爬虫:细谈为什么你爬取不到数据
细谈为什么你的爬虫程序爬取不到数据,理论上网页上看到,听到的,都应该能通过爬虫获取得到。
1. 前言
所谓“爬虫”,就是编写一定的代码程序来获取到网页端的一些数据信息并进行存储,理论上网页上看到,听到的,都应该能通过爬虫获取得到。目前网上相关文章只要涉及到爬虫技术的,大多数都会提到Python这门编程语言,其实,其他编程语言也不是不行,比如Java、JavaScript、C++等,但是这些编程语言相较于Python而言,并没有那么方便操作,因此,大多数开发者都喜欢用Python来编写爬虫程序,当然,小编我也是其中之一。所以下面的内容的都会和Python语言分不开,建议读者在有Python基础的前提下去阅读。在阅本篇文章之前,建议先去阅读一下下述文章。
- Python爬虫:什么是静态网页(数据),什么是动态网页(数据)
- Python爬虫:为什么你爬取不到网页数据
- Python爬虫:爬取动态网页数据“你”需要知道的事
- Python爬虫:从后端分析为什么你爬虫爬取不到数据
前面3篇写得的确有点水,因此本片文章也算是对它们的一个总结吧!第4篇文章真的推荐读者去阅读一下。
2. 网页的结构
一个网页离不开三个组成部分,分别为HTML+CSS+JavaScript,如果把一个网页当成一个房子来进行形容的话,HTML可以当作为房子的基本骨架(也就是没有没有装修的房子),CSS则是用来装饰房子的,此时你的房子就基本上可以住人并进行正常生活了,但是,有一天,你觉得房子该加个电梯方便上下楼,此时,这个加装的电梯就可以比拟JavaScript,至此,你的房子非常完美。
