Apache Doris 数据导入方案终极指南:原理、优化与问题排查
本文将彻底拆解 Stream Load、Broker Load、Routine Load、Insert into 四大核心方案,从原理解析到导入调优,从数据转换到故障排查,提供一站式解决方案。

作为一款高性能 MPP 数据库,Apache Doris 在 PB 级数据分析场景中表现出色,但许多用户在数据导入阶段常陷入选择困境。本文将彻底拆解 Stream Load、Broker Load、Routine Load、Insert into 四大核心方案,从原理解析到导入调优,从数据转换到故障排查,提供一站式解决方案。
一、技术原理深度拆解
1.1 核心数据流向
Client(提交任务) → [FE (协调任务)] → BE (数据写入/均衡)
FE节点:负责元数据管理、任务调度
BE节点:数据导入、副本同步、数据分片存储
注:stream load可以直接指定BE导入数据
1.2 方案对比
| 维度 | Stream Load | Broker Load | Routine Load | Insert into |
|---|---|---|---|---|
| 使用场景 | 本地文件 / 程序写入 | 对象存储 / HDFS | Kafka 实时写入 | JBDC 接口 / 外部表 / 对象存储 / HDFS |
| 单次导入数据量 | 小于 10GB | 可达数百 GB | 微批导入 MB 到 GB | 视内存而定 |
| 支持文件格式 | CSV、JSON、Parquet、ORC | CSV、JSON、Parquet、ORC | CSV、JSON | SQL 方式获取 |
二、数据导入转换及优化分析
2.1 数据转换关键技术
数据转换
转化案例
LOAD LABEL db.transform_demo (
DATA INFILE("hdfs://path/data.csv")
INTO TABLE target_table
COLUMNS TERMINATED BY ","
(raw_ts, uid, temp_value, dyn_col)
PRECEDING FILTER uid = 666
SET (
event_time = from_unixtime(raw_ts),
value = if(temp_value = 'null', null, cast(temp_value as DECIMAL(10,2))),
category = case
when dyn_col in ('A','B') then 'Group1'
else 'Group2'
end
)
WHERE raw_ts > 666
)
关键技术点:
- 列映射:将源数据列映射到目标表的不同列。【可调整列顺序及只导入特定列】
- 列变换:使用函数和表达式对源数据进行实时转换。【案例中 SET 设置】
- 前置过滤:在列映射和列变换前过滤掉不需要的原始数据。【案例中 PRECEDING 设置】
- 后置过滤:在列映射和列变换后对数据最终结果进行过滤。【案例中 WHERE 设置】
2.2 性能优化体系
优先判断是不是资源的瓶颈,搜集CPU、内存、IO、网卡的监控!!!
1.Group Commit 优化机制
通过将多个小批量导入在后台合并成一个大的事务提交,显著提升了高并发小批量写入的性能。
主要针对:
- INSERT INTO tbl VALUES(…) 语句
- Stream Load 导入
参数配置优化:
| 参数 | 默认值 | 优化建议 |
|---|---|---|
| group_commit_interval_ms | 1000 | 根据业务对数据可见性延迟的容忍度来设置 |
| group_commit_data_bytes | 104857600 | 根据系统内存资源和数据可靠性要求来权衡。 |
| group_commit | off_mode | sync_mode:适用于高并发写入场景;async_mode:适用于写入延迟敏感以及高频写入 |
2.MemTable 优化
