关于点云数据最远点采样的方法分析
PointNet++中的最远点采样方法分析
最近在学习 PointNet++(下文简称 p2)的网络模型框架,p2 相较于它的前身 PointNet (下文简称 p1)更加注重了点与点之间的特征联系。
p2 在 p1 的基础上在点云数据上取若干中心点,然后围绕中心点将点云数据划分为一个个点云簇,根据划分半径的不同又可以创造出多组簇,最后计算出这些簇的特征集合。
所以在学习 p2 的过程中,第一个重要的方法就是点云数据的最远点采样方法。以官网发布的 p2 为例,打开模型文件 pointnet2_cls_msg.py:
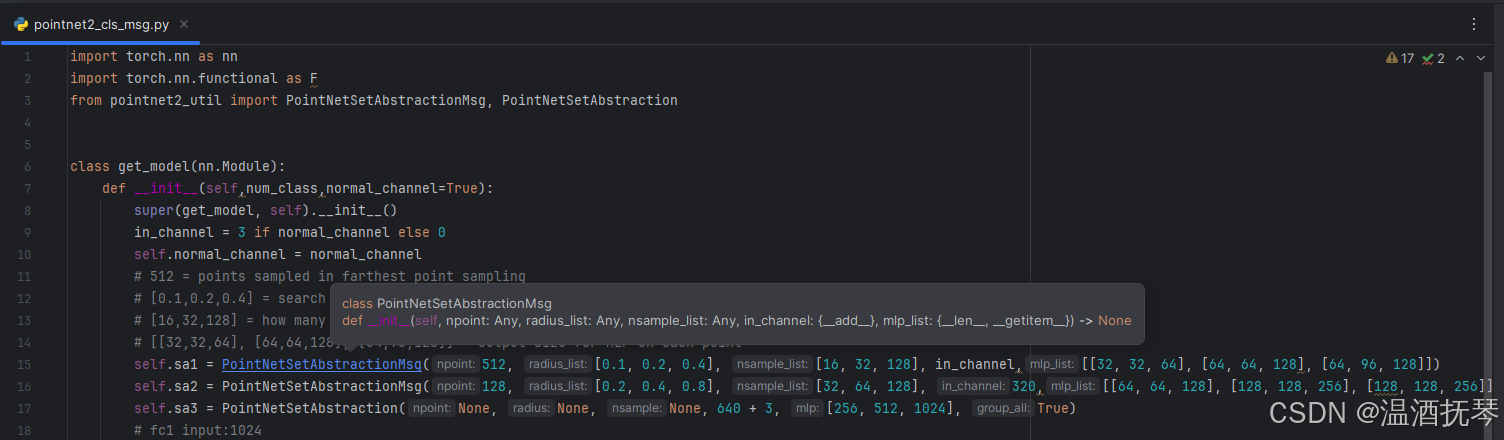 -1-
-1-
进入 PointNetSetAbstractionMsg 类。
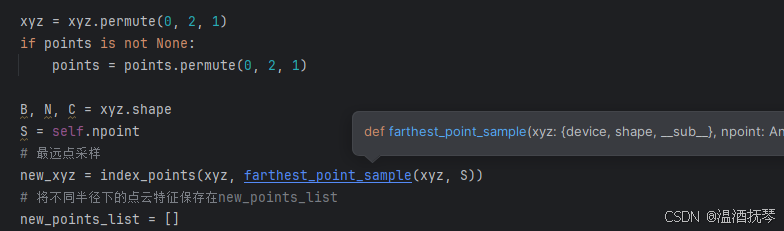 -2-
-2-
进入 farthest_point_sample 方法。
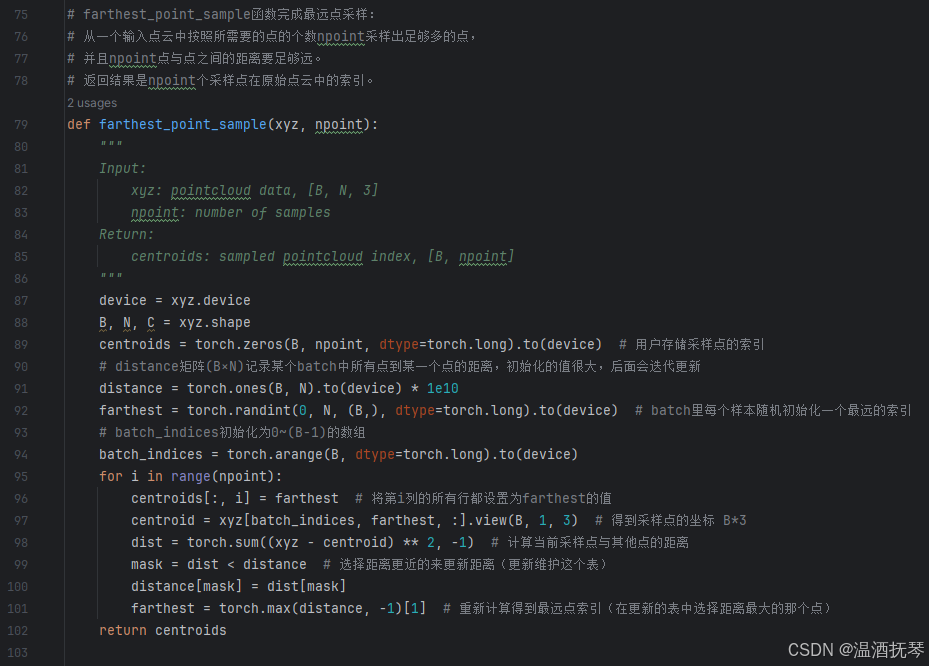 -3-
-3-
通过查看源码可以知道这就是最远点采样的方法,输入原始的位置信息(x, y, z),数据形状为 [B, N, 3],其中 B 为 batch_size,为处理数据的批次大小,N 为点云数据中点的数量,最后的 3 代表 3 维,即 x,y,z 三个维度,为 tensor 数据类型。另一个输入是 npoint,是采样中心点目标个数。函数最终返回一个 tensor 类型的张量,形状为(B,npoint),该张量内含有中心点的索引信息。
简单了解
在学习这个函数之前,我们先搞懂最远点采样的基本原理,最远点采样的目的就是在一片点云数据中取若干中心点,这些中心点要求尽量覆盖所有数据,中心点不能集中在某一区域。
例如现在有 5 个点云数据(同平面同直线),使用最远点采样法取三个中心点。
 -4-
-4-
随机初始化一个中心点。
 -5-
-5-
该中心点 1 距离所有点的距离为 dist1 = [0, 1, 2, 3, 4]
其中索引为 4 的点距离中心点 1 的距离最远,取其为中心点 2
 -6-
-6-
该中心点 2 距离所有的点的距离为 dist2 = [4, 3, 2, 1, 0]