了解的网页的结构,如果想爬取一个网页的数据信息,你觉得你需要关注上述三者中哪些呢?HTML+JS吗?NO、NO、NO,你应该三者都关注,当然HTML+JS在大多数情况的确满足你的要求,但是有的情况下也需要关注一下CSS(比如使用特定字体来进行加密的情况,这个网页比如猫眼电影[可能网页更新了吧!])。
最初的网页看到的数据可能就是固定的,这种数据你直接使用requests模块访问网页链接就能得到;随着时间的发展,需求越来越多了,一个网页除了放一些固定的数据之外,还想放一些其他东西,此时你如果还是直接使用第一种方式来进行,虽然也可以得到数据,但是其中一部分你得不到,Why?因为这一部分数据使用动态技术渲染出来的(ajax),此时你需要做的就是找到这部分数据的对应接口,也就是到这下面去找,如下图: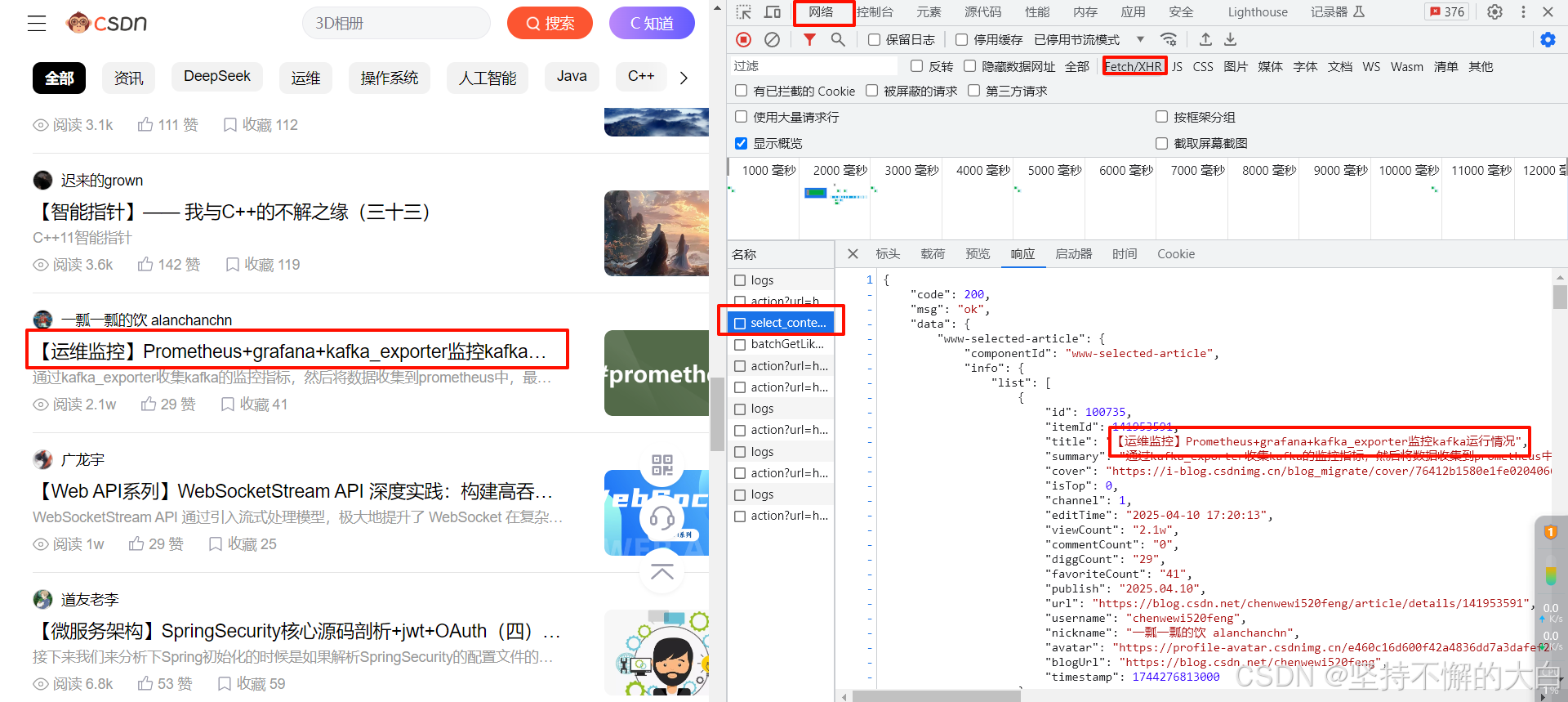
可能在JS或者XHR下面。
3. 基本总结
如果想爬取一个网页上的某个数据:
-
首先判断你爬取的数据是不是固定的(或者称为静态的),2种方式,在当前页面鼠标右键,选择查看源代码(或查看源文件),然后在源代码里看你想要的那个数据是否存在(Ctrl+F);另外就是鼠标右键点击检查,然后选择网络(network),找到全部(all),然后找到当前页面的那个链接(可能需要刷新一下当前页面,默认情况下就是第一个),看预览或者响应种是否有你需要的数据。如果有,你可以直接访问当前页面链接,可能需要添加一些请求头字段,然后使用对应的解析模块解析数据即可;如果没有,请看第2点。
