山东大学软件学院2024并行计算回忆版及答案
在更新操作执行之前,目录会通知这些的缓存控制器,使它们的缓存中对应的缓存行失效(Invalid)。这样,当核心1下一次访问变量x时,会发现其缓存中的x是无效的,从而重新从主内存或核心0的缓存中获取最新的值。按列访问意味着内存访问不是连续的,内存地址是跳跃的,导致缓存行的利用率较低,每次访问新的行时,可能需要重新加载缓存行,会让Cache命中率减低,降低运算效率。多发射或硬件多线程呢?在多处理器系统
题目是这些题目,顺序不能保证。都是复习PPT里的原题,所以学弟学妹一定要好好听复习课,必要可以录音,然后把复习PPT上的所有题目都背下来。
1.当讨论矩阵–向量乘法时,我们通常假设m 和n,即矩阵的行数和列数,都能够被t整除,t是线程的个数。但是,如果m和n不满足能被t整除的条件、那么用什么公式来分配数据?
答案:

2.集合通信与点对点通信的区别
①集合通信是指所有进程都调用相同的集合函数来进行通信(否则导致程序挂起或崩溃);
而点对点通信则是通过标签和通信器进行匹配。
②在集合通信中,所有进程必须传递兼容的参数,并且output_data_p参数仅在目标进程上使用(但是,所有进程仍然需要传递与output_data_p相对应的实际参数,即使它只是NULL)。
③集合通信不适用标签,仅基于通信其和调用顺序匹配消息。
相反,在点对点通信中,消息通过标签和通信器进行匹配,而不是调用顺序。
3.在冯·诺依曼系统中加入缓存和虚拟内存改变了它作为SISD系统的类型吗?如果加人流水线呢?多发射或硬件多线程呢?

4.一个14分量的向量在三个进程之间的不同划分(假设均分),分别采用块分区、循环分区、块循环分区。(PPT上是12分量)
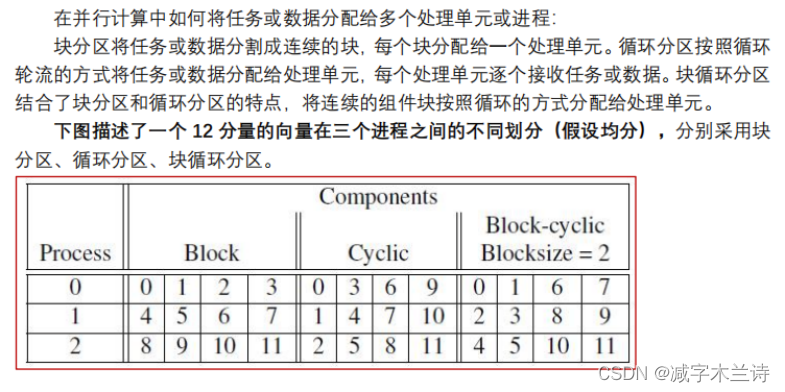
5.Cache循环效率。以下代码分别表示什么?(按行访问、按列访问)哪个快?为什么?

按行访问快,因为C语言是行主序,多维数组在内存中也是一个超大的一维数组,每次都按高速缓存行可容纳的数量换入换出。
按行访问意味着访问是连续的,符合缓存行的预取机制,即一旦一行的第一个元素被访问,后续的元素很可能已经在缓存中了,减少了内存访问时间。
按列访问意味着内存访问不是连续的,内存地址是跳跃的,导致缓存行的利用率较低,每次访问新的行时,可能需要重新加载缓存行,会让Cache命中率减低,降低运算效率。
实际分析中可以分析一下置换次数,来得出效率高低的结论【课本15】
6.消除循环依赖与并行化循环

答案:

