Spark SQL数据源
1. 数据源1:JDBC1.1 使用load方法连接JDBC读取数据package com.bigdata.spark.day1021import java.util.Propertiesimport org.apache.log4j.{Level, Logger}import org.apache.spark.sql._/*** JDBC 数据源*/object JDB...
·
1. 数据源1:JDBC
1.1 使用load方法连接JDBC读取数据
package com.bigdata.spark.day1021
import java.util.Properties
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql._
/**
* JDBC 数据源
*/
object JDBCDataSource {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
val spark: SparkSession = SparkSession.builder().appName("SQLIPLocation1").master("local[*]").getOrCreate()
import spark.implicits._
//要读取数据对应表的元数据信息,然后创建DF
val products: DataFrame = spark.read.format("jdbc").options(
Map(
"url" -> "jdbc:mysql://bigdata01:3306/test",
"driver" -> "com.mysql.jdbc.Driver",
"user" -> "root",
"password" -> "*******",
"dbtable" -> "products"
)
).load()
products.show()
}
}
url:jdbc:mysql://数据库IP:端口号/数据库名称
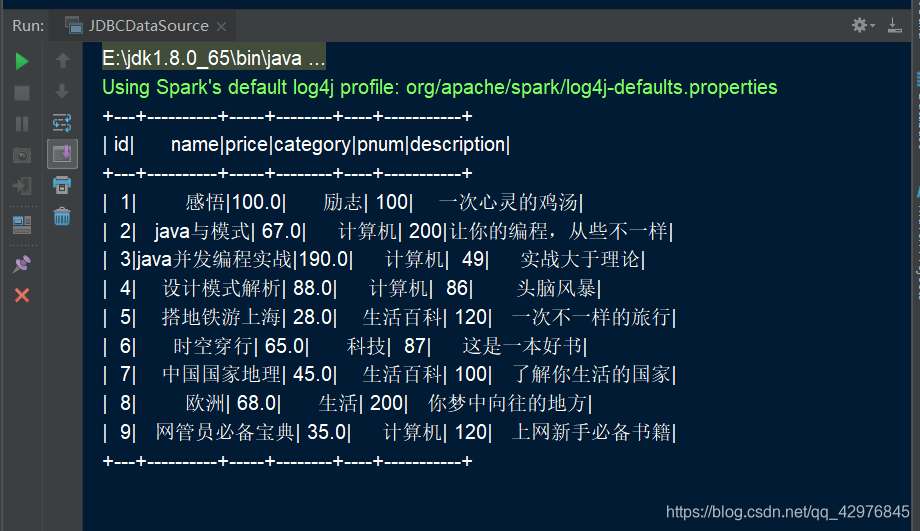
1.2 操作
val filter: Dataset[Row] = products.filter(a=>{
a.getAs[Double](2) <= 80
})
val filter1= products.filter($"price"<=80)
filter.show()
filter1.show()
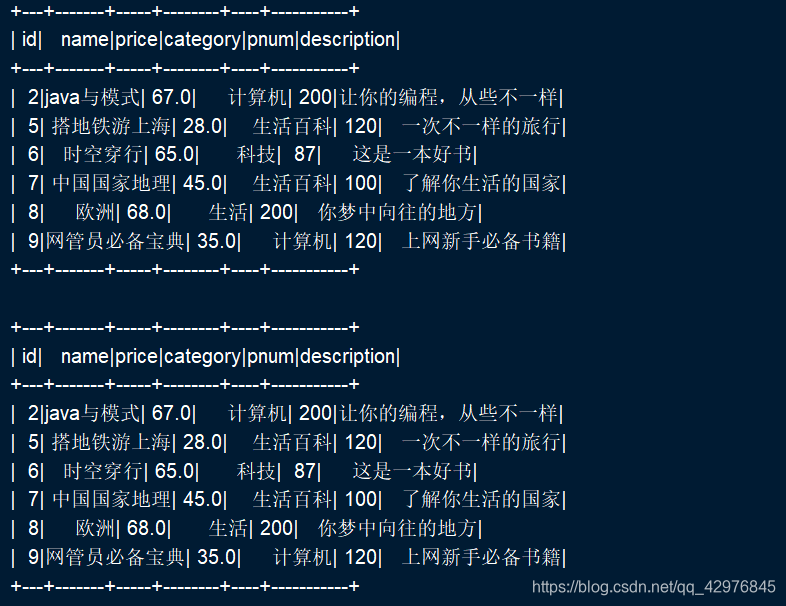
1.3 使用Save方法把数据保存到指定数据库
val props = new Properties()
props.put("user","root")
props.put("password","********")
//保存数据
products.write.mode(SaveMode.Ignore).jdbc("jdbc:mysql://bigdata01:3306/test","products1",props)
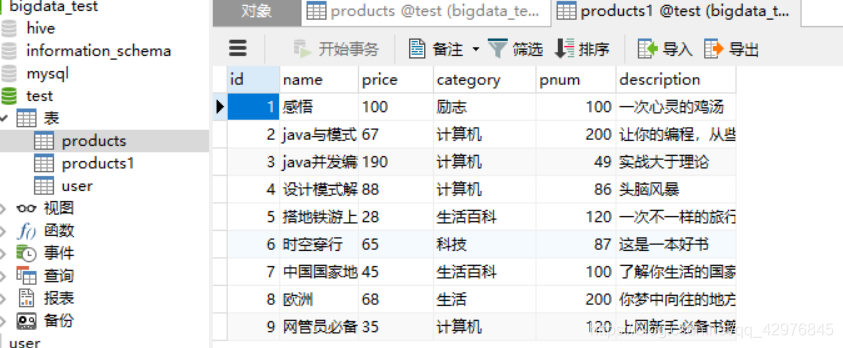
要注意写入Mysql后可能会出现中文乱码问题。具体可参考Mysql修改编码配置文件
1.4 将数据保存在本地
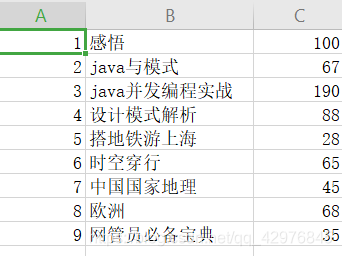
products.select($"id",$"name",$"price").write.save("D:\\testFile\\product")

可以看出, Spark SQL默认保存的文件格式:parquet文件 (列式存储)
1.5 将数据指定格式的保存
