(一)python抓取电影票房数据
·
# 通过request请求到电影票房的网页
text = requests.get("http://www.cbooo.cn/year?year=2008).text
# 取出该网址的源代码
main_page = BeautifulSoup(text,"html.parser")
# 使用BeautifulSoup对text进行解析
# "html.parser"表示使用的是html的解析器,用html的规则去解析text文本
进入代码所示网址后,对网页右键点击检查

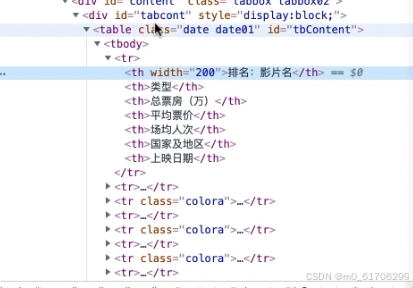
每一个tr都是一行数据

table = main_page.find("table",attrs="id":"tbContent")
# 找标签table
# 通过id的tbContent来防止页面中的其他table来干扰
f = open("电影票房.csv",mode="a")
# 打开一个文件用来保存未来的数据
# mode="w"表示写write,但会把上一次爬取的数据覆盖掉 ; mode="r"表示读read
# mode="a"可以把之前爬取的数据保留
trs = table.find_all("tr")
# table.find找的是一个标签,一般只返回第一个
# table.find_all找一堆标签
# 把tr所代表的每一行数据拿到trs
for tr in trs:
# 返回了一堆tr,通过for tr in trs循环,拿到每一个tr
lst = tr.find_all("td")
# 找到每一个td,装到列表里
if len(lst) != 0:
# 如果数据长度不为0(正好去掉了第一行的标题行的数据,因为第一行的数据只有th,没有td)
for td in lst: # 拿到每一个td
f.write(td.text) # 拿到td标签中的文本信息
f.write(,) # 每一个信息用逗号隔开
f.write("\n") # 换行
 tr里面有有许多元素td
tr里面有有许多元素td

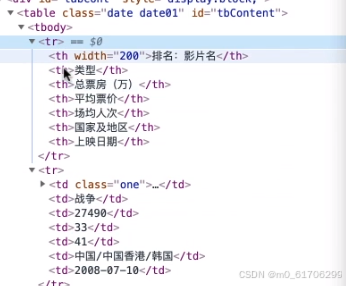
但第一行也就是标题行,点开之后没有td,只有th
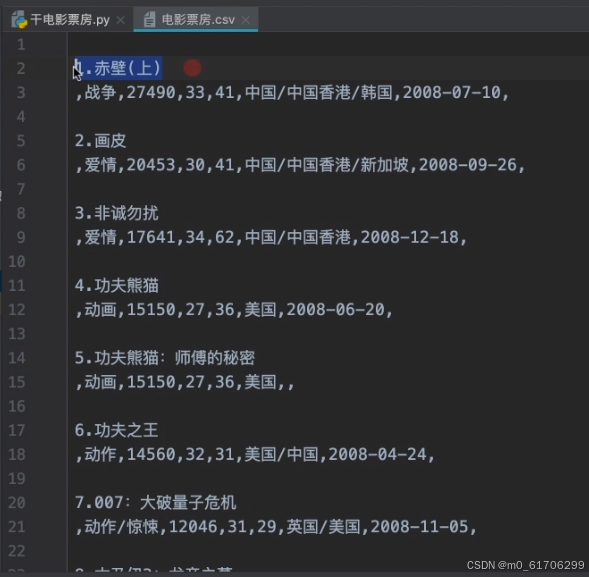
最终代码运行成功会出现"电影票房.csv"的文件,打开就是上述内容
但格式还不够标准
所以要改成下述代码
f.write(td.text.strip())
# 拿到td标签中的文本信息
# strip()默认去掉左右两侧的空白(空格、换行符、制表符)table = main_page.find("table",attrs="id":"tbContent")
# 找标签table
# 通过id的tbContent来防止页面中的其他table来干扰
f = open("电影票房.csv",mode="a")
# 打开一个文件用来保存未来的数据
# mode="w"表示写write,但会把上一次爬取的数据覆盖掉 ; mode="r"表示读read
# mode="a"可以把之前爬取的数据保留
trs = table.find_all("tr")
# table.find找的是一个标签,一般只返回第一个
# table.find_all找一堆标签
# 把tr所代表的每一行数据拿到trs
for tr in trs:
# 返回了一堆tr,通过for tr in trs循环,拿到每一个tr
lst = tr.find_all("td")
# 找到每一个td,装到列表里
if len(lst) != 0:
# 如果数据长度不为0(正好去掉了第一行的标题行的数据,因为第一行的数据只有th,没有td)
for td in lst: # 拿到每一个td
f.write(td.text.strip()) # 拿到td标签中的文本信息
# strip()默认去掉左右两侧的空白(空格、换行符、制表符)
f.write(,) # 每一个信息用逗号隔开
f.write("\n") # 换行最终就能呈现一个规则的文本信息
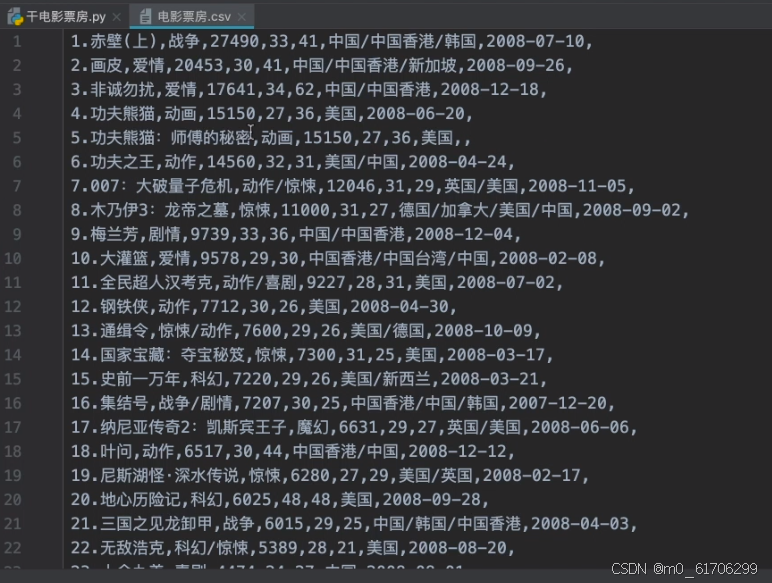
# 把年份处换成变量,那就不光能爬取2008年的数据,其他年份的也可以爬取了
text = requests.get("http://www.cbooo.cn/year?year=%s"%year).textdef down(year): #由外界穿过来的year,爬取对应年份的网页信息
text = requests.get("http://www.cbooo.cn/year?year=%s"%year).text
main_page = BeautifulSoup(text,"html.parser")
table = main_page.find("table",attrs="id":"tbContent")
f = open("电影票房.csv",mode="a")
trs = table.find_all("tr")
for tr in trs:
lst = tr.find_all("td")
if len(lst) != 0:
for td in lst: # 拿到每一个td
f.write(td.text.strip()) # 拿到td标签中的文本信息
# strip()默认去掉左右两侧的空白(空格、换行符、制表符)
f.write(,) # 每一个信息用逗号隔开
f.write("\n") # 换行
down(2019) #调用down的时候,填2019就爬2019年的for year in range(2008,2020): # 爬取2008年到2019年的信息
down(year) #把2008年到2019年的year都传过去

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)