GaussDB 数据库表创建:通过 SQL 语句精细设计
GaussDB 是一款高性能分布式关系型数据库(兼容 PostgreSQL 协议),支持通过丰富的 SQL 语法定义数据表结构。本文将详细介绍如何通过 SQL 创建表,涵盖基础语法、高级约束、索引优化及 GaussDB 特有功能(如物化视图、分区表)。通过 SQL 语句在 GaussDB 中创建表是数据库设计的核心环节。结合 GaussDB 的分布式特性(如分区表、物化视图)和存储优化功能(列式存
GaussDB 数据库表创建:通过 SQL 语句精细设计
一、简介
GaussDB 是一款高性能分布式关系型数据库(兼容 PostgreSQL 协议),支持通过丰富的 SQL 语法定义数据表结构。本文将详细介绍如何通过 SQL 创建表,涵盖基础语法、高级约束、索引优化及 GaussDB 特有功能(如物化视图、分区表)。
二、基本语法
CREATE TABLE table_name (
column1 data_type [CONSTRAINT constraint_name],
column2 data_type [CONSTRAINT constraint_name],
...
)
[WITH (table_option = value, ...)]
[INHERITS (parent_table_name)] -- GaussDB 支持继承
[PARTITION BY partition_method (column)] -- 分区表定义
[DISTRIBUTE BY HASH(column) | RANGE(column)] -- GaussDB 分布式策略
[LAYOUT ON (COLUMNS (column1, column2))] -- 存储布局优化
);
三、详细步骤与示例
1. 创建基础表
**(1) 简单表结构**
-- 创建包含 ID 和名称的表
CREATE TABLE employees (
id SERIAL PRIMARY KEY,
name VARCHAR(50) NOT NULL,
age INT,
salary NUMERIC(10, 2),
created_at TIMESTAMPTZ DEFAULT CURRENT_TIMESTAMP
);
**(2) 显式指定字段类型长度**
-- 使用固定长度类型(如 CHAR)
CREATE TABLE users (
user_id INT PRIMARY KEY,
username CHAR(20) UNIQUE NOT NULL,
email VARCHAR(100)
);
2. 添加约束
**(1) 唯一性约束**
-- 在创建表时添加唯一索引
CREATE TABLE products (
product_id INT PRIMARY KEY,
sku CHAR(20) UNIQUE
);
-- 或单独创建唯一索引
CREATE UNIQUE INDEX idx_sku ON products (sku);
**(2) 外键约束**
-- 创建订单表并关联用户表
CREATE TABLE orders (
order_id SERIAL PRIMARY KEY,
user_id INT,
amount NUMERIC(10, 2),
FOREIGN KEY (user_id) REFERENCES users (id)
ON DELETE CASCADE -- 删除用户时自动删除订单
);
**(3) 检查约束**
-- 创建包含年龄限制的表
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(50),
age INT CHECK (age >= 18)
);
3. 高级表定义
**(1) 分区表**
-- 按月份分区销售数据表
CREATE TABLE sales (
sale_id INT PRIMARY KEY,
sale_date DATE,
amount NUMERIC(10, 2)
)
PARTITION BY RANGE (sale_date);
-- 创建子表(2023 年数据)
CREATE TABLE sales_2023 PARTITION OF sales
FOR VALUES FROM ('2023-01-01') TO ('2024-01-01');
**(2) 物化视图**
-- 创建物化视图聚合每日销售额
CREATE MATERIALIZED VIEW mv_daily_sales AS
SELECT
date_trunc('day', sale_date) AS day,
SUM(amount) AS total_sales
FROM sales
GROUP BY day;
**(3) GaussDB 分布式策略**
-- 按哈希值分布数据到计算节点
CREATE TABLE users_distributed (
user_id INT,
username VARCHAR(50)
)
DISTRIBUTE BY HASH(user_id); -- 默认策略
-- 按范围分布数据(适用于有序字段)
CREATE TABLE logs_distributed (
log_time TIMESTAMPTZ,
message TEXT
)
DISTRIBUTE BY RANGE(log_time);
四、高级功能与优化
1. 存储布局优化
**(1) 列式存储**
-- 使用列式表存储分析型数据
CREATE TABLE analytics_data (
event_time TIMESTAMPTZ,
user_id INT,
page_url VARCHAR(200),
COUNT(*) AS click_count
)
LAYOUT ON (COLUMNS (event_time, user_id)) -- 列式存储优化查询性能
DISTRIBUTE BY RANGE(event_time);
**(2) 压缩配置**
-- 创建压缩表(需 GaussDB 企业版支持)
CREATE TABLE large_data (
data BYTEA,
metadata JSONB
)
WITH (compression = 'zstd', toast_compression = 'lzham');
2. 性能调优
**(1) 索引优化**
-- 创建复合索引
CREATE INDEX idx_name_age ON employees (name, age);
-- 创建覆盖索引
CREATE INDEX idx_cover ON orders (user_id) INCLUDE (amount);
**(2) 数据倾斜优化**
-- 在 GaussDB 中自动平衡热点数据
ALTER TABLE users_distributed
REBALANCE PARTITION BY HASH(user_id);
五、常见问题与解决方案
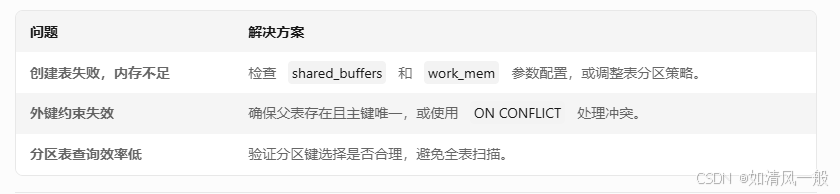
六、最佳实践
1. 设计原则
范式化 vs 反范式化:根据查询模式权衡数据冗余。
选择合适的数据类型:如用 TIMESTAMPZ 替代 TEXT 存储时间。
避免过度分区:过多子表会增加维护成本。
2. 监控与维护
定期重建索引:
REINDEX INDEX idx_name_age;
分析表统计信息:
ANALYZE employees;
3. 华为云 GaussDB 特性
使用 GaussDB Query Optimizer:自动优化查询计划。
开启 auto_explain:实时查看执行计划:
SET auto_explain = on;
SELECT * FROM large_table WHERE id > 1000;
七、总结
通过 SQL 语句在 GaussDB 中创建表是数据库设计的核心环节。结合 GaussDB 的分布式特性(如分区表、物化视图)和存储优化功能(列式存储、压缩),可以显著提升数据管理效率和查询性能。建议在实际项目中根据业务需求灵活运用高级语法,并通过监控工具(如 GaussDB 的 EXPLAIN ANALYZE)持续优化表结构。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 6
6 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)