结合两者的距离,mask = dist2 < dist1,得到 mask = [False, False, False, True, True] 布尔掩码。
最后计算 dist1[mask] = dist2[mask],将 dist2 中满足 musk 中为 True 的元素覆盖 dist1 中相应位置的值。
最终得到 dist1 = [0, 1, 2, 1, 0],这是每个点相对于这两个中心点综合的距离。
同理,第三个中心点应该取索引为 2 的点,因为它距离所有中心点最远(dist1 中最大的值):
 -7-
-7-
此时所有中心点对于所有点的距离为 [0, 1, 0, 1, 0]
看到这里各位已经对最远点采样有了一个基础的认知。下面开始分析源码。
为了更好的理解源码,这里我用自己写的测试代码 test_farthest 进行调试来学习farthest_point_sample(最远点采样函数):
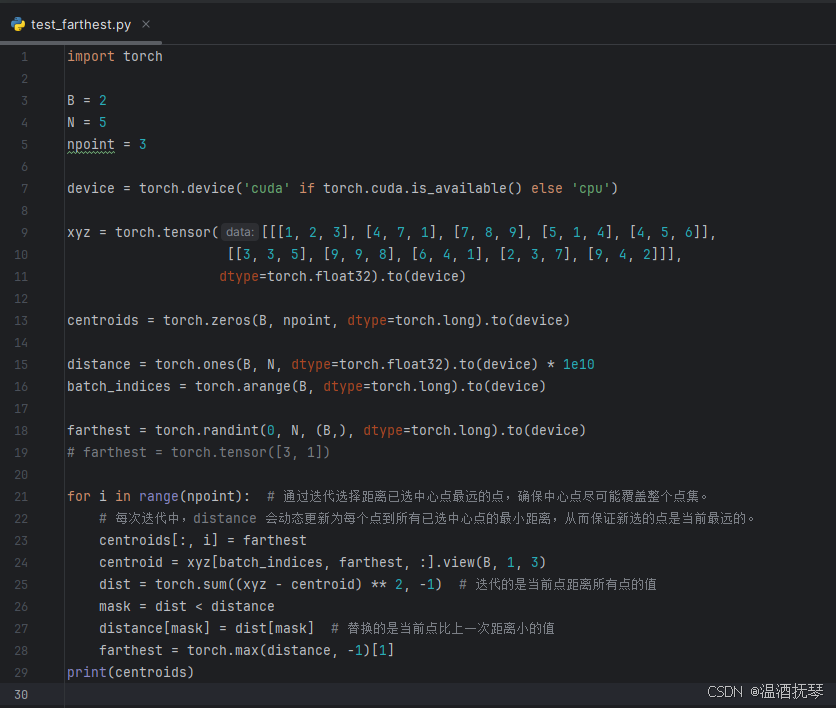 -8-
-8-
在日常的点云数据中点云的个数在千位数往上,同时为了更好的利用内存也会将 batch_size 设置为十位数往上,这里为了简化过程,设置 B=2, N=5,npoint=3,分别为 batch_size,点云数,采样中心点数。下面提供代码方便各位看客调试 (debug)。
import torch
B = 2
N = 5
npoint = 3
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
xyz = torch.tensor([[[1, 2, 3], [4, 7, 1], [7, 8, 9], [5, 1, 4], [4, 5, 6]],
[[3, 3, 5], [9, 9, 8], [6, 4, 1], [2, 3, 7], [9, 4, 2]]],
dtype=torch.float32).to(device)
centroids = torch.zeros(B, npoint, dtype=torch.long).to(device)
distance = torch.ones(B, N, dtype=torch.float32).to(device) * 1e10
