Docker存储驱动与数据卷详解
Docker提供了两种主要的数据存储方式:由存储驱动(Storage Driver)管理的镜像层和容器层,以及数据卷(Data Volume)。本文将详细解释这两种存储方式的工作原理、功能特点。
前言
`
Docker作为一种轻量级的容器技术,其核心优势之一就是数据管理的灵活性和高效性。Docker提供了两种主要的数据存储方式:由存储驱动(Storage Driver)管理的镜像层和容器层,以及数据卷(Data Volume)。本文将详细解释这两种存储方式的工作原理、功能特点,并提供示例说明。
存储驱动(Storage Driver)
存储驱动负责管理Docker镜像和容器的文件系统层。Docker镜像由多个只读层组成,而容器层是可写的。这些层通过联合文件系统(Union File System)技术堆叠在一起,形成容器的文件系统视图。
工作原理
-
分层结构:Docker容器由一个可写的容器层和多个只读的镜像层组成。新数据直接存放在容器层,修改现有数据时,会先从镜像层复制到容器层,然后修改后的数据保存在容器层中,而镜像层保持不变。
-
Copy-on-Write(CoW):这是一种优化策略,只有当数据被修改时,才会复制到新的层。这使得镜像和容器的创建、共享和分发变得非常高效。
-
存储驱动种类:Docker支持多种存储驱动,包括AUFS、Device Mapper、Btrfs、OverlayFS、VFS和ZFS等。每种驱动都有其特定的特性和适用场景。
下面是一个简化的Docker存储驱动工作流程图: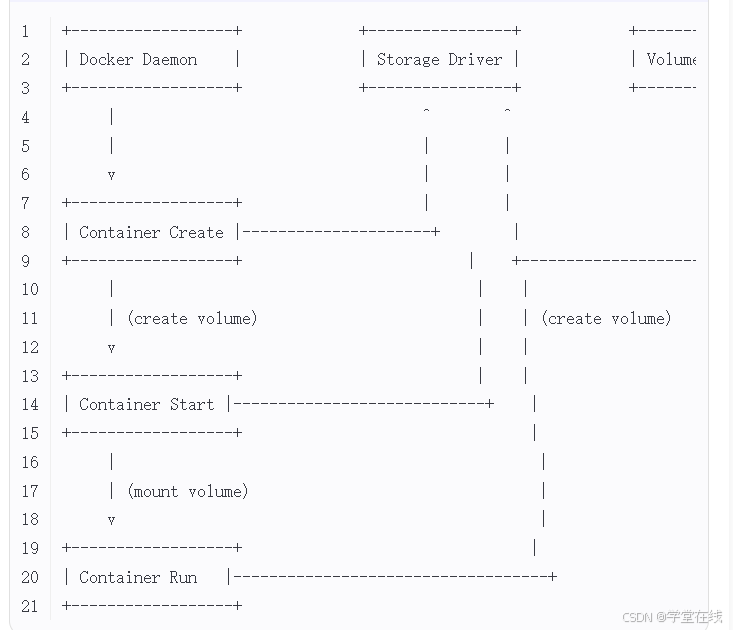
功能特点
-
高效共享:多个容器可以共享同一个镜像层,而每个容器都有自己的容器层,这样可以高效地共享和分发镜像。
-
隔离性:每个容器的更改只影响其自己的容器层,不影响其他容器和底层镜像。
-
性能:不同的存储驱动在性能上有所不同,例如
overlay2在文件级别操作,适合内存使用效率;而btrfs和zfs作为块级存储,适合写入密集型工作负载。
示例
假设我们有一个基于ubuntu:15.04镜像的容器,我们可以查看其使用的存储驱动:
docker info | grep -i "storage driver"
Storage Driver: overlay2
在Docker中,docker info 命令用于显示Docker系统的版本信息、配置和状态信息。而grep -i "storage driver" 是一个用于过滤输出内容的命令,它会显示所有包含“storage driver”的行,并且“-i”参数表示忽略大小写。
下面是对这些命令的注释:
# 使用docker info命令获取Docker系统的信息
docker info
# 使用管道将docker info的输出传递给grep命令
# grep命令用于搜索包含特定字符串的行
# -i 参数表示忽略大小写的搜索
# "storage driver" 是我们要搜索的字符串
docker info | grep -i "storage driver"
当执行上述命令时,输出结果会是这样的:
Storage Driver: overlay2
这行输出告诉我们当前Docker使用的存储驱动是overlay2。overlay2是一种存储驱动,它使用overlay文件系统来创建镜像层和容器层。它在性能和存储效率方面相比其他存储驱动(如aufs)有所改进,并且是Docker推荐的存储驱动之一,特别是在Linux系统上。
请注意,存储驱动的选择可能会根据你的Docker版本和宿主机操作系统的不同而有所差异。例如,在某些旧版本的Docker中,你可能看到的是aufs或其他存储驱动。而overlay2驱动需要宿主机的内核版本至少为3.18,并且需要相应的内核配置支持。
