Kettle分页循环抽取全量数据,三步搞定
Kettle分页抽取全量数据 , 适用于大数据量初次全量抽取转换.
Kettle分页抽取全量数据 , 适用于大数据量初次全量抽取转换.
后续可再增加作业和转换,根据动态时间范围增量抽取转换...这篇先说全量的.
完整流程作业图如下: (后续会拆解梳理每步流程)

-
主要步骤如下: 有3步
第一步: 把需要用到的源数据DB和目标数据DB连接准备好,没啥好说的;如下图

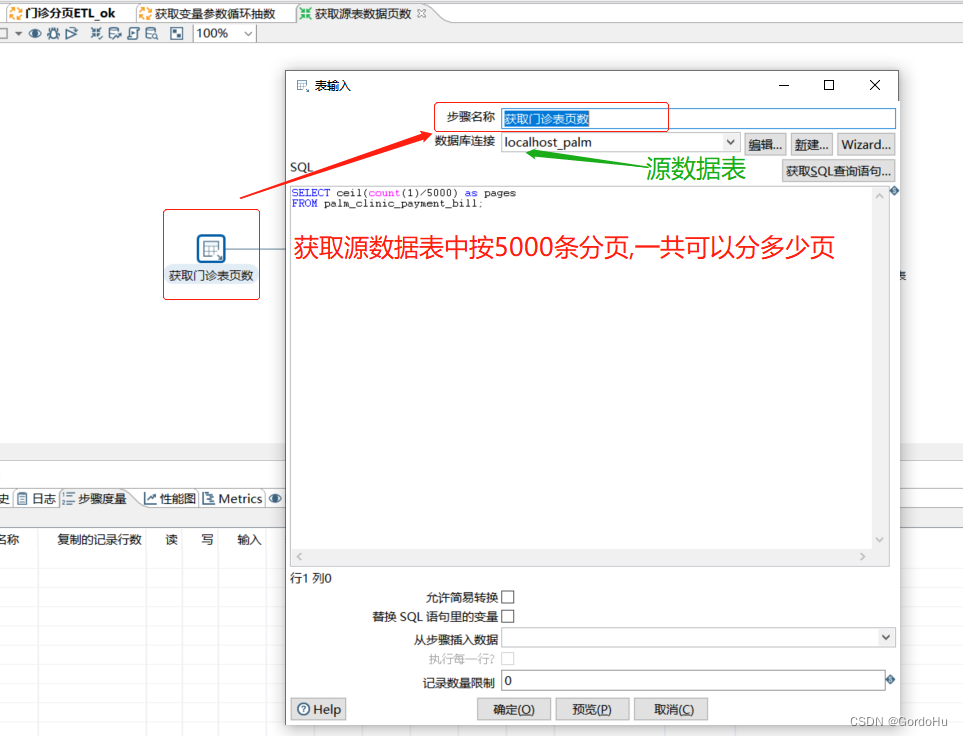