batch_indices = torch.arange(B, dtype=torch.long).to(device)
farthest = torch.randint(0, N, (B,), dtype=torch.long).to(device)
# farthest = torch.tensor([3, 1])
for i in range(npoint): # 通过迭代选择距离已选中心点最远的点,确保中心点尽可能覆盖整个点集。
# 每次迭代中,distance 会动态更新为每个点到所有已选中心点的最小距离,从而保证新选的点是当前最远的。
centroids[:, i] = farthest
centroid = xyz[batch_indices, farthest, :].view(B, 1, 3)
dist = torch.sum((xyz - centroid) ** 2, -1) # 迭代的是当前点距离所有点的值
mask = dist < distance
distance[mask] = dist[mask] # 替换的是当前点比上一次距离小的值
farthest = torch.max(distance, -1)[1]
print(centroids)
这段代码中的 xyz 原始点云数据是形状为(2,5,3)的 tensor 张量。
device 是计算机的设备,如果你的设备上有 gpu 显卡就使用 gpu 参与计算过程,否则就用 cpu
debug过程
 -9-
-9-
centroids 是用来准备存储采样点索引的(B, npoint) 张量,初始化后其中的值都为零。
distance 是形状为 (B,N) 的矩阵,准备用来记录某个 batch 中所有点到某一个点的距离,输出化的数值设置的很大,方便后续迭代更新。
batch_indices 是根据 batch 初始化为 0~(B-1) 的数组,在本例中 B = 2,所以batch_indices=tensor([0,1])
farthest 是本测试中最重要的变量,它的值是取每个 batch 中任意某个点的索引,每个 batch中 的 N=5,所以可取范围是 0~4,由于这是随机的,所以每次的 debug 初始化的 farthest 都会不同,最终的结果也会不同。在本次初始化:farthest = tensor([2, 2])
