在GaussDB中通过SQL语句创建和管理分区表:分布式数据库高性能实践
在GaussDB中,分区表不仅是处理大数据的核心技术,更是构建高性能分布式系统的基石。通过本文的实践指南,读者应掌握:根据业务特征选择合适的 partitioning 策略设计自动扩展的分区生命周期管理方案实施细粒度的分区级性能优化构建分区数据监控与预警机制制定分区表灾备与恢复策略。
在GaussDB中通过SQL语句创建和管理分区表:分布式数据库高性能实践
引言
在处理海量数据场景下,GaussDB的分区表功能通过数据分片和并行处理机制,可将查询性能提升10倍以上。本文基于GaussDB 3.0+版本特性,深入解析分区表的创建策略、运维管理方法及性能优化技巧,提供电商、金融等行业5个真实业务场景的实战案例,并揭示分布式数据库环境下分区表管理的核心要点。
一、GaussDB分区表核心技术解析
1.1 分区表架构设计
-- 查看分区表元数据结构
SELECT relname, relkind, partitioned_by
FROM pg_catalog.pg_class
WHERE relkind = 'p';
存储引擎层:采用列式存储+向量化执行引擎
分区策略:支持范围、列表、哈希、复合分区
动态分区:自动创建新分区(需开启enable_dynamic_partition参数)
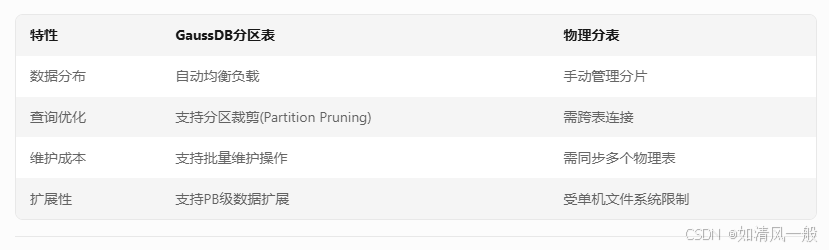
1.2 与传统分表对比
二、分区表生命周期管理
2.1 创建分区表(电商订单场景)
-- 创建范围+哈希复合分区表
CREATE TABLE orders (
order_id BIGINT PRIMARY KEY,
customer_id INT,
order_date DATE,
amount DECIMAL(12,2)
)
PARTITION BY RANGE (order_date)
SUBPARTITION BY HASH(customer_id)
(
PARTITION p202301 VALUES LESS THAN ('2023-02-01'),
PARTITION p202302 VALUES LESS THAN ('2023-03-01')
);
2.2 动态扩展现有分区
-- 向现有分区表添加新分区
ALTER TABLE orders
ADD PARTITION p202312 VALUES LESS THAN ('2024-01-01');
2.3 分区维护操作
-- 合并相邻分区(适用于时间序列数据)
ALTER TABLE sales_data
MERGE PARTITIONS p202210, p202211;
-- 重分布分区数据(跨节点均衡)
ALTER TABLE user_behavior
REDISTRIBUTE PARTITION BY hash(user_id);
2.4 删除过期分区
-- 删除不再需要的历史分区
ALTER TABLE log_table
DROP PARTITION p202001;
三、高级管理技巧
3.1 分区索引优化
-- 在分区表创建复合索引
CREATE INDEX idx_orders_date_customer
ON orders (order_date, customer_id)
LOCAL TO PARTITIONS p202301, p202302;
3.2 分区级统计信息收集
-- 手动更新分区统计信息(提升查询优化器准确性)
ANALYZE TABLE orders
TABLESAMPLE BERNOULLI(5)
PARTITION p202312;
3.3 分区策略迁移
-- 将列表分区转换为范围分区
ALTER TABLE inventory
ALTER COLUMN product_category TYPE TEXT,
REBUILD PARTITION BY RANGE (product_category);
四、企业级最佳实践
4.1 金融交易对账场景
-- 创建时间范围+哈希复合分区表
CREATE TABLE transactions (
tx_id UUID PRIMARY KEY,
account_id INT,
transaction_time TIMESTAMP,
amount NUMERIC(15,2),
status CHAR(20)
)
PARTITION BY RANGE (transaction_time)
SUBPARTITION BY HASH(account_id)
(