第二步: 创建(获取源数据页数)转换: 主要获取源数据表中按5000条分页的页数.
获取源表数据页数.ktr
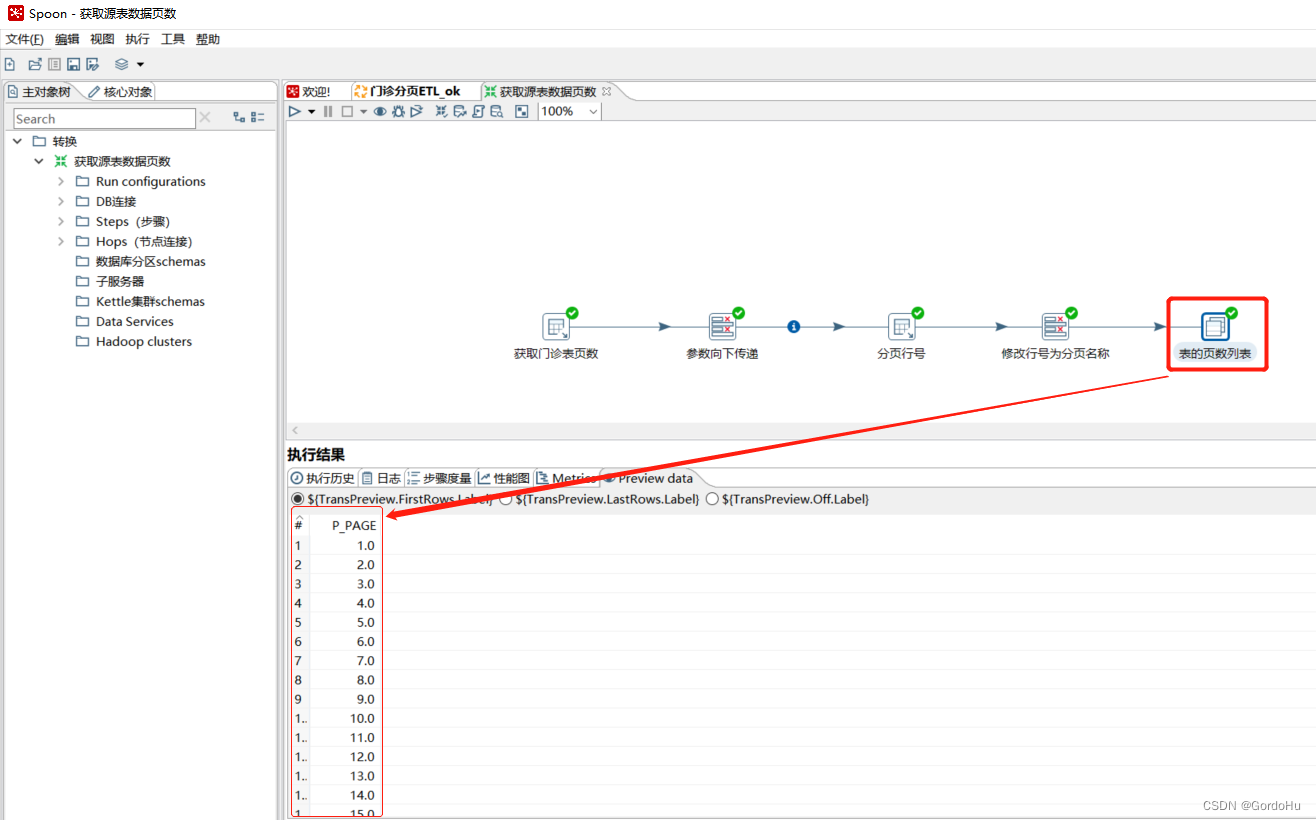
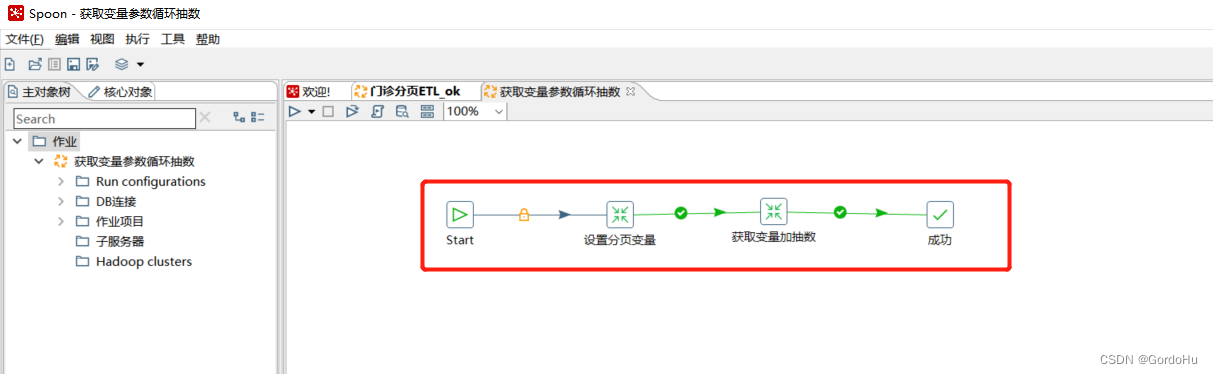
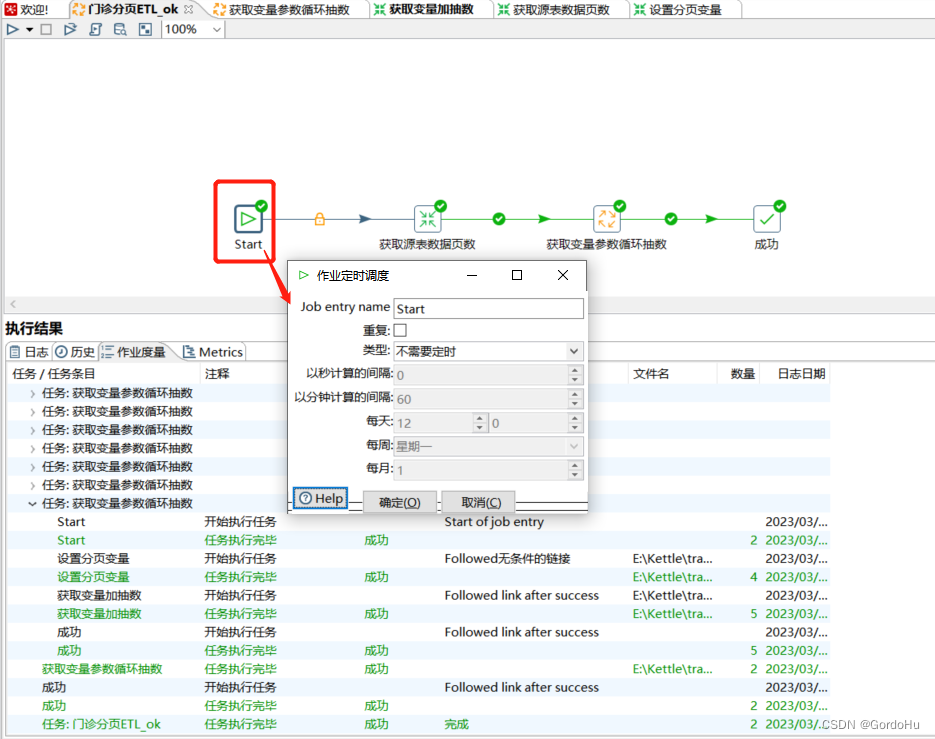
第三步: 创建(获取变量参数循环抽数)作业: 主要把上个转换的分页参数传入,用来分页查询,然后输出到目标表中.
获取变量参数循环抽数.kjb
下面详细说一下每一步的配置及参数设置
-
第二步图文详细说明 :
