Doris数据库
3.5 Doris的数据模型
Doris的数据模型主要分为3类:
Aggregate:聚合模型
Uniq:去重模型
Duplicate:明细模型
3.5.1 Aggregate模型
表中的列按照是否设置了 AggregationType,分为 Key(维度列)和 Value(指标列)。没有设置 AggregationType 的称为 Key,设置了 AggregationType 的称为 Value。
当我们导入数据时,对于 Key 列相同的行会聚合成一行,而 Value 列会按照设置的AggregationType 进行聚合。AggregationType 目前有以下四种聚合方式:
➢ SUM:求和,多行的 Value 进行累加。
➢ REPLACE:替代,下一批数据中的 Value 会替换之前导入过的行中的 Value。就是相当于给数据做了一个group by key order by 时间然后取了最新一条的数据。
REPLACE_IF_NOT_NULL :当遇到 null 值则不更新。
➢ MAX:保留最大值。
➢ MIN:保留最小值。
数据的聚合,在Doris中有如下三个阶段:
(1)每一批次数据导入的 ETL 阶段。该阶段会在每一批次导入的数据内部进行聚合。
(2)底层 BE 进行数据 Compaction 的阶段。该阶段,BE 会对已导入的不同批次的数据进行进一步的聚合。
(3)数据查询阶段。在数据查询时,对于查询涉及到的数据,会进行对应的聚合。
ETL 阶段在 Doris 数据导入中的作用
当数据通过 Stream Load、Broker Load、Routine Load 等方式批量导入 Doris 时,会经历以下阶段:
Extract(提取):从数据源(如 Kafka、HDFS、本地文件等)读取原始数据。
Transform(转换 & 聚合):
数据清洗:过滤无效数据(如 NULL 值、格式错误的数据)。
数据转换:调整数据类型、标准化数据格式(如时间戳转换)。
预聚合(关键步骤):
如果表是 Aggregate Key 表 或 Unique Key 表,Doris 会在 ETL 阶段按 Key 对数据进行预聚合(例如 SUM、COUNT、MAX 等)。
例如,原始数据中可能有多条相同 Key 的记录,ETL 阶段会合并这些记录,只保留聚合后的结果,减少最终存储的数据量。
Load(加载):将处理后的数据写入 Doris 的存储引擎(Segment 文件)。