1.5.1 csv
products.select($"id",$"name",$"price").write.format("csv").save("D:\\testFile\\product1")

1.5.2 json
products.write.json("D:\\testFile\\product2")


2. 数据源2:Parquet(列式存储文件,Spark SQL的默认数据源)
2.1 其他格式的数据文件可以转成Parquet文件
val result: DataFrame = spark.read.json("D:\\testFile\\product2")
result.write.parquet("D:\\testFile\\product3")
2.2 Parquet格式文件支持Schema的合并(以官网举例)
package com.bigdata.spark.day1021
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.{DataFrame, SparkSession}
object SparkDataSource {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
val spark: SparkSession = SparkSession.builder().appName("Parquet").master("local[*]").getOrCreate()
import spark.implicits._
//创建第一个Parquet文件(RDD->Parquet)
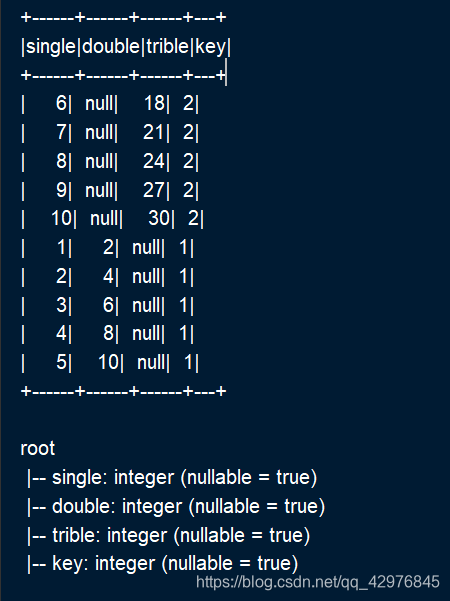
val df1: DataFrame = spark.sparkContext.makeRDD(1 to 5).map(a => (a,a * 2)).toDF("single","double")
df1.write.parquet("D:\\testFile\\product4\\key=1")
//创建第二个Parquet文件
val df2: DataFrame = spark.sparkContext.makeRDD(6 to 10).map(a => (a,a * 3)).toDF("single","trible")
df2.write.parquet("D:\\testFile\\product4\\key=2")
//合并生成的Parquet文件
val df3: DataFrame = spark.read.option("mergeSchema","true").parquet("D:\\testFile\\product4")
//spark.read.option("mergeSchema","true").parquet("D:\\testFile\\product6")
df3.show()
df3.printSchema()
3. 数据源3:Json
spark.read.json("D:\\testFile\\product2")
spark.read.format("json").load("D:\\testFile\\product2")
4. 数据源4:Hive Table
4.1 集成Hive和Spark
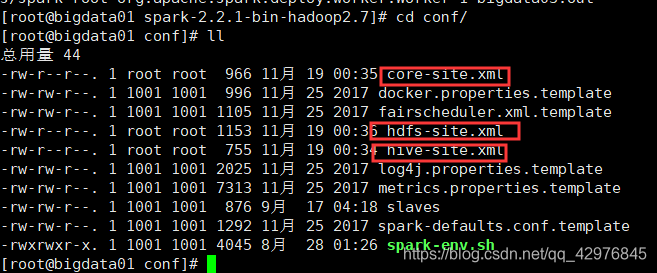
4.1.1 将Hive和Hadoop的配置文件放到Spark配置文件conf下
hive-site.xml
core-site.xml
hdfs-site.xml
4.1.2 启动Spark shell的时候加入mysql的驱动