第二步中 , (获取源表数据页数).ktr 。第二步图中,如图示有五个流程节点;
如下 第二步 ,第一个节点(获取门诊表页数):就是获取源表页数
SELECT ceil(count(1)/5000) as pages FROM palm_clinic_payment_bill;
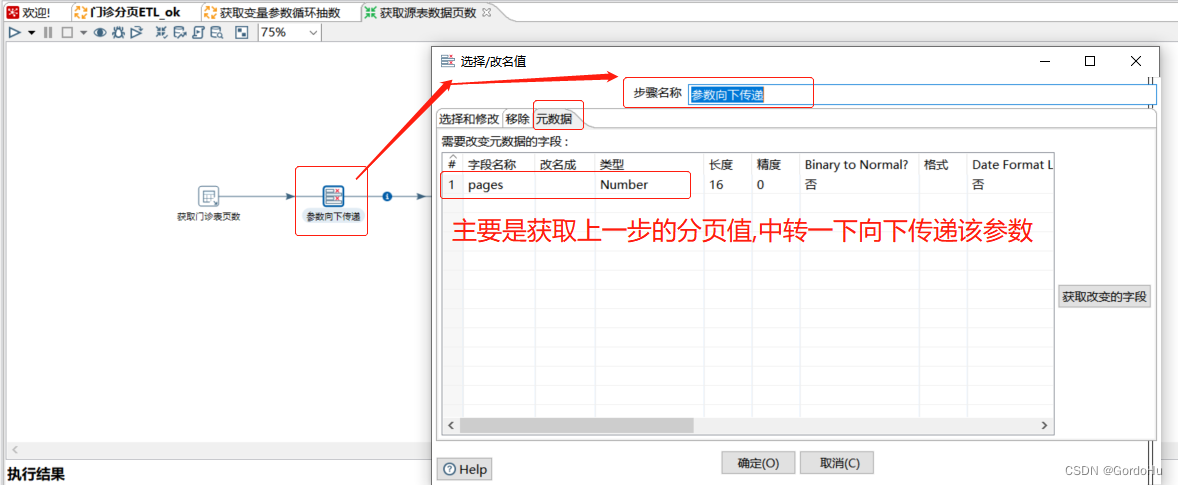
如下 第二步 ,第二个节点(参数向下传递):就是参数中转处理
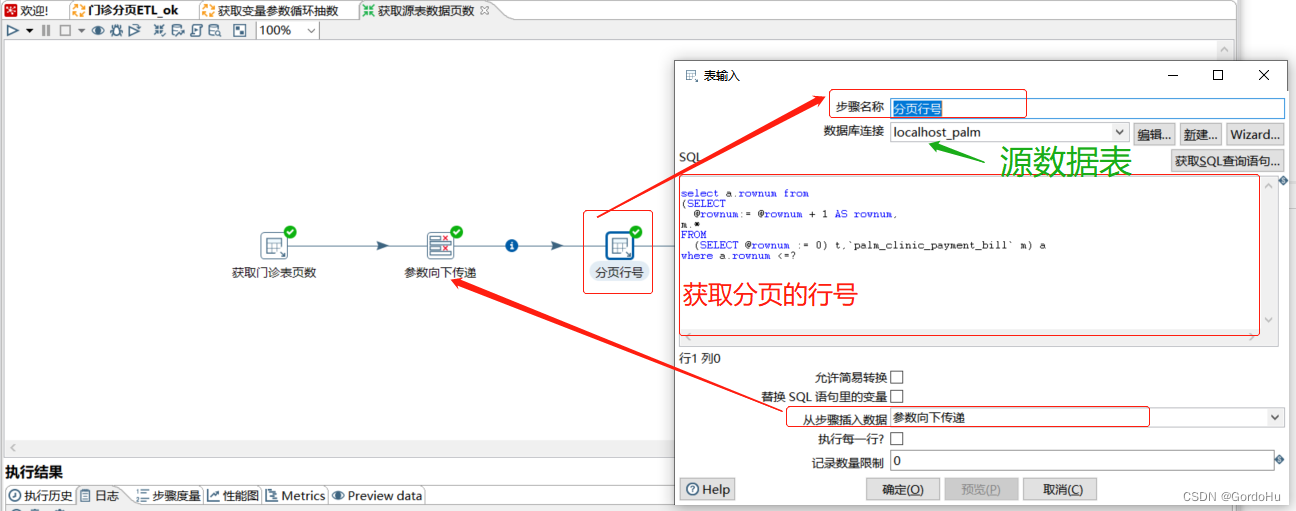