数据在不同阶段的聚合程度可能不一样,就是在我们数据还没聚合完的时候我们可能就会进行数据的查询,这个时候查询就会出先可能有重复的数据,为了避免这个问题doris在进行数据查询的时候,他一定进行聚合,就是保证查询到的数据一定是聚合后的。(兜底措施)
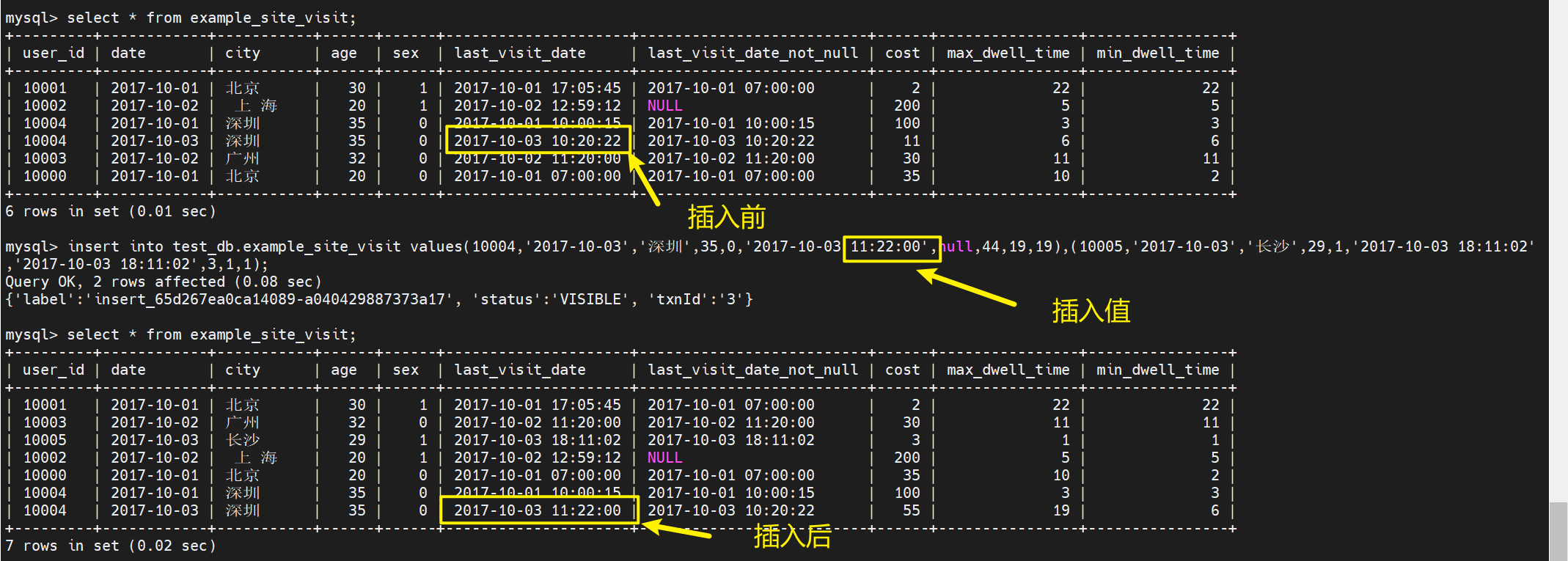
实战案例一
插入语句:

插入结果:

前两条合并为一条了,就是我们所说的聚合,最后两条没有聚合是因为前方的key值有不一样的。必须所有的key列一致才能聚合
实战案例二

实战案例三
3.5.2 Uniq模型
在某些多维分析场景下,用户更关注的是如何保证 Key 的唯一性,即如何获得 Primary Key 唯一性约束。因此,我们引入了 Uniq 的数据模型。该模型本质上是聚合模型的一个特例,也是一种简化的表结构表示方式。
1)建表
CREATE TABLE IF NOT EXISTS test_db.user
(
`user_id` LARGEINT NOT NULL COMMENT "用户 id",
`username` VARCHAR(50) NOT NULL COMMENT "用户昵称",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`phone` LARGEINT COMMENT "用户电话",
`address` VARCHAR(500) COMMENT "用户地址",
`register_time` DATETIME COMMENT "用户注册时间"
)
UNIQUE KEY(`user_id`, `username`)
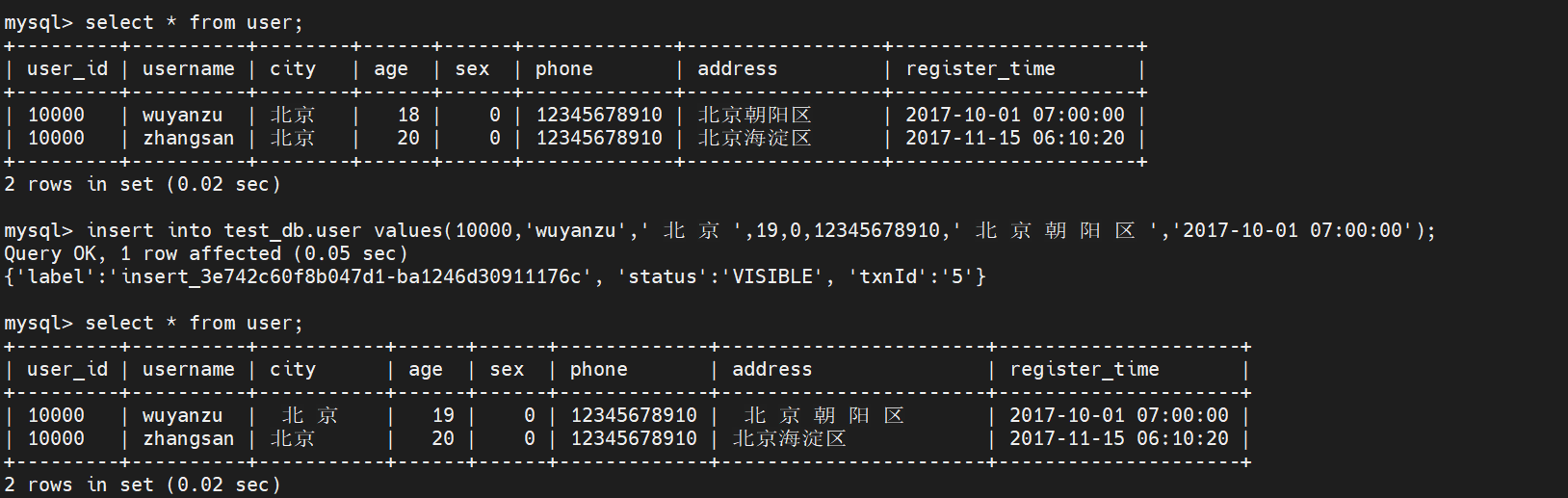
DISTRIBUTED BY HASH(`user_id`) BUCKETS 10; 2)插入数据
insert into test_db.user values\
(10000,'wuyanzu',' 北 京 ',18,0,12345678910,' 北 京 朝 阳 区 ','2017-10-01
07:00:00'),\
(10000,'zhangsan','北京',20,0,12345678910,'北京海淀区','2017-11-15
06:10:20');
insert into test_db.user values\