MemTable 前移进一步减少导入过程中的开销,MemTable 将生成的 Segment 数据发给下游节点,减少了数据多次编码的开销,同时使内存反压更准确和及时。此外,我们使用了 Streaming RPC 来替代了 Ping-pong RPC,减少了数据传输过程中的等待。
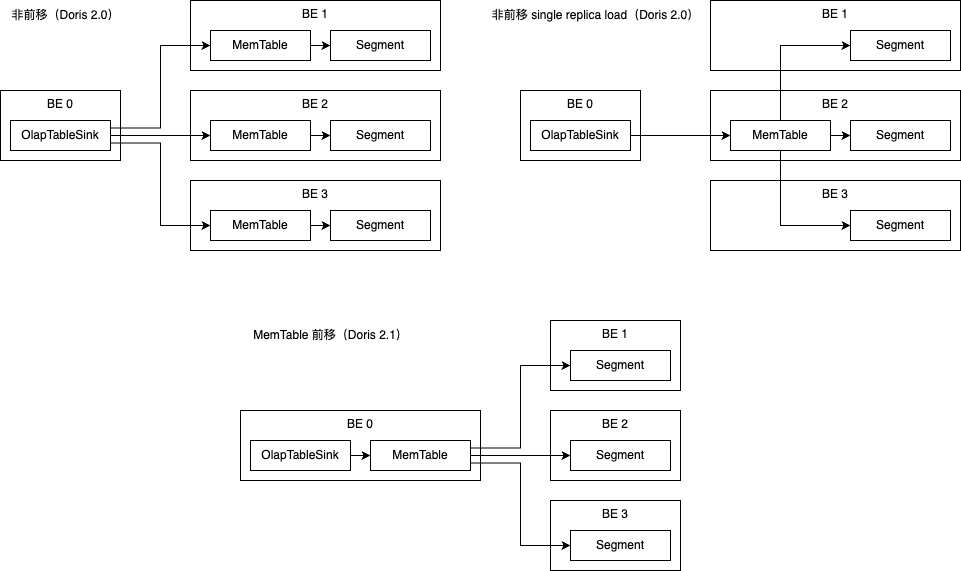
MemTable 前移在 2.1 版本中默认开启。
如果在使用过程中遇到问题、希望回退到原有的导入方式,可以在 MySQL 连接中设置环境变量 enable_memtable_on_sink_node=false 来关闭 MemTable 前移。
3.单副本导入
该能力会从多个副本中选择一个副本作为主副本(其他副本为从副本),且只对主副本进行计算,当主副本的数据文件都写入成功后,通知从副本所在节点直接拉取主副本的数据文件,实现副本间的数据同步,当所有从副本节点拉取完后进行返回或超时返回(大多数副本成功即返回成功)。
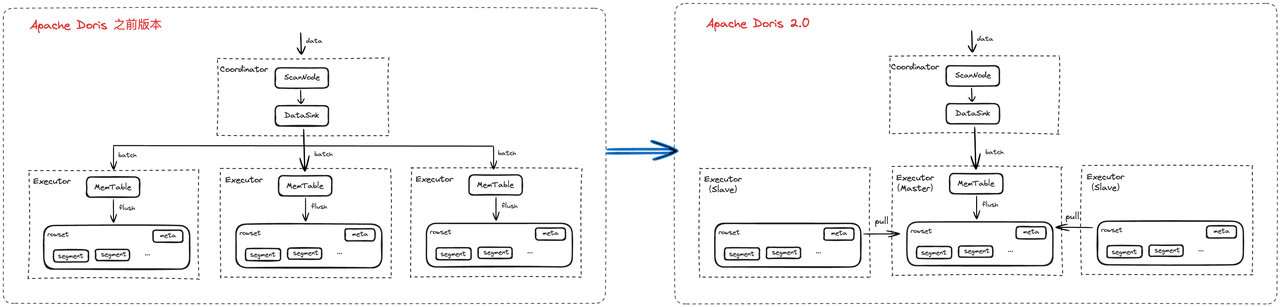
开启参数
FE 配置:enable_single_replica_load = true
BE 配置:enable_single_replica_load = true
环境变量(insert into): set experimental_enable_single_replica_insert = true;
4.参数调优
Stream Load
设置sync_tablet_meta=false(无高可用需求时),减少元数据同步。
控制并发数不超过 BE 的 HTTP Server 线程数(默认 48)(be 参数webserver_num_workers)。
Routine Load
任务配置:
增大批次参数:max_batch_interval=60s
max_batch_size=1G。(注意数据可见性的时间要求)
调整并发数:desired_concurrent_number需小于 BE 的routine_load_consumer_pool_size(默认 10)。
Fe:max_routine_load_task_num_per_be=1024,max_routine_load_task_concurrent_num=256
Be:routine_load_consumer_pool_size=10
Broker Load
并行度调优:
设置任务参数:load_parallelism=8、send_batch_parallelism=1。(后者仅在关闭 memtable 前移时生效)
调整 FE 全局参数:max_broker_concurrency=10。
本次导入并发数 = Math.min(源文件大小/min_bytes_per_broker_scanner,max_broker_concurrency,当前BE节点个数 * load_parallelism)
提高compaction速度
BE 参数
max_base_compaction_task_num_per_disk:默认值 2,每个磁盘最大compaction任务数 (视情况增大)
vertical_compaction_num_columns_per_group:默认值 5,在列式 compaction 中,组成一个合并组的列个数 (视情况增大)
max_base_compaction_threads :默认值 2, Base Compaction 线程池中线程数量的最大值,-1 表示每个磁盘一个线程。(视情况增大)
FE 参数
async_loading_load_task_pool_size:默认值10, loading_load任务执行程序池大小。该池大小限制了正在运行的最大 loading_load任务数。当前,它仅限制 broker load的 loading_load任务的数量。
三、避坑指南:常见故障解析
-
Stream load : Doris的Stream Load那些事儿,你踩过哪些“坑”?