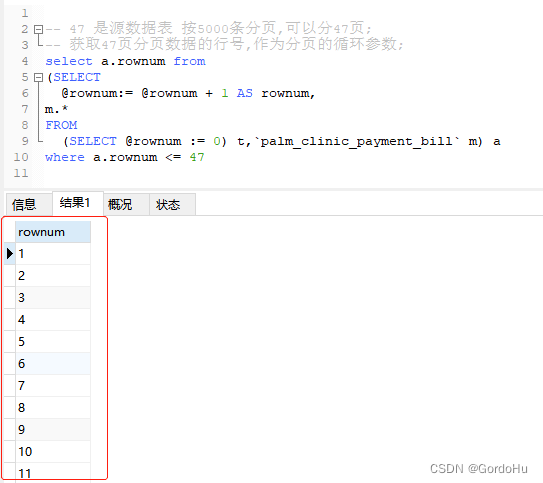
如下 第二步 ,第三个节点(分页行号):得到分页的数值,获取数值的行号,相当于拆解
select a.rownum from (SELECT @rownum:= @rownum + 1 AS rownum, m.* FROM (SELECT @rownum := 0) t,`palm_clinic_payment_bill` m) a where a.rownum <=?
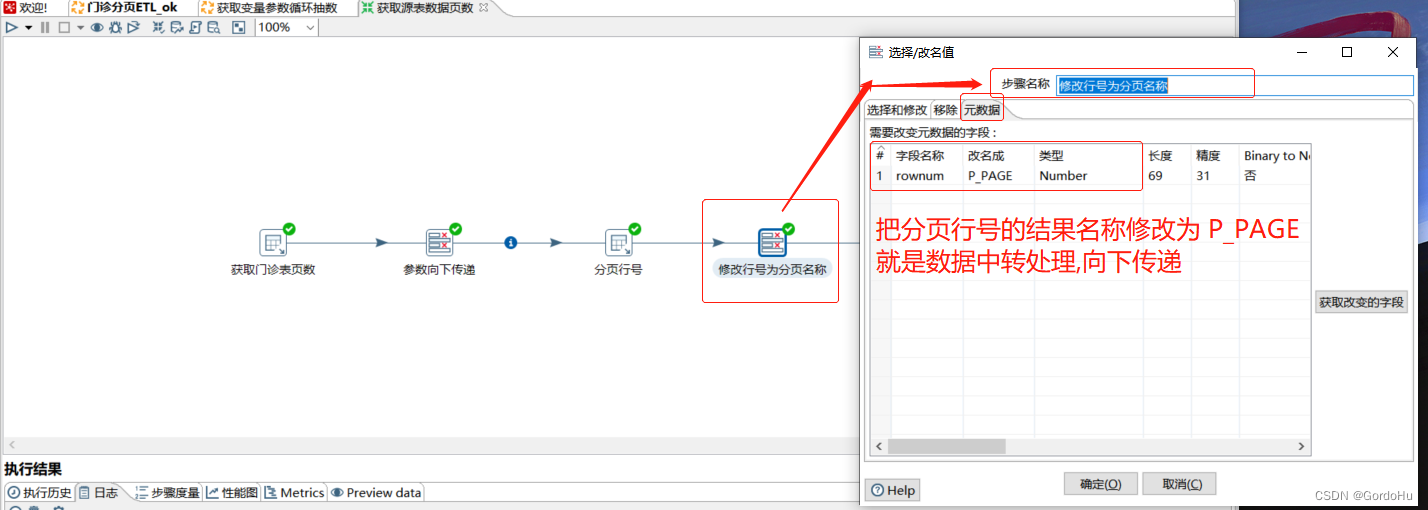