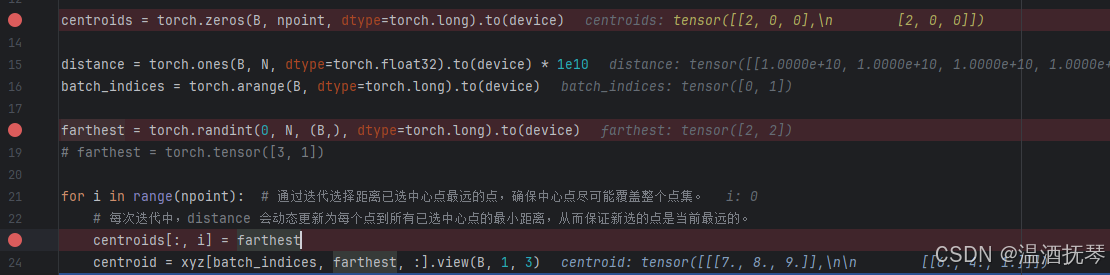 -10-
-10-
第 21 行开始 for 循环语句,每次循环的目的是找到采样点。
centroids[:, i] = farthest,该语句将 farthest 中的值赋值给 centroids 的第一列,在图-10-中第 13 行左侧可以看到 centroids 较于 图-9- 已经发生了更新。该语句的目的是存储所有 batch 中找到的采样点。在循环中寻找采样点是所有 batch 同时进行的。
centroid = xyz[batch_indices, farthest, :].view(B, 1, 3),是根据 batch_indices 和 farthest 的值来提取出目标采样点,通过组合两个索引张量实现精确坐标定位,有人会问为什么第一次for循环还没计算就有目标采样点了呢?因为farthest的初始化是随机的,只有第一次的循环不需要计算采样点。最终将形状设置为(B, 1, 3)。centroid 是形状为 (B, npoint) 的 tensor 张量,在本例中即为 (2, 3),初始化的值为 tensor([[0, 0, 0], [0, 0, 0]]),batch_indices 的值为 tensor([0, 1]),farthest 的值为 tensor([2, 2]),根据 xyz 的形状(2, 5, 3),batch_indices 和 farthest 分别定位 centroid 的第 0 维和第 1 维的索引,将定位得到的点存入 centroid 中。如果有同学对tensor张量的学习和理解不够的话可能会看的很糊涂,建议温习。
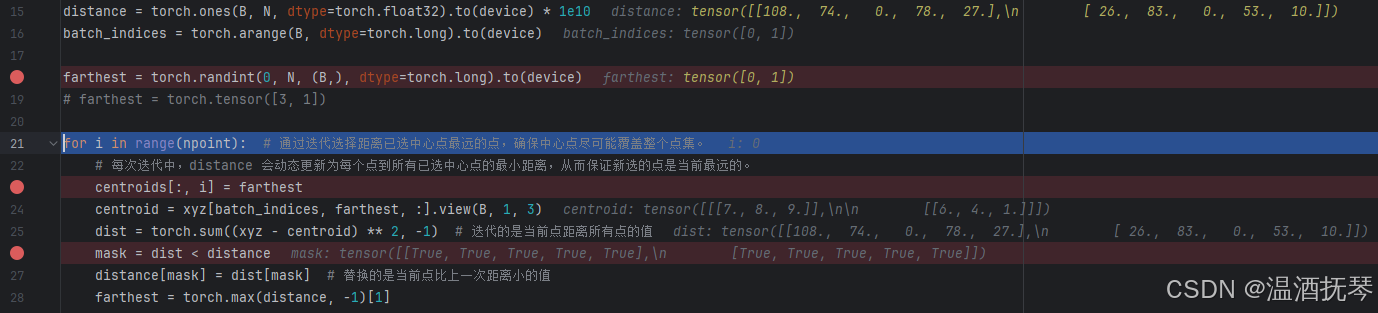
第 25 行计算dist,计算的是第 24 行所取得采样点与同一个 batch 中每个点的距离差平方的和,代表距离的远近。dist = torch.sum((xyz - centroid)**2, -1) 中的 -1 指的是 xyz 和 centroid 张量的最后一维参与运算。