7.Cache一致性
(1)什么是cache一致性,两种方法及原理
在多处理器系统中,确保各处理器的缓存中的数据是一致的,即各处理器对共享内存的访问能够正确反映最新的数据状态。
两种方法:监听式cache一致性与目录式cache一致性
①监听式cache一致性Snooping Cache Coherence
监听式缓存一致性依赖于一个共享的总线和核心之间的通信。
所有处理器的核心都连接到一个共享的总线,总线上传输的任何信号都可以被所有连接到总线的核心检测到。当某个核心(例如核心0)更新其缓存中某个变量(例如变量x)的副本时,会通过总线将该更新信息广播出去,所有连接到总线的核心都能够接收到这个更新信息。核心1可以通过嗅探总线来监听其他核心的更新操作。
如果核心1检测到核心0更新了变量x,会将其缓存中存储的变量x的副本标记为无效(Invalid)。这样,当核心1下一次访问变量x时,会发现其缓存中的x是无效的,从而重新从主内存或核心0的缓存中获取最新的值。
②目录式cache一致性Directory Based Cache Coherence
使用一个集中式数据结构(即目录)来存储每个缓存行的状态。当一个变量被更新时,会查询目录,并使拥有该变量缓存行的核心的缓存控制器失效。
当某个核心需要更新一个变量时,首先会查询目录以获取该变量对应的缓存行状态。目录会列出哪些核心的缓存中存有该缓存行。在更新操作执行之前,目录会通知这些的缓存控制器,使它们的缓存中对应的缓存行失效(Invalid)。这些核心在下一次访问该变量时,会检测到改行无效,从而从主内存或者其他核心的缓存中获取最新的数据。
(2)Cache伪共享是什么
线程之间没有共享任何变量(但是共享了同一个缓存行),但是它们访问主存的行为看起来好像它们共享了一个变量,这种情况称为伪共享。
会导致cache一致性协议频繁触发,使缓存行频繁失效-加载,在多个处理器之间来回传输,增加总流量和延迟,最终导致性能下降。
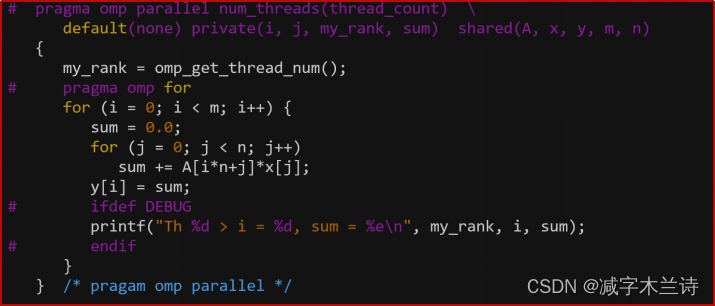
8.OpenMP并行化解决矩阵向量乘法中的Cache问题
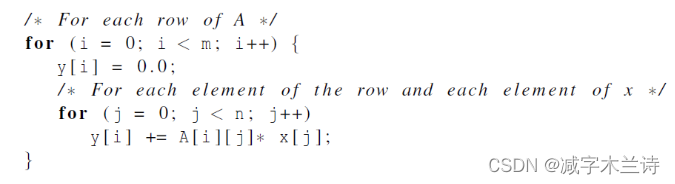
修改上面的矩阵-向量乘法程序,使得每个线程在for i循环时对它要处理的向量y的元素采用私有存储。当一个线程计算出它私有的y中的元素后,它应该将这些私有的变量复制到共享变量中。
答案:
9.奇偶排序算法性能优化
请说明代码存在哪些性能问题并进行优化。
答案:

原始版本在每个迭代阶段分别处理奇数位和偶数位的元素,使用了OpenMP实现并行化,但是由于在并行区域中嵌套了循环,在奇数位和偶数位元素的处理上采用了不用的并行区域,会导致线程的负载不均衡和额外的线程创建开销。
修改后的代码将OpenMP并行区域移除了循环外,每个迭代阶段只创建一次并行区域,减少了额外的线程创建开销。
将迭代变量 phase 和临时变量tmp声明为私有变量,确保每个线程都有自己的拷贝,避免了数据竞争。
将奇数位和偶数位元素的处理合并到同一个循环中,并通过 if-else 条件来区分处理不同的情况。这样可以避免循环嵌套,简化了代码逻辑。
调整了循环的起始位置和步长,分别处理奇数位和偶数位的元素。
10.CUDA_REDUCE
源代码有哪些性能问题,并且改进。
有点懒,这位学长/学姐的回忆版里有这个题目,可以来这里看。
山东大学软件学院2022-2023第二学期多核平台上的并行计算期末考试(回忆版)_山东大学并行计算期末考试-CSDN博客

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)