如下 第二步 ,第四个节点(修改行号为分页名称):
如下 第二步 ,第五个节点(表的页数列表):
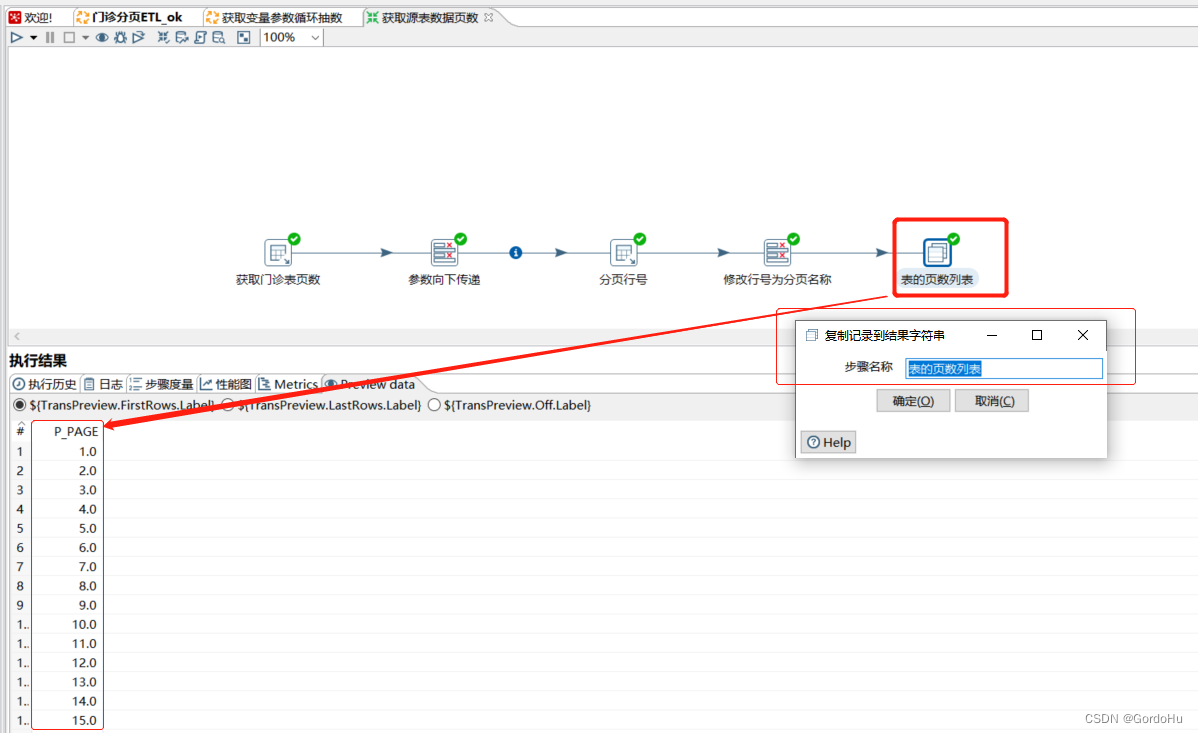
至此 第二步(获取源表数据页数.ktr)上面就得到了,分页的数据列表。用于后面的分页循环抽取做入参的条件。
- 详细第三步图文说明 :
第三步中 , (获取变量参数循环抽数).kjb。第三步图中,如下图示有两个转换;
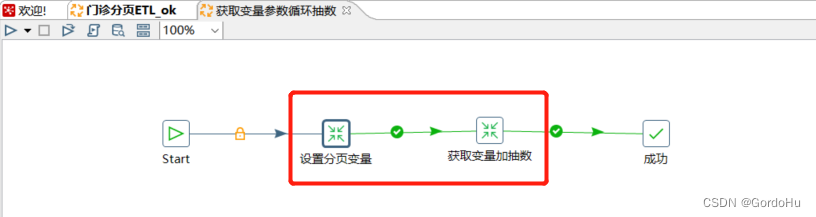
