深度学习之用CelebA_Spoof数据集搭建一个活体检测-数据处理
是一个大规模人脸防欺骗数据集,该数据集包含来自10,177个受试者的625,537张图像,包括人脸、光照、环境和欺骗类型等43个丰富的属性。有40个属性属于Live图像,包括皮肤、鼻子、眼睛、眉毛、嘴唇、头发、帽子、眼镜等所有面部成分和配件。3个属性属于恶搞图像,包括恶搞类型、环境和光照条件。如果要做人脸的活体检测,这个数据库是一个不错的选择。下载地址有两个:百度云下载Google云盘。
简介
CelebA-Spoof是一个大规模人脸防欺骗数据集,该数据集包含来自10,177个受试者的625,537张图像,包括人脸、光照、环境和欺骗类型等43个丰富的属性。有40个属性属于Live图像,包括皮肤、鼻子、眼睛、眉毛、嘴唇、头发、帽子、眼镜等所有面部成分和配件。3个属性属于恶搞图像,包括恶搞类型、环境和光照条件。如果要做人脸的活体检测,这个数据库是一个不错的选择。
下载地址有两个:
百度云:百度云下载(password: 61fd)
Google Drive:Google云盘
一、数据集准备与解压
CelebA_Spoof数据集有70多G,建议没有开会员的同学可以从Google Drive下载,下载好的文件是分批压缩的。共有74个压缩文件。
1. 数据集解压
数据集以压缩包形式提供, 7-Zip 分批解压所有编号为 001 到 074 的 zip 文件(见上图),需要提前安装 7-Zip,安装后用下面的步骤进行解压:
Windows:按下 Win + R,输入 cmd,然后按回车。
Linux/Mac:打开终端。
使用 cd 命令导航到存放 zip 文件的文件夹。
cd path\to\your\zipfiles
对于 Windows(命令提示符):
运行以下命令:
for %i in (*.zip.*) do "C:\Program Files\7-Zip\7z.exe" x "%i" -o"output_folder" -y
如果 7-Zip 安装在其他路径,请将 C:\Program Files\7-Zip\7z.exe 替换为实际路径。
将 output_folder 替换为你希望解压文件存放的目标文件夹名称。
参数 -y 表示自动回答“是”以跳过提示。
对于 Linux/Mac(终端):
for file in *.zip.*; do 7z x "$file" -ooutput_folder -y; done
将 output_folder 替换为目标文件夹名称。
解压后目录结构如下:
CelebA_Spoof/
├── Data/
│ ├── train/
│ │ ├── ID/
│ │ │ ├── live/ # 真实人脸图像
│ │ │ │ ├──xxx.png #原图
│ │ │ │ └──xxx_BB.txt #原图对应的人脸坐标与分数
│ │ │ └── spoof/ # 欺骗攻击图像
│ │ │ │ ├──xxx.png #原图
│ │ │ │ └──xxx_BB.txt #原图对应的人脸坐标与分数
├── metas/
│ ├── intra_test/ #内部数据集基准,包含数据描述和 JSON 标签文件。
│ └── protocol1/ #包括训练/测试划分和 JSON 标签文件。
│ └── protocol2/ #包括不同设备质量(高、中、低)下的训练/测试划分和 JSON 标签文件。
├── README
二、数据处理与标注解析
值得注意的是,CelebA-Spoof 数据集不仅提供了活体/伪造(Live/Spoof)的标注,还进一步对伪造类型、光照条件和环境进行了详细的标注。这些丰富的注解有助于从多个角度全面研究面部反欺骗任务。提供的json标签文件中,包含了40中人脸属性(继承自CelebA数据集,涵盖了如性别、年龄、表情等多种属性)和3中与活体/反欺骗相关的属性:
伪造类型(Spoof Type):定义了不同类型的伪造攻击。
光照条件(Illumination Condition):描述了图像拍摄时的光照情况。
环境(Environment):指出了图像拍摄的环境。
比如下面这两张图片以及对应的标签:
"Data/test/5284/live/494568.png": [
[0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0], # [0:39]: 人脸属性标签
0, # [40]: 伪造类型标签(Spoof Type) -> Live(活体)
0, # [41]: 光照条件标签(Illumination Condition) -> Live(活体)
0, # [42]: 环境标签(Environment) -> Live(活体)
0 # [43]: 活体/伪造标签 -> Live(活体)
]
"Data/test/6336/spoof/494419.png": [
[0, 0, 0, ..., 0], # [0:39]: 40种人脸属性标签,均为0,表示未检测到任何属性。
3, # [40]: 伪造类型标签(Spoof Type) -> A4(打印在A4纸上的图片)。
1, # [41]: 光照条件标签(Illumination Condition) -> Normal(正常光照)。
1, # [42]: 环境标签(Environment) -> Indoor(室内)。
1 # [43]: 活体/伪造标签 -> Spoof(伪造)。
]
具体的更多标签表示,见下表: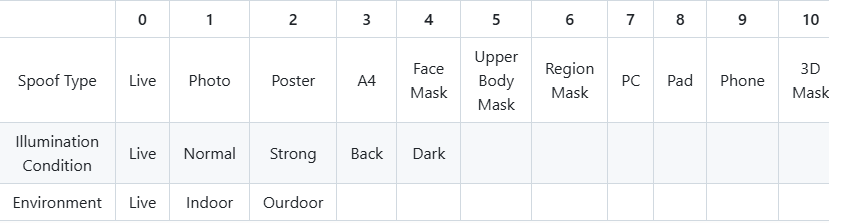
因此,如果需要可以用于训练一个多类别分类器来区分不同类型的伪造攻击,帮助研究人员了解不同类型的攻击对模型的影响,并针对性地改进算法,可以用Spoof Type的标签,如果对于只需要知道是否存在伪造行为的应用场景来说,主要用于基本的活体检测任务,即判断一个人脸图像是真实的还是伪造的,则可以使用[43]: 活体/伪造标签就足够了。
1. 标注文件解析脚本
创建Python脚本处理标注信息,可以处理多分类和二分类下的样本处理:
import os
import json
from tkinter import X
from PIL import Image
from pathlib import Path
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
def load_json(json_path):
"""
加载 JSON 文件并返回数据。
:param json_path: JSON 文件路径。
:return: 包含图像路径和标签的字典。
"""
with open(json_path, 'r') as file:
data = json.load(file)
return data
def load_bbox(bbox_file_path):
"""
加载边界框文件并返回边界框信息。
:param bbox_file_path: 边界框文件路径。
:return: 包含边界框信息的列表 [x, y, w, h, score]。
"""
if not os.path.exists(bbox_file_path):
raise FileNotFoundError(f"Bounding box file not found: {bbox_file_path}")
