yolov8训练数据集(完成+测试+分析)
对完成模型训练的数据集进行测试,并查看yolov8标准库--模型训练完成后的文件目录,及各文件含义runs文件夹下各文件含义
模型训练和相关报错可以看我的前文:
环境配置创建yolov8属于自己的数据集:
配置pytorch环境(anaconda+cudn+cudnn+pytorch)_cudn+pytorch-CSDN博客
训练数据集报错:
模型训练时出现内存不足问题报错:
yolov8训练数据集报错(内存不足问题)_dataloader 的工作进程(worker)意外退出、-CSDN博客
1.完成模型训练后,测试图片:
# 六、模型测试
# 训练完模型之后,可以验证模型的检测效果,创建detec.py文件,内容如下:
from ultralytics import YOLO
# 加载训练好的模型
model = YOLO('runs/detect/train14/weights/best.pt') # 这里用你训练完以后保存的模型文件
# 推理单张图片
results = model('VOCdevkit/test/images/17.jpg')
# 显示推理结果
for result in results:
result.show()
测试图片如下:
运行得到训练结果如下:

及:已完成模型训练,能够训练相关测试
2. 训练完成数据查看
训练完成后得到对应的runs文件夹(如图)训练 输出目录:
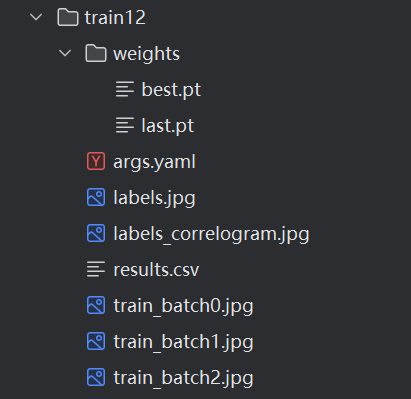
目录结构解释
-
runs/: 这是 YOLOv8 默认的输出目录,所有训练结果都会保存在这个目录下。
-
detect/: 这个子目录通常用于存放检测任务的结果。
-
train/: 这个子目录用于存放训练过程中生成的各种文件和结果。
-
train1/ 到 train142/: 这些是不同的训练实验目录,每个目录对应一次训练实验。目录名称通常包含训练配置的哈希或特定的标识符。
-
weights/: 存放该次训练过程中生成的模型权重文件。
-
best.pt: 在训练过程中在验证集上表现最好的模型权重。
-
last.pt: 训练过程中最后生成的模型权重。
-
-
args.yaml: 这个文件保存了该次训练实验的配置参数。
-
labels.jpg 和 labels_correlogram.jpg: 这些是可视化文件,可能展示了标签分布或相关性图。
-
results.csv: 这个文件通常包含了训练过程中详细的结果数据,包括每个 epoch 的损失值等。
-
train_batch0.jpg 等: 这些是训练过程中生成的批次图像,用于可视化和调试。
-
-
train14/ 和 train142/: 这些目录结构类似,包含了各自的训练结果和配置。
-
-
-
日志文件位置
在目录结构中,日志文件可能指的是以下几种文件:
-
args.yaml: 这个文件包含了训练的配置参数,可以视为配置日志,记录了训练时使用的各种设置。
-
results.csv: 这个文件通常包含了训练过程中的详细结果,包括每个 epoch 的损失值、准确率等关键指标。这是最接近传统意义上的“日志文件”的文件,因为它记录了训练过程中的详细数据。
-
labels.jpg 和 labels_correlogram.jpg: 这些文件可能包含了关于标签分布的可视化信息,虽然不是传统日志,但对于分析训练数据的标签分布很有帮助。
如何使用日志文件
-
分析训练过程:通过查看
results.csv文件,你可以了解模型在每个 epoch 的表现,包括损失值的下降情况,从而分析模型的训练过程和性能。 -
调试和优化:如果训练结果不理想,可以通过分析
args.yaml和results.csv文件来调整训练参数和策略,进行模型的调试和优化。 -
可视化:通过
labels.jpg和labels_correlogram.jpg文件,能够直观地看到标签的分布情况,这对于理解数据集的标签分布和进行数据预处理非常有帮助。
3. 提取损失值,并可视化展示损失曲线
我们能够写一段简单的代码,提取日志文件中的损失值信息,使用Matplotlib绘制对应的损失函数值:
import matplotlib.pyplot as plt
import csv
# 日志文件路径
log_file = 'runs/detect/train14/results.csv'
# 初始化损失列表
train_box_losses = []
train_cls_losses = []
train_dfl_losses = []
val_box_losses = []
val_cls_losses = []
val_dfl_losses = []
# 打开并读取日志文件
try:
with open(log_file, 'r', encoding='utf-8') as f:
reader = csv.DictReader(f)
next(reader, None) # 跳过标题行
for row in reader:
train_box_losses.append(float(row['train/box_loss']))
train_cls_losses.append(float(row['train/cls_loss']))
train_dfl_losses.append(float(row['train/dfl_loss']))
val_box_losses.append(float(row['val/box_loss']))
val_cls_losses.append(float(row['val/cls_loss']))
val_dfl_losses.append(float(row['val/dfl_loss']))
except FileNotFoundError:
print(f"Error: The file '{log_file}' does not exist.")
