人工智能图像识别应用基础(图像分类)
在当今的技术背景下,图像分类_已经成为了计算机视觉领域中一个至关重要的研究方向。图像分类是计算机视觉中的一个基本任务,旨在将输入图像分配到一个或多个类别中。通过_卷积神经网络 (CNN)_ 等算法,图像分类可以在许多领域中得到应用,如医疗诊断、自动驾驶和社交媒体等。
一、介绍
在当今的技术背景下,图像分类_已经成为了计算机视觉领域中一个至关重要的研究方向。图像分类是计算机视觉中的一个基本任务,旨在将输入图像分配到一个或多个类别中。通过_卷积神经网络 (CNN)_ 等算法,图像分类可以在许多领域中得到应用,如医疗诊断、自动驾驶和社交媒体等。
二、图像分类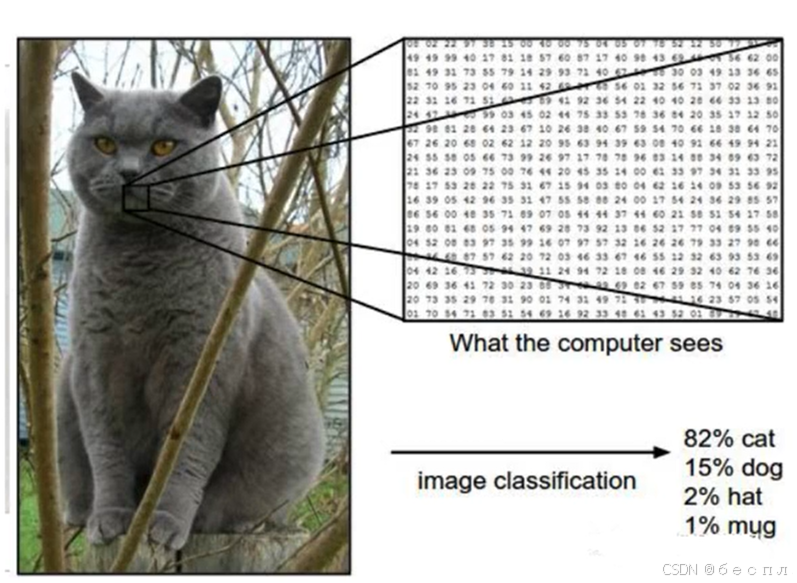
将不同的图像,划分到不同的类别标签,实现最小的分类误差。在我们人眼中的景色、物体、动物、人像,在机器眼中就是一块块数据。
1、图像分类的三层境界
- 通用的多类别图像分类(例如:识别猫狗)
- 子类细粒度图像分类(例如:白噪照片识别品种)
- 实例级图片分类(例如:人脸识别)
-
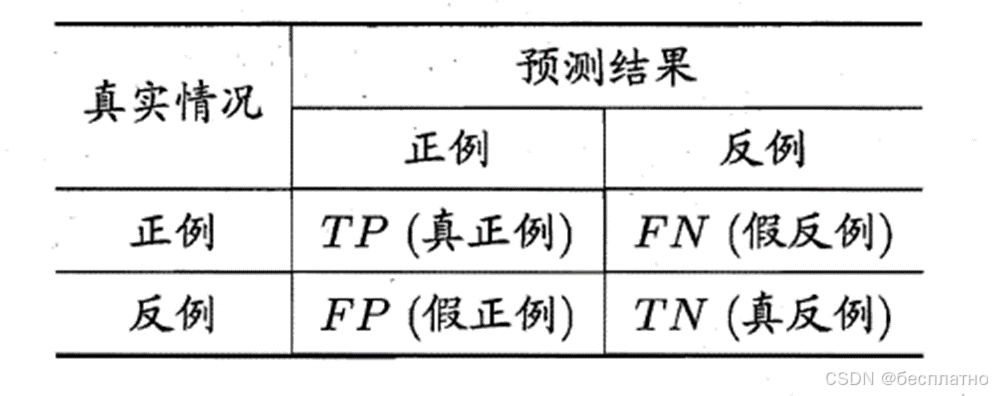
2、图像分类评估指标之混淆矩阵
-
混淆矩阵(Confusion Matrix),又称为可能性矩阵或错误矩阵。混淆矩阵是可视化工具,特别用于监督学习,在无监督学习一般叫做匹配矩阵。在图像精度评价中,主要用于比较分类结果和实际测得值,可以把分类结果的精度显示在一个混淆矩阵里面。
-
TP(True positive,真正例)——将正类预测为正类数。样本的真实类别是正类,并且模型识别的结果也是正类。