详细说一下 第三步中,第一个转换 (设置分页变量.ktr) 如下图示,有两个流程节点:
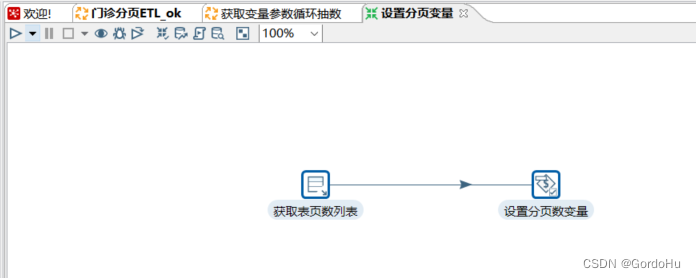
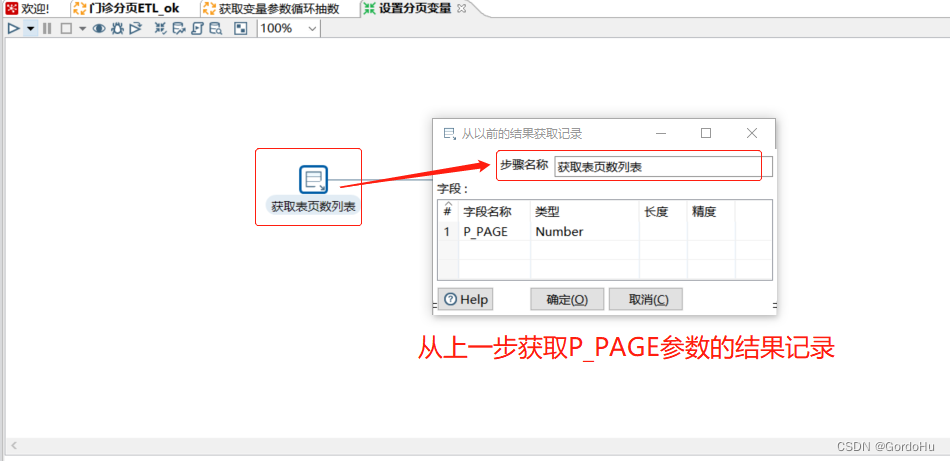
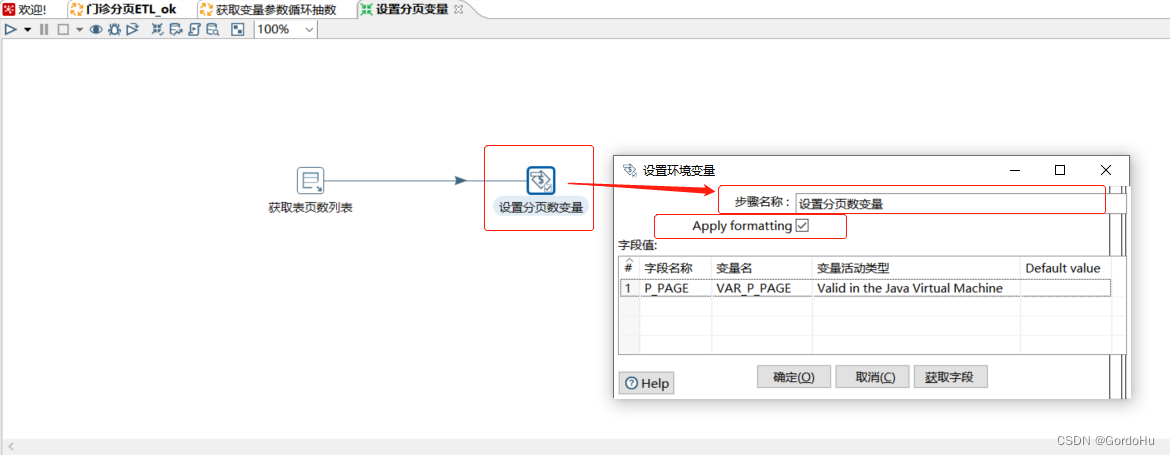
详细说一下 第三步中,第二个转换 (获取变量加抽数.ktr) 如下图示,有两个流程节点:
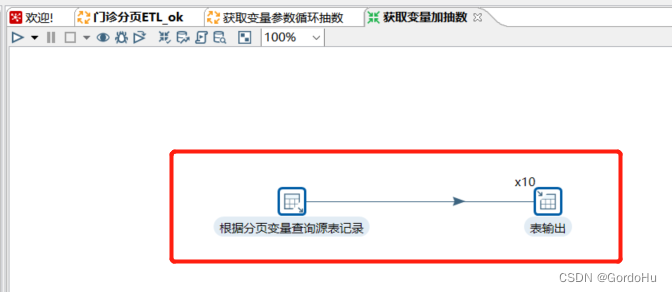
SELECT
P.*
FROM
(
SELECT