except ValueError:
print(f"Error: The file '{log_file}' contains invalid data.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
# 绘制训练和验证损失曲线
plt.figure(figsize=(12, 6))
plt.plot(train_box_losses, label='Training Box Loss')
plt.plot(val_box_losses, label='Validation Box Loss')
plt.plot(train_cls_losses, label='Training Class Loss')
plt.plot(val_cls_losses, label='Validation Class Loss')
plt.plot(train_dfl_losses, label='Training DFL Loss')
plt.plot(val_dfl_losses, label='Validation DFL Loss')
plt.title('Training and Validation Loss Curve')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.grid(True)
plt.savefig('training_curve.png', dpi=300)
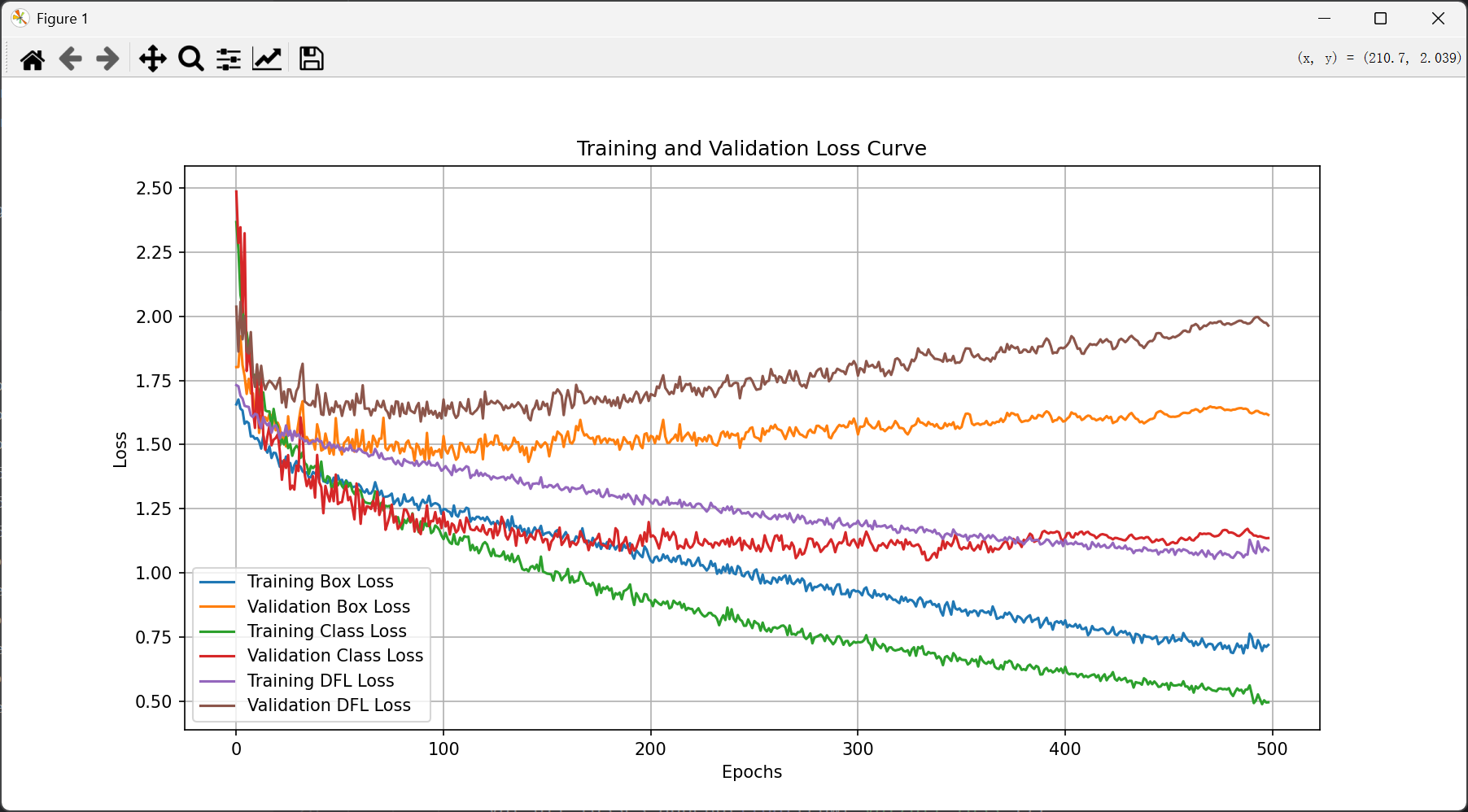
plt.show()得到类似图示结果:

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)