FP(False postive,假正例)——将反类预测为正类数。样本的真实类别是正类,但是模型将其识别为负类。
TN(True negative,真反例)——将反类预测为反类数。样本的真实类别是负类,但是模型将其识别为正类。
FN(False negative,假反例)——将正类预测为反类数。样本的真实类别是负类,并且模型将其识别为负类。
-
-
该矩阵可用于易于理解的二类分类问题,但通过向混淆矩阵添加更多行和列,可轻松应用于具有3个或更多类值的问题。
-
3、图像分类评估指标
-
1)精确率(Accuracy):
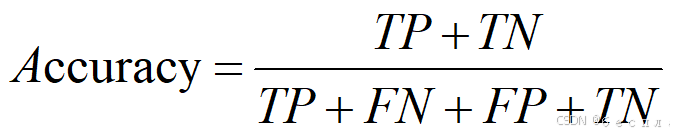
-
精确率是最常用的分类性能指标。可以用来表示模型的精度,即模型识别正确的个数/样本的总个数。一般情况下,模型的精度越高,说明模型的效果越好。
2)准确率(Precision):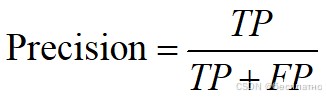
又称为查准率,表示在模型识别为正类的样本中,真正为正类的样本所占的比例。一般情况下,查准率越高,说明模型的效果越好。
3)召回率(Recall):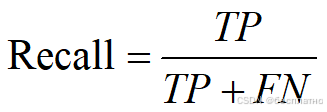
又称为查全率,表示模型正确识别出为正类的样本的数量占总的正类样本数量的比值。
4)F1_Score: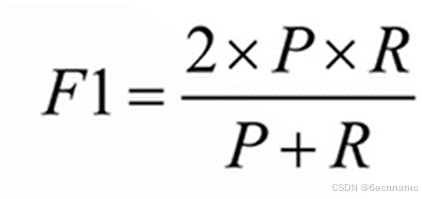
又称为平衡 F分数(Balanced Score),它被定义为正确率和召回率的调和平均数。
查准率和查全率是一对矛盾的指标。一般来说,查准率高时,查全率旺旺偏低;二查全率高时,查准率往往偏低。
