Homunculus-12B模型论文速读:一种经济高效且实用的视觉语言动作机器人模型
一种经济高效且实用的视觉语言动作机器人模型
《SmolVLA: A vision-language-action model for affordable and efficient robotics》论文解读
一、研究背景
近年来,多模态基础模型(如视觉-语言模型VLM)在数字领域取得了显著进展,但在机器人领域的应用仍面临诸多挑战。现有视觉-语言-动作(VLA)模型通常规模庞大(参数量达数十亿),导致训练成本高昂且实际部署困难。此外,这些模型多依赖学术和工业数据集,忽视了来自经济型机器人平台的社区数据。为此,论文提出SmolVLA——一种小型、高效、社区驱动的VLA模型,旨在降低训练和推理成本,同时保持竞争力的性能。
二、研究方法
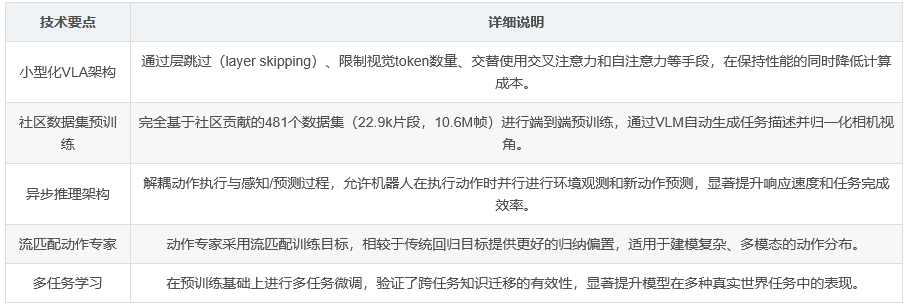
SmolVLA架构
SmolVLA包含两个主要组件:预训练的视觉-语言模型(VLM)和动作专家(Action Expert)。VLM负责感知环境,基于多图像输入和语言指令生成特征;动作专家则基于这些特征预测动作序列。具体设计如下:
-
VLM选择与优化:采用SmolVLM-2作为骨干网络,支持多图像和视频输入。为提升效率,通过跳过部分层(layer skipping)减少计算量,并限制每帧视觉token数量为64。
-
动作专家设计:基于Transformer架构,采用流匹配(flow matching)训练目标。与传统VLA架构不同,SmolVLA在动作专家中交替使用交叉注意力(CA)和自注意力(SA)层,以平衡性能和计算效率。
预训练数据与社区数据集
SmolVLA完全基于社区贡献的数据集进行端到端预训练,共包含481个数据集、22.9k个片段和10.6M帧。为解决社区数据集的标注噪声和相机视角不一致性,研究者采用以下策略:
-
任务标注标准化:利用现成的VLM(Qwen2.5-VL-3B-Instruct)自动生成简洁的任务描述。
-
相机视角归一化:手动将不同数据集的相机视角映射到标准化视角类型(如顶视图、腕部视角等)。
异步推理架构
为提升响应速度,论文提出异步推理架构,解耦动作执行与感知/动作预测。具体来说:
-
工作流程:机器人客户端(RobotClient)捕获环境状态并发送至策略服务器(PolicyServer),服务器返回动作序列后,客户端在执行动作的同时可触发新的环境观测请求。
-
优势:避免执行延迟,提升控制频率,且允许将计算资源分配至远程服务器,适用于资源受限场景。
三、实验设计
评估环境与指标
实验涵盖模拟环境和真实世界场景,评估指标为成功率(Success Rate, SR)。模拟环境包括LIBERO和Meta-World两大基准测试,真实世界任务则涉及拾取-放置、堆叠和排序等操作。
实验平台
实验使用多种机器人平台,包括低成本的SO-100/SO-101机械臂、Panda机器人(用于LIBERO模拟器)和Swayer机器人(用于Meta-World模拟器)。
实施细节
预训练阶段采用200k步训练,全局批次大小为256;微调阶段模拟任务采用100k步训练,真实世界任务采用200k步训练。推理时固定流匹配步数为10步,仅训练动作专家模块,冻结VLM参数。
基线模型对比
论文对比了SmolVLA与两种强基线模型:π0(33亿参数,基于VLM和流匹配预测动作序列)和ACT(8000万参数,基于条件变分自编码器CVAE生成动作序列)。
四、关键结论
模拟环境评估结果
在LIBERO和Meta-World两大模拟基准测试中,SmolVLA超越了Octo、OpenVLA等VLA方法以及扩散策略基线。与π0对比,尽管SmolVLA未在机器人数据上预训练,但其性能与π0的机器人预训练版本相当,且训练速度提升40%,内存消耗减少6倍。
真实世界评估结果
在SO-100真实世界任务中,SmolVLA在三项任务上的平均成功率达78.3%,显著优于ACT(48.3%)和π0(61.7%)。在SO-101平台上,SmolVLA在分布内和分布外场景中的成功率分别为90%和50%,优于ACT的70%和40%。
预训练与多任务学习效果
预训练可显著提升模型性能(从51.7%提升至78.3%),多任务微调进一步增强性能,凸显了跨任务知识迁移的重要性。
异步推理优势
异步推理模式在保持成功率相当的情况下,将任务完成时间从13.75秒缩短至9.7秒(提速约30%),并在固定时间内完成更多任务(19次vs 9次),展现出更快的反应速度和环境适应性。
消融实验
消融实验验证了以下关键设计选择的有效性:
-
交替使用交叉注意力和自注意力优于单独使用任一方法。
-
动作token间的因果注意力优于双向注意力。
-
使用VLM前半部分层特征在性能和计算效率间取得良好平衡。
-
流匹配训练目标优于回归目标。
-
将状态信息输入VLM而非动作专家可显著提升性能。
五、局限性与未来方向
尽管SmolVLA取得显著进展,但仍存在以下局限性:
-
数据集多样性:当前预训练数据集来源于单一机器人类型(SO-100),限制了模型对新机器人平台的泛化能力。
-
数据集规模:数据量(23k轨迹)远小于典型VLA训练规模(如OpenVLA的1M轨迹),制约了模型性能提升。
-
模型尺寸与硬件效率:尽管SmolVLA参数量仅0.5亿,但进一步提升规模而不牺牲速度或可访问性是未来研究方向。
-
VLM骨干网络选择:当前采用的VLM主要预训练于文档阅读和OCR任务,其对机器人交互场景的适配性尚待验证。
-
多模态与机器人数据联合训练:探索机器人特定数据与广泛多模态数据的联合训练有望提升模型泛化和指令遵循能力。
-
任务复杂性与时序跨度:SmolVLA主要适用于简单、短时任务,扩展至长时序复杂任务仍需引入层次化策略或多层次规划机制。
-
学习范式:当前基于模仿学习,未来可探索强化学习技术以提升策略适应性和处理复杂任务的能力。
六、总结
SmolVLA作为一种小型、高效的VLA模型,成功实现了在消费级硬件上的快速推理,并在低成本机器人控制中达到与大型VLA模型相当的性能。其异步推理架构提升了真实世界操作任务的适应性和响应速度,且模型设计、预训练数据集、机器人硬件和详细指令均已开源,为机器人研究社区提供了宝贵资源。
核心技术汇总

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 11
11 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)