with open(bbox_file_path, 'r') as file:
bbox_info = list(map(float, file.read().strip().split()))
return bbox_info
def crop_and_save_faces(image_path, bbox_list, output_dir, label_name, image_name):
"""
根据边界框裁剪人脸并保存到指定目录。
:param image_path: 原图路径。
:param bbox_list: 边界框列表,每个元素为 [x, y, w, h, score]。
:param output_dir: 输出目录。
:param label_name: 标签名(如 "Live" 或 "Spoof_Type_3")。
:param image_name: 图像名称(如 "494568.png")。
"""
# 确保输出目录存在
label_dir = os.path.join(output_dir, label_name)
os.makedirs(label_dir, exist_ok=True)
try:
# 打开原图并获取实际尺寸
img = Image.open(image_path)
real_w, real_h = img.size # 获取图像的实际宽高
for face_id, bbox in enumerate(bbox_list):
# 缩放边界框值到实际图像尺寸
x1 = int(bbox[0] * (real_w / 224))
y1 = int(bbox[1] * (real_h / 224))
w1 = int(bbox[2] * (real_w / 224))
h1 = int(bbox[3] * (real_h / 224))
# 裁剪人脸
print(f"Cropping face {face_id + 1} from image {image_path} with bbox: {x1, y1, w1, h1,x1+w1, y1+h1, real_w, real_h}")
cropped_img = img.crop((x1, y1, x1 + w1, y1 + h1))
# 构造保存路径
if len(bbox_list) > 1: # 如果有多张人脸,添加 face_id 后缀
output_path = os.path.join(label_dir, f"{image_name}_face_{face_id}.png")
else:
output_path = os.path.join(label_dir, f"{image_name}")
# 保存裁剪后的人脸
cropped_img.save(output_path)
except Exception as e:
print(f"Error processing image {image_path}: {e}")
def process_images(json_path, base_image_dir, output_dir, task_type="multiclass"):
"""
处理图像并裁剪人脸。
:param json_path: JSON 文件路径。
:param base_image_dir: 图像的基础目录路径。
:param output_dir: 输出目录。
:param task_type: 任务类型 ("multiclass" 或 "binary")。
"""
# 定义 Spoof_Type 类别映射
spoof_type_mapping = {
0: "Live",
1: "Photo",
2: "Poster",
3: "A4",
4: "Face Mask",
5: "Upper Body Mask",
6: "Region Mask",
7: "PC",
8: "Pad",
9: "Phone",
10: "3D Mask"
}
# 加载 JSON 数据
data = load_json(json_path)
for relative_image_path, labels in data.items():
# 拼接完整图片路径
full_image_path = os.path.join(base_image_dir, relative_image_path)
if not os.path.exists(full_image_path):
print(f"Image file not found: {full_image_path}")
continue
# 获取伪造类型标签和活体/伪造标签
spoof_type = labels[40]
live_spoof = labels[43]
# 根据任务类型确定标签名
if task_type == "multiclass":
label_name = spoof_type_mapping.get(spoof_type, "Unknown_Spoof_Type")
elif task_type == "binaryclass":
label_name = "Live" if live_spoof == 0 else "Spoof"
else:
raise ValueError("Invalid task_type. Choose from 'multiclass' or 'binary'.")
# 构造边界框文件路径
bbox_file_path = Path(full_image_path).with_name(Path(full_image_path).stem + "_BB.txt")
try:
# 加载边界框信息
bbox_list = load_bbox(bbox_file_path)
# 裁剪并保存人脸
crop_and_save_faces(full_image_path, [bbox_list], output_dir, label_name, Path(relative_image_path).name)
except FileNotFoundError as e:
print(e)
if __name__ == "__main__":
# 参数设置
json_path = "path/to/your/train_label.json" # JSON 文件路径
base_image_dir = "/absolute/path/to/Data/test" # 图像的基础目录路径
output_dir = "path/to/output" # 输出目录
# 执行处理
process_images(json_path, base_image_dir, output_dir, task_type="binaryclass")
多分类下得到的结果为:
二分类下得到的结果为:
三、后续
至此,便可以将json文件中对应的图片和标注信息处理后的结果图保存到相应的位置下,在后续中继续进行模型训练等操作。当然,对于二分类,也可以直接访问原图目录下的图片,根据文件夹命名进行分类操作,这种情况不在这分析。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 21
21 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)