4、P-R曲线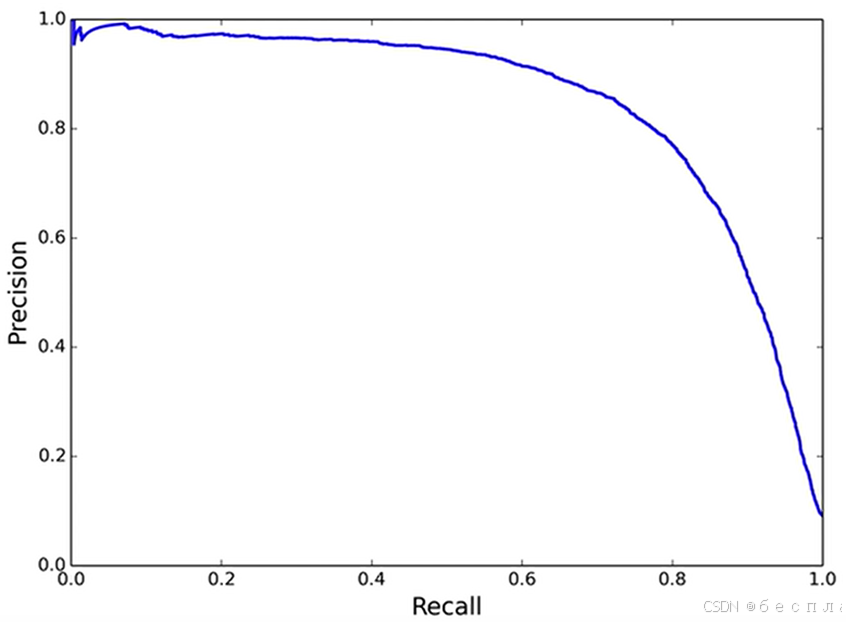
P-R曲线是一种用于评估二分类模型性能的图形工具。该曲线有两个重要指标:精确度(Precision)和召回率(Recall)。精确度指模型在预测为正类别的样本中真正为正类别的比例。召回率指模型成功预测为正类别的样本占实际正类别的比例。P-R曲线以不同的阈值为基础,展示了精确度和召回率之间的关系。在P-R曲线中,横轴为Recall召回率,纵轴为Precision精确率。
P —— 精确度,R —— 召回率。
- 召回率增加,精度下降。
- 曲线和坐标轴面积越大,模型越好。
- 对正负样本不均衡敏感。
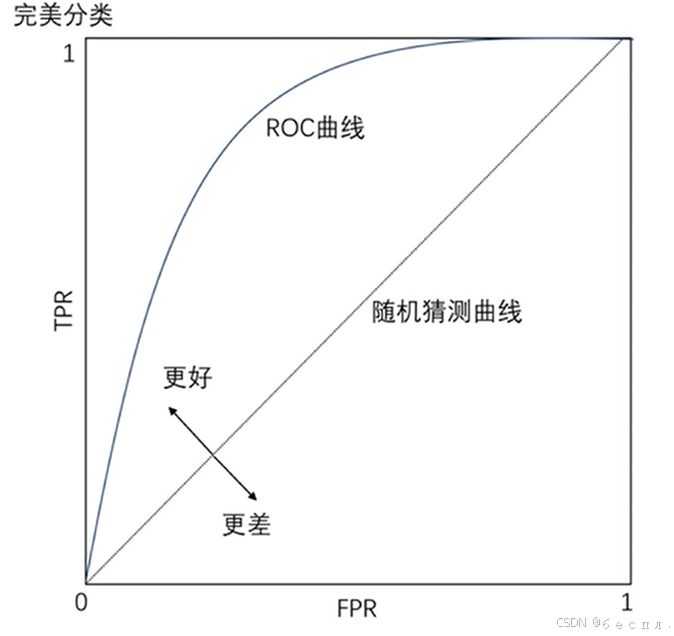
5、ROC曲线
ROC曲线通常用于评估二元分类器,用于可视化分类器在不同阈值下的性能表现。
该曲线的两个重要指标:真正例率(TPR)和假正例率(FPR)。TPR指的是被正确分类为正类的正类样本的比例。FPR指的是被错误的分类为正类的负类样本的比例。ROC曲线的目标是在各种不同阈值下,找到一个平衡点,使FPR尽可能低,而TPR尽可能高。ROC曲线的横轴是FPR假正例率,纵轴是TPR真正例率。
优点
- 综合性能度量:ROC曲线提供了分类器在不同阈值下的性能综合评估,不局限于一个特定阈值的性能。
- 可视化:ROC曲线直观展示了分类器性能,帮助决策者更好地理解模型的行为。
- 适用于不平衡数据集:ROC曲线关注的是真正例率和假正例率,而不是样本数量。
缺点
- 不适用于多类别问题:ROC曲线通常用于二元分类问题,不适用于多类别分类。
- 不考虑概率分数差异:ROC曲线不考虑概率分数的绝对值