bin/spark-shell --master spark://bigdata01:7077 --jars /root/mysql-connector-java-5.1.44.jar
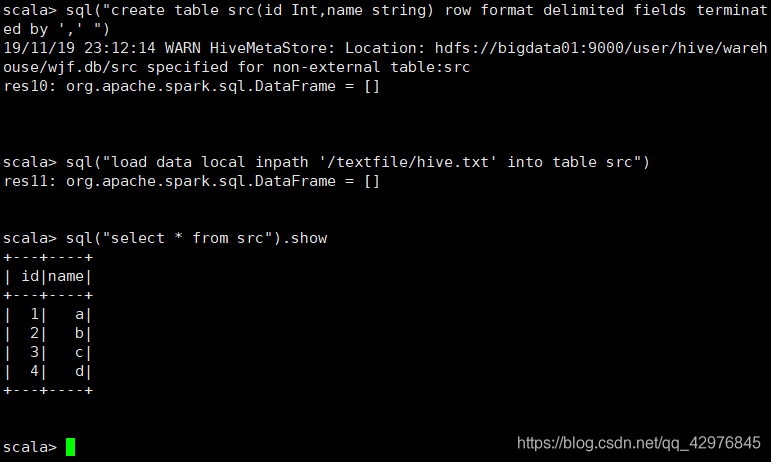
4.2 使用spark sql操作hive
4.3 Spark整合Hive
4.3.1 创建一个普通用户,或者直接使用root用户(需要授权可以远程登陆)
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '***********' WITH GRANT OPTION;
flush privileges;
4.3.2 添加hive-site.xml、core-site.xml、hdfs-site.xml到spark配置文件$SPARK_HOME/conf目录下
要想hive可以运行在spark上,spark启动的时候需要连接hive的元数据库,来获取表的schema信息。此时就需要知道hive的元数据库位置。所以就需要一个hive的配置文件(hive-site.xml)
还需要让sparkSQL知道hdfs在哪里,也就是namenode在哪里
hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>******************</value>
<description>password to use against metastore database</description>
</property>
</configuration>
4.3.3 进sparksql 就可以直接进行hive操作了
./spark-sql --master spark://bigdata01:7077 --driver-class-path /root/mysql-connector-java-5.1.44.jar
4.3.4 IDEA使用Spark操作hive
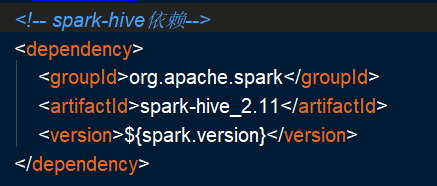
注意三点:1.添加spark-hive的依赖
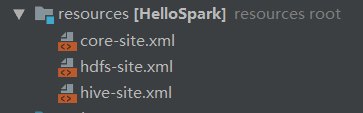
2.添加hive-site.xml、core-site.xml、hdfs-site.xml到resources
3.开启spark对hive的支持
package com.bigdata.spark.day1021
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.SparkSession
object HIveTableSource {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
//Hive运行在Spark上,一定要开启spark对hive的支持
val spark = SparkSession.builder()
.appName("HiveOnSpark")
.master("spark://bigdata01:7077")
.enableHiveSupport()//启用spark对hive的支持,可以兼容hive语法
.getOrCreate()
//想要使用hive的元数据库,必须指定hive元数据库的位置,添加hive-site.xml到当前程序的classpath下
import spark.sql
sql("select * from wjf.src").show()
spark.close()
}
}

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)