@rowno :=@rowno + 1 AS rownum,
O.*
FROM
(SELECT * FROM palm_clinic_payment_bill) O,
(SELECT @rowno := 0) t
) P
WHERE
rownum BETWEEN ((${VAR_P_PAGE} - 1) * 5000 + 1)
AND (${VAR_P_PAGE} * 5000);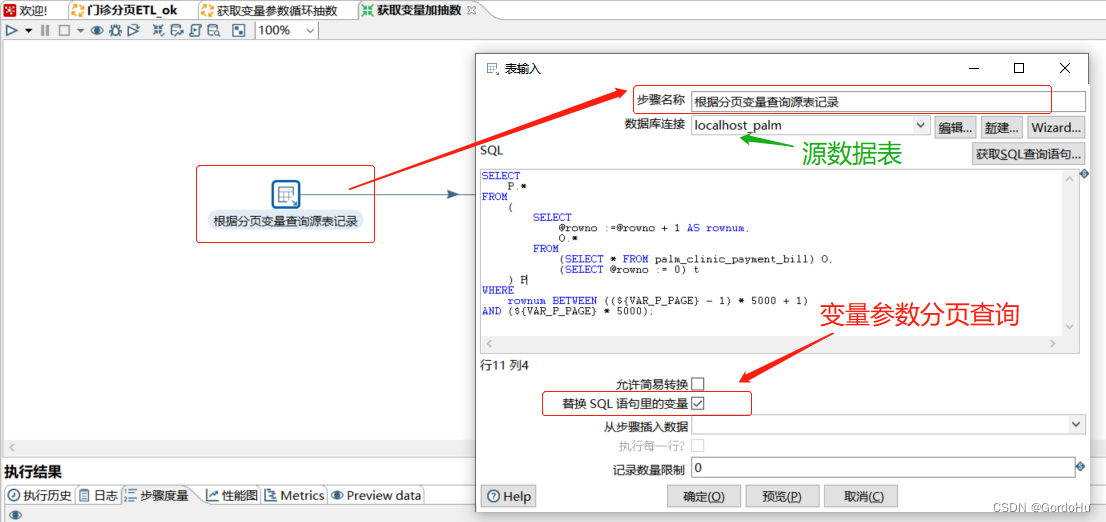
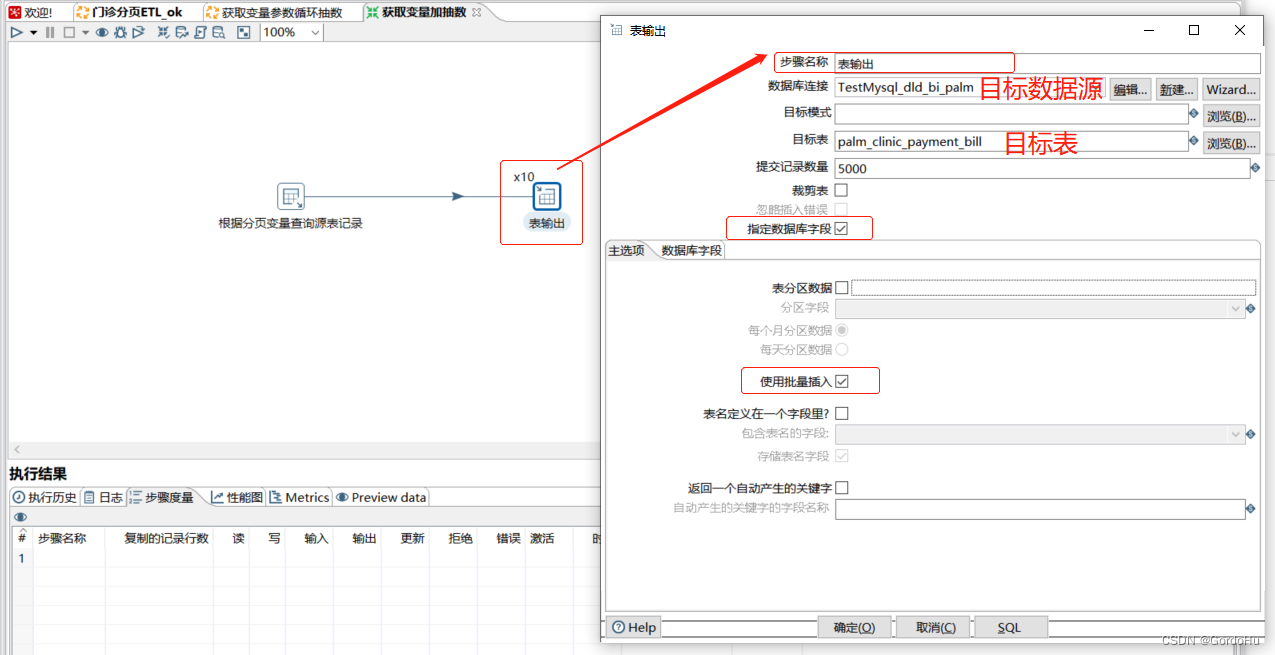