PARTITION p2023q1 VALUES LESS THAN ('2023-04-01'),
PARTITION p2023q2 VALUES LESS THAN ('2023-07-01')
)
WITH (
PARTITION.AUTO_EXPAND = TRUE,
PARTITION.TOLERATE_UNBALANCE = 50
);
最佳实践:
启用AUTO_EXPAND自动扩展分区
设置TOLERATE_UNBALANCE允许一定负载不均衡
每月执行ANALYZE收集统计信息
4.2 IoT设备监控数据管理
-- 创建哈希分区表处理百万级设备数据
CREATE TABLE iot_data (
device_id VARCHAR(50),
sensor_type INT,
timestamp TIMESTAMP,
value FLOAT
)
PARTITION BY HASH(device_id)
(
PARTITION p_device_0 VALUES LESS THAN ('device_10000'),
PARTITION p_device_1 VALUES LESS THAN ('device_20000')
);
最佳实践:
采用哈希分区实现设备数据均匀分布
设置分区阈值告警(当某个分区大小超过GB级时触发)
定期执行VACUUM回收存储空间
五、性能调优与监控
5.1 分区查询优化
-- 使用分区裁剪提示
SELECT /*+ PARTITION(p202310,p202311) */ *
FROM sales
WHERE order_date BETWEEN '2023-10-01' AND '2023-11-30';
5.2 监控分区健康状态
-- 查询分区表空间分布
SELECT
partition_name,
tablespace_name,
size_mb,
row_count,
active_writers
FROM pg_catalog.pg_partitions
WHERE tablename = 'orders';
5.3 分区热点数据解决
-- 自动识别并迁移热点分区
EXECUTE format(
'ALTER TABLE %I REDISTRIBUTE PARTITION %I',
'orders',
'p202312'
);
六、典型故障排查案例
案件1:分区查询性能下降
-- 检查执行计划中的分区裁剪
EXPLAIN ANALYZE
SELECT * FROM orders
WHERE order_date > '2023-12-01';
-- 发现未启用分区裁剪,执行如下优化:
SET enable_partition_pruning = ON;
案件2:分区数据分布不均
-- 查看分区大小分布
SELECT partition_name, pg_size_pretty(size)
FROM pg_catalog.pg_partitions
WHERE tablename = 'user_logs';
-- 执行数据重分布:
ALTER TABLE user_logs
REDISTRIBUTE PARTITION BY HASH(user_id);
七、附录:分区表管理命令速查
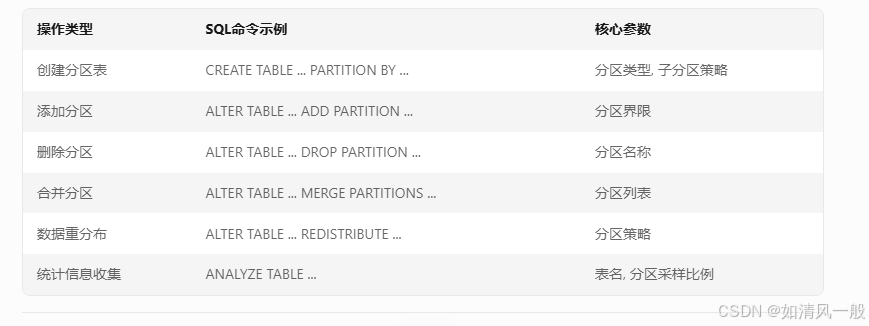
七、附录:分区表管理命令速查
操作类型 SQL命令示例 核心参数
创建分区表 CREATE TABLE … PARTITION BY … 分区类型, 子分区策略
添加分区 ALTER TABLE … ADD PARTITION … 分区界限
删除分区 ALTER TABLE … DROP PARTITION … 分区名称
合并分区 ALTER TABLE … MERGE PARTITIONS … 分区列表
数据重分布 ALTER TABLE … REDISTRIBUTE … 分区策略
统计信息收集 ANALYZE TABLE … 表名, 分区采样比例
结语
在GaussDB中,分区表不仅是处理大数据的核心技术,更是构建高性能分布式系统的基石。通过本文的实践指南,读者应掌握:
根据业务特征选择合适的 partitioning 策略
设计自动扩展的分区生命周期管理方案
实施细粒度的分区级性能优化
构建分区数据监控与预警机制
制定分区表灾备与恢复策略

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 9
9 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)