(10000,'wuyanzu',' 北 京 ',19,0,12345678910,' 北 京 朝 阳 区 ','2017-10-01
07:00:00'),\ 结果
3.5.3 Duplicate 模型
在某些多维分析场景下,数据既没有主键,也没有聚合需求。Duplicate 数据模型可以满足这类需求。数据完全按照导入文件中的数据进行存储,不会有任何聚合。即使两行数据完全相同,也都会保留。 而在建表语句中指定的 DUPLICATE KEY,只是用来指明底层数据按照那些列进行排序。
1)建表
CREATE TABLE IF NOT EXISTS test_db.example_log
(timestamp DATETIME NOT NULL COMMENT "日志时间",
type INT NOT NULL COMMENT "日志类型",
error_code INT COMMENT "错误码",
error_msg VARCHAR(1024) COMMENT "错误详细信息",
op_id BIGINT COMMENT "负责人 id",
op_time DATETIME COMMENT "处理时间"
)
DUPLICATE KEY(timestamp, type)
DISTRIBUTED BY HASH(timestamp) BUCKETS 10;2)插入数据
insert into test_db.example_log values\
('2017-10-01 08:00:05',1,404,'not found page', 101, '2017-10-01
08:00:05'),\
('2017-10-01 08:00:05',1,404,'not found page', 101, '2017-10-01
08:00:05'),\
('2017-10-01 08:00:05',2,404,'not found page', 101, '2017-10-01
08:00:06'),\
('2017-10-01 08:00:06',2,404,'not found page', 101, '2017-10-01
08:00:07');3)查看表
select * from test_db.example_log;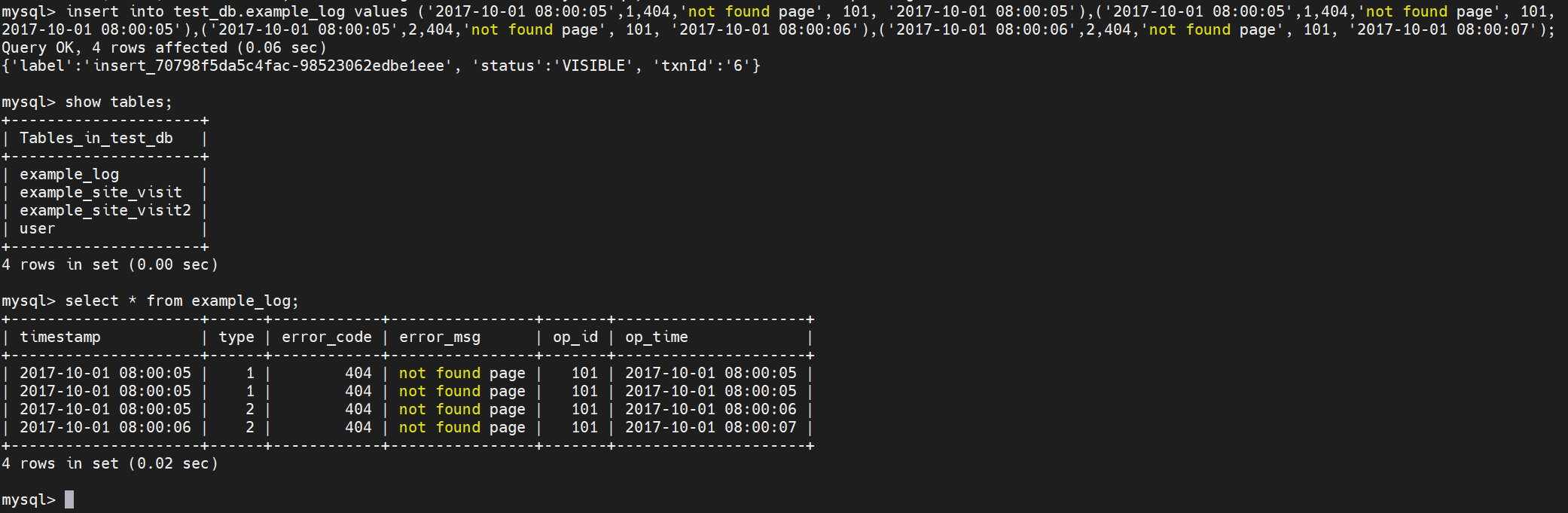

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)