-
Routine load:Doris的Routine Load导入指南
-
导入慢分析及优化:Doris 导入慢该如何排查及优化?
四、全景方案选型决策树
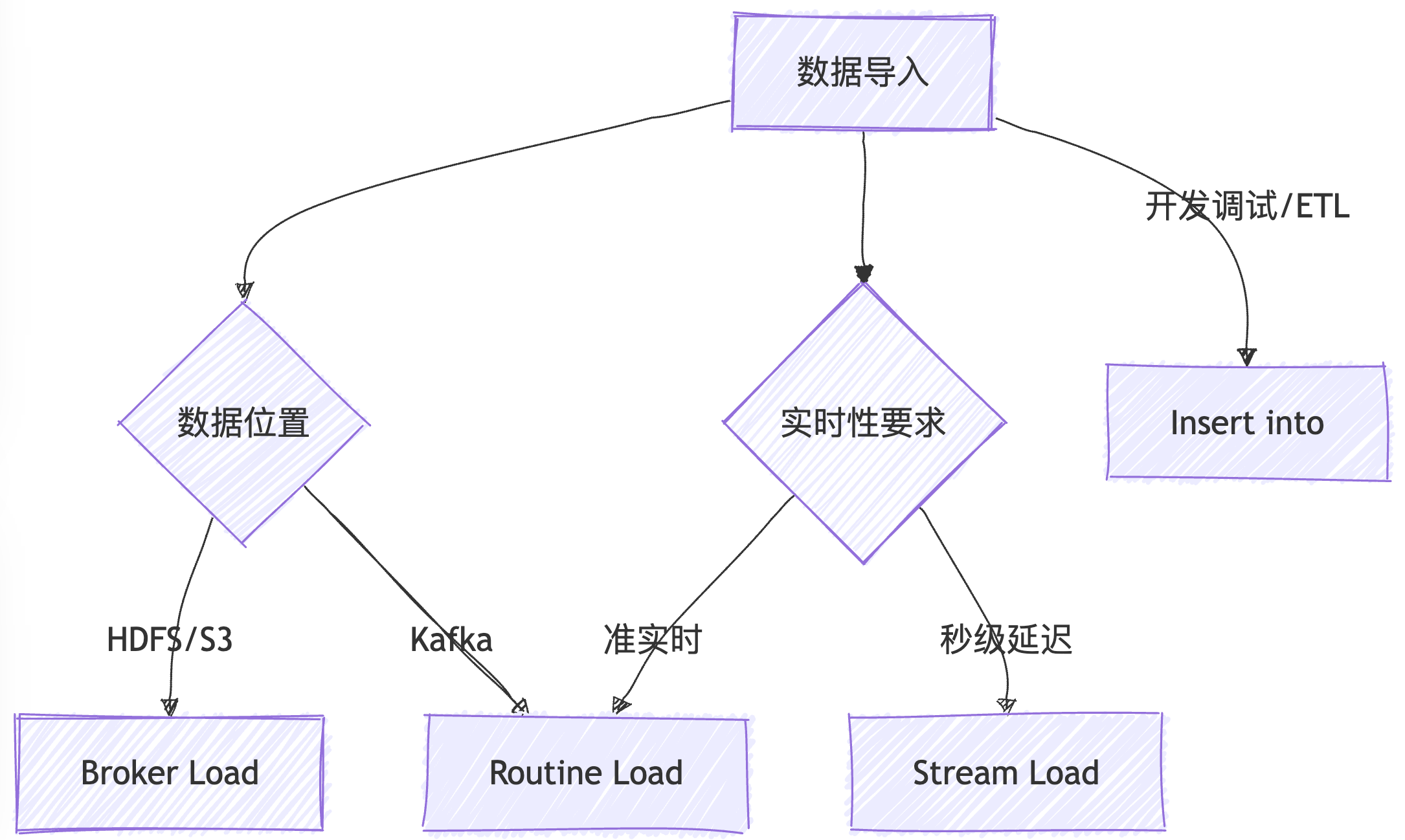
通过本文的系统性梳理,读者可精准匹配业务场景与技术方案。建议收藏本文作为 Doris 数据导入的案头手册,随时应对各类数据接入挑战。如需更详细指导,关注公众号回复 “微信” 进入Doris官方社区获取原厂人员指导!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 17
17 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)