mask = dist < distance,使用比较运算符 < 来生成一个布尔掩码mask, 该掩码表示 dist 中的元素是否小于 distance 中对应位置的元素,由于之前对 distance 的初始化值很大(1e10),所以 mask 中的值全是 True.
distance[mask] = dist[mask],将 dist 中满足 musk 中为 True 的元素覆盖 distance 中相应位置(mask掩码中为True的位置)的值。对比图-11-与图-10-的第十五行右侧可以观察到distance的值已经更新。
farthest = torch.max(distance, -1)[1],farthest 取值 distance 中最大值的索引。对比图-11-与图-10-可以观察到第 18 行右侧的 farthest 值已经更新。其实在这里第二个采样点已经找到了,下一次的循环遍历是为了找下一个采样点。
 -12-
-12-
图-12-为第二次 for 循环的过程。
centroids[:, i] = farthest 会将上一次得到的 farthest 值存入 centroids 中。
到再次计算 mask 掩码时与第一次 for 循环有区别,此时的 mask 掩码中的值有 True 和 False,通过计算的 mask 更新 distance 的值,这里 distance 代表的是所有已选出的采样点对于所有点的距离,最后在 distance 中再次选择最大值距离的点索引作为新的采样点。
待到所有的遍历结束后,得到 centroids,输出并观察:
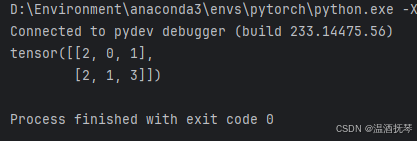
-13-
可以看到输出是一个形状为(2, 3)的tensor张量,表示的是每个batch中所选的采样点(中心点)在xyz中的索引信息。
结果查看
最后加一段索引查询代码来查看采样点:
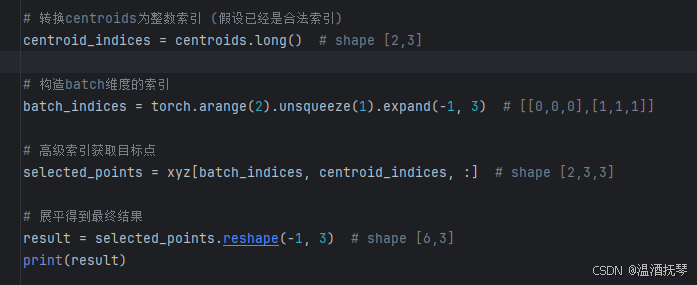 -14-
-14-
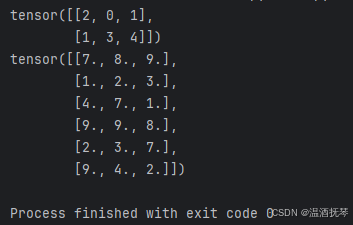
-15-
可以看到被输出的采样点。
此时再看图-3-就可以理解了。
以上是我对p2中最远点采样方法的个人拙见,欢迎斧正。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)