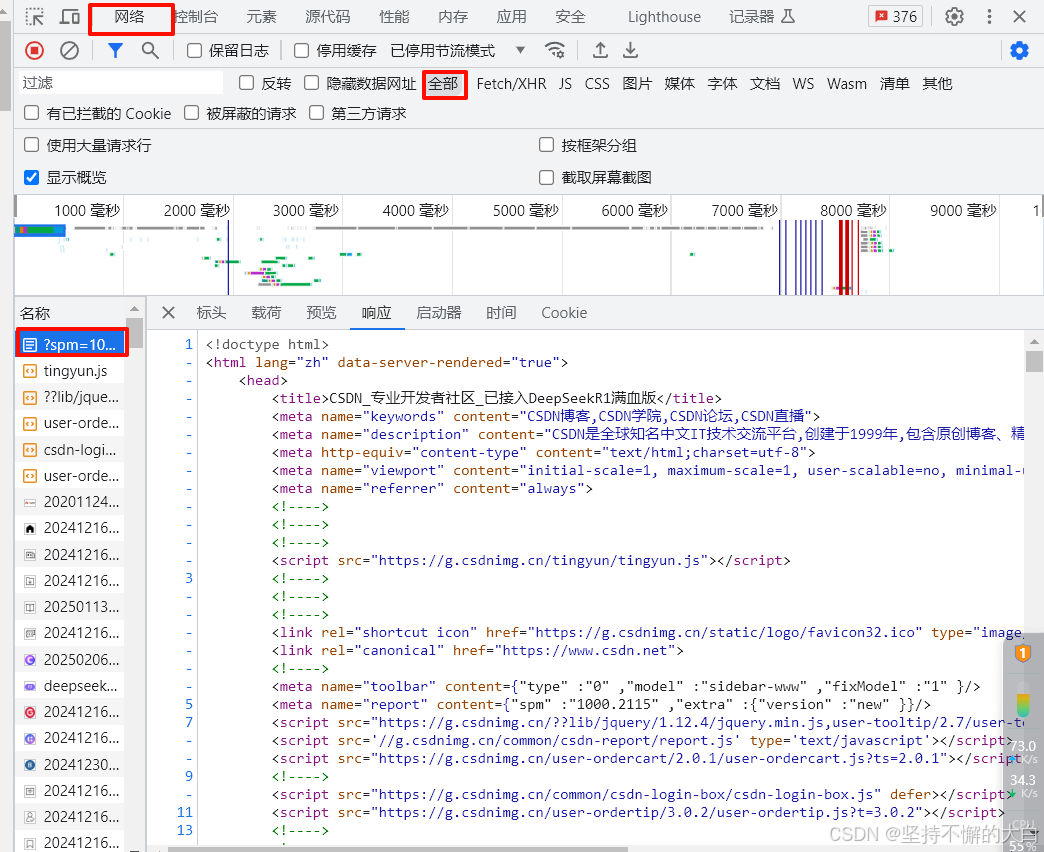
-
此时也就是在2点中网页的结构中提到的ajax技术,需要去找对应的接口。如果接口中字段很少,且你都能理解每个字段的意义,那么恭喜你,你想要的那个数据信息可以随心所欲地获取了(可能需要添加一些请求头或者其他);如果接口中的字段很多,并且字段有看上去加密的情况,这时,你需要的就是进行一定js逆向,搞清楚加密字段的加密原理,这个过程可能是非常煎熬的(如果你没有一定js基础的话)。当然,你也可以不去找到对应的接口,使用selenium等自动化模块去获取,虽然这种方式没有太高的要求,但是如果网页有一定的自动化检测,这种方式也是不行的(可能需要额外去处理一下吧,没有尝试过)。
-
如果你通过上述2种方式依旧没有找到对于的数据,你获取可以WS去找。ws也就是通过websocket技术使实现的一种实时更新数据的技术,通常直播网页的评论弹幕就是通过这种技术实现的。
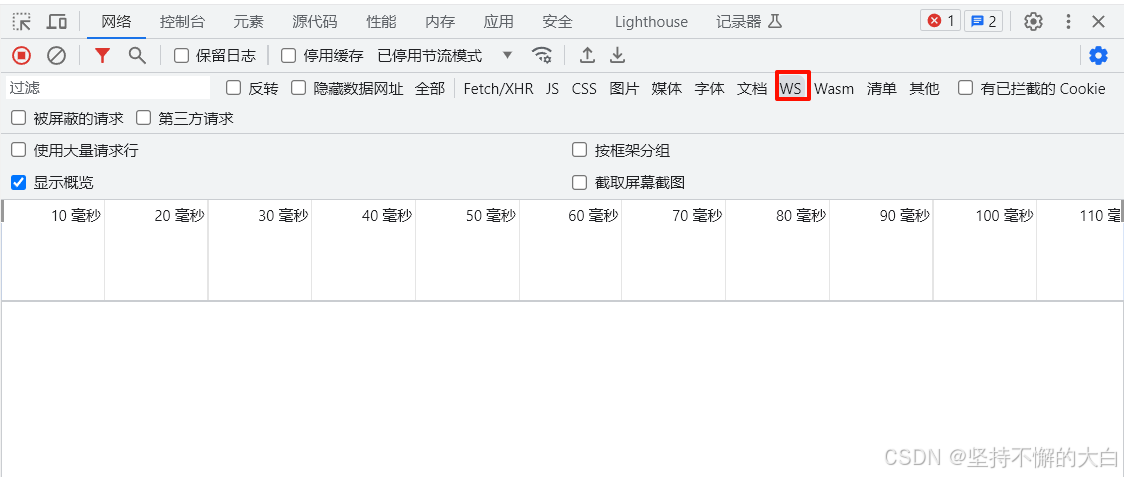
最后希望各位读者都能在不影响对于网站正常运行的情况下都能爬取得到自己想要的数据。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)