这表明该容器使用的是overlay2存储驱动。
数据卷(Data Volume)
数据卷是Docker宿主机文件系统中的目录或文件,可以被挂载到容器的文件系统中,用于数据的持久化和共享。
工作原理
-
挂载机制:数据卷可以被多个容器挂载,实现数据的共享和持久化。即使容器被删除,数据卷中的数据也不会丢失。
-
数据管理:数据卷提供了一种将容器数据与容器生命周期解耦的方式,使得数据管理更加灵活。
Docker数据卷工作原理图可以表示为:
功能特点
-
数据持久化:数据卷中的数据独立于容器生命周期,即使容器被删除,数据也不会丢失。
-
数据共享:多个容器可以共享同一个数据卷,实现数据的共享。
-
性能:数据卷直接操作宿主机的文件系统,通常比存储驱动的容器层有更好的性能。
示例
假设我们需要在两个容器之间共享数据,可以创建一个数据卷并将其挂载到两个容器中:
docker volume create myvolume
docker run -d --name container1 -v myvolume:/data busybox
docker run -d --name container2 -v myvolume:/data busybox
下面是对Docker命令的详细注释:
# 创建一个新的Docker数据卷,命名为myvolume
docker volume create myvolume
# 运行一个新的容器,命名为container1,并在后台运行(-d)
# 使用busybox镜像作为容器的基础
# 将名为myvolume的数据卷挂载到容器的/data目录
docker run -d --name container1 -v myvolume:/data busybox
# 运行另一个新的容器,命名为container2,并在后台运行(-d)
# 同样使用busybox镜像作为容器的基础
# 将同一个名为myvolume的数据卷挂载到容器的/data目录
docker run -d --name container2 -v myvolume:/data busybox
这些命令执行的具体步骤如下:
-
创建数据卷:
docker volume create myvolume:这条命令创建了一个名为myvolume的新数据卷。数据卷是独立于容器生命周期的,这意味着即使容器被删除,数据卷中的数据也会被保留。
-
运行容器并挂载数据卷:
docker run -d --name container1 -v myvolume:/data busybox:这条命令启动了一个名为container1的新容器,并指定使用busybox镜像。-d标志表示容器将在后台运行。-v myvolume:/data参数将之前创建的数据卷myvolume挂载到容器内的/data目录。这样,任何对/data目录的更改都会反映在数据卷中,并且会持久化存储,即使容器被删除。docker run -d --name container2 -v myvolume:/data busybox:这条命令与上一条类似,但是创建的容器名为container2。它也使用相同的数据卷myvolume,挂载到相同的目录/data。这意味着container1和container2可以共享存储在myvolume中的数据。
通过这种方式,Docker允许多个容器共享和持久化数据,这对于需要跨多个容器共享数据的应用非常有用。
总结
存储驱动和数据卷是Docker中两种重要的数据管理方式。存储驱动通过镜像层和容器层的堆叠,实现了容器数据的高效共享和隔离;而数据卷则提供了数据持久化和共享的机制。根据具体的应用场景和需求,合理选择和使用这两种存储方式,可以最大化地发挥Docker的优势。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)