT和OCTA三维数据,提供多种分割标签,适合视网膜血管分割与疾病分类任务。
在选择数据集时,研究人员应根据具体的研究目标、任务需求和数据特点进行综合考虑。对于大规模训练和多分类任务,OCT2017和RetinalOCT_Dataset-C8是不错的选择;对于高分辨率分割任务,Eye OCT Datasets更为合适;对于多分类与罕见病研究,OCTDL提供了丰富的疾病类别;对于液体分割任务,RETOUCH提供了精细的标注;对于血管分割与分类任务,OCTA-500则提供了丰富的血管相关数据。
通过合理选择和使用这些数据集,研究人员可以加速基于深度学习的OCT图像分析技术的发展,为眼科疾病的早期诊断和治疗提供有力支持。
四、下载

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)