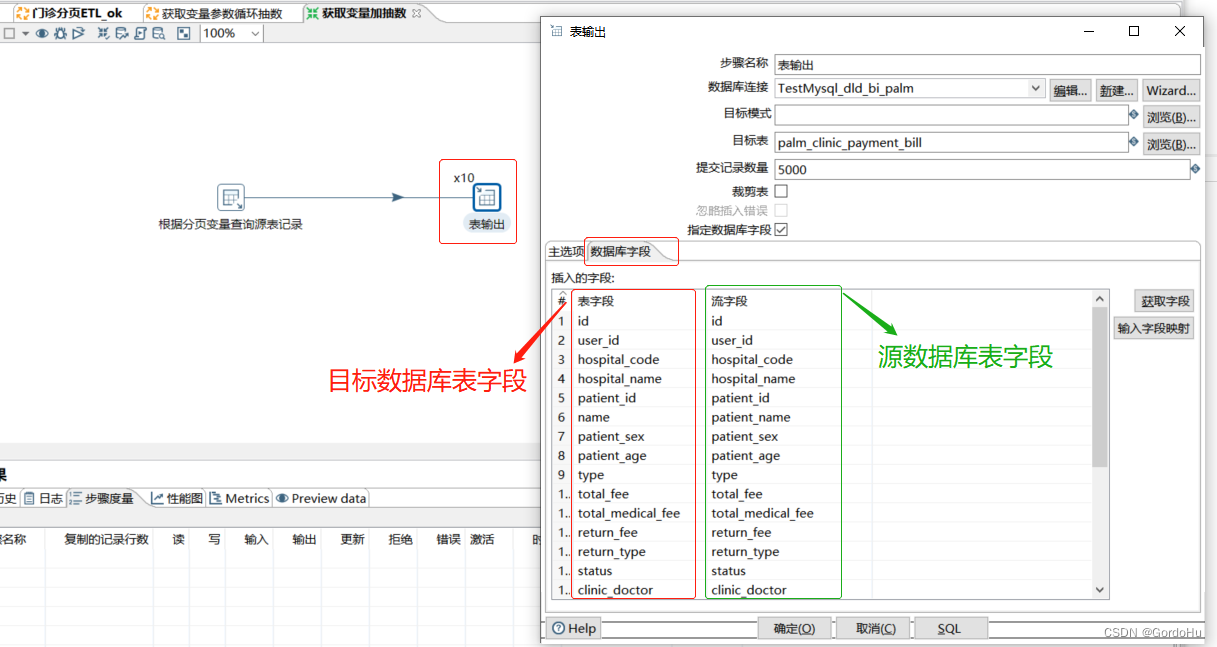
这里有个小技巧: 如果你获取不到字段,字段比较多,不用一个个去填写选择. 可以把上一步的分页查询的sql中的变量,替换成数字1,表示查询第一页,可以直接运行的sql, 然后再表输出的时候可以获取全部的字段,这样不用一个个选择字段了. 把数据库字段,表字段,流字段填写对应好之后,再把上一步的sql还原即可.
运行,跑起来即可

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)