6、多类别分类模型各个类别之间的分类情况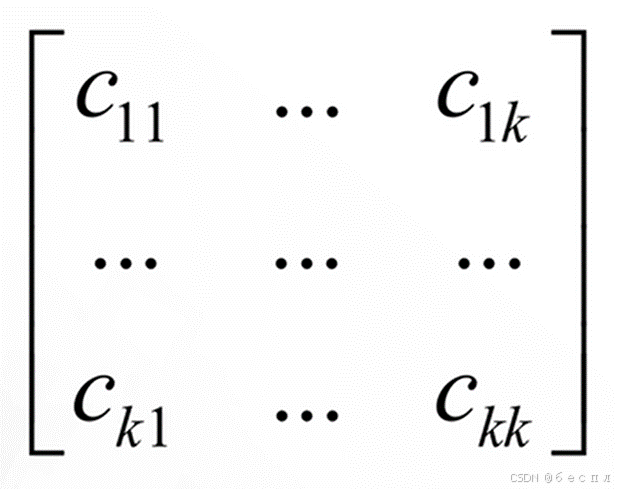
对于k分类问题,混淆矩阵为k*k的矩阵,元素Cij表示第i类样本被分类器判定为第j类的数量。
主对角线的元素之和为正确分类的样本数,其余元素之和为错误分类的样本数。对角线的值越大,分类器准确率越高。
二、模型基本概念-网络的深度
Bengio和LeCun说过大多说函数如果用一个深层结构刚刚好解决问题,那么就不可能有一个更浅的同样紧凑的结构来解决。 要解决比较复杂的问题, 要么增加深度, 要么增加宽度, 而增加宽度的代价旺旺远高于深度。 一定深度是有必要的。
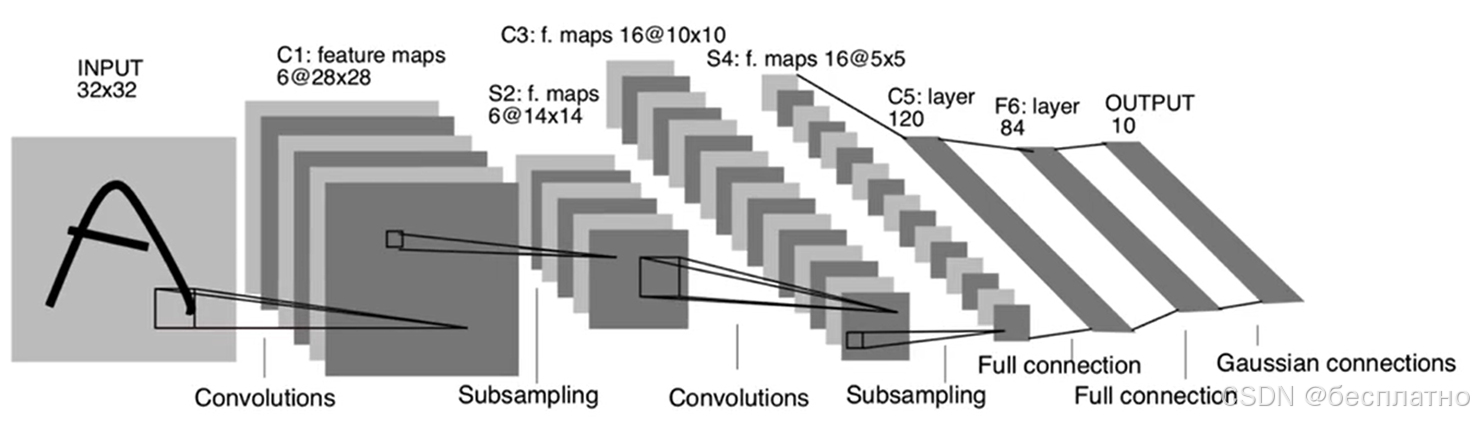
深度学习最重要的属性,计算最长路径的卷积层+全连接层数量。LeNet网络,C1+C3+C5+F6+Output共5层。
每一个网络层的通道数,以卷积网络层计算。LeNet网络,C1(6),C3(16)。
三、图像分类中样本量过少的问题
样本量极少:样本获取较难导致总体样本量过少。(例如:螺丝厂、ct胶片)
解决方案:
- 迁移学习:使用预训练模型。ImageNet数据集具有通用性,使用它进行预训练可加速模型收敛。
- 数据增强(有监督方法与无监督方法)
- 有监督方法:平移、翻转、亮度、对比度、裁剪、缩放等。(有一个标准答案)
- 无监督方法:通过GAN网络生成所需样本,然后再进行训练。(没有标准答案)

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 21
21 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)