如何计算给定一个unigram语言模型_n-gram语言模型原理到实践
最近开始复习一些nlp基础知识,今天来回顾一下自然语言处理的重要技术语言模型(language model)。
1 什么是语言模型
语言模型就是衡量一句话概率的模型,可以用来判断这句话为人话的概率。我们可以把一段自然语言文本看作一段离散的时间序列。假设一段长度为T的文本中的词依次为
语言模型可用于提升语音识别和机器翻译的性能。例如,在语音识别中,给定一段“厨房里食油用完了”的语音,有可能会输出“厨房里食油用完了”和“厨房里石油用完了”这两个读音完全一样的文本序列。如果语言模型判断出前者的概率大于后者的概率,我们就可以根据相同读音的语音输出“厨房里食油用完了”的文本序列。在机器翻译中,如果对英文“you go first”逐词翻译成中文的话,可能得到“你走先”“你先走”等排列方式的文本序列。如果语言模型判断出“你先走”的概率大于其他排列方式的文本序列的概率,我们就可以把“you go first”翻译成"你先走"。(摘自《动手学深度学习》)
2 语言模型的计算
既然语言模型很有用,那么我们该如何计算呢?假设一段含有4个词的文本序列w1,w2,w3,w4,则该序列的概率为
一般的,对于序列
其中,条件概率
当序列非常长的时候,计算和存储多个词共同出现的概率的复杂度会呈指数级别增长。而且数据稀疏十分严重,没有足够大的预料能够满足多个词的共现,即不满足大数定律而导致概率失真。并且由Zipf定律(Zipf's Law)知道在自然语言中大部分词都是低频词,很难通过增加数据集来避免数据稀疏问题。因此多个词共同出现的次数在语料库中可能为0,导致序列概率直接为0。
3 从联合概率链到n-gram语言模型
上面我们已经讨论了语言模型的联合概率计算是很困难的,如何简化语言模型的计算呢?这里便引入了马尔可夫假设:一个词的出现只与前面n个词相关,即n阶马尔可夫链。
如果n=1,那么有
当n=1,n=2,n=3时,我们将其分别称作一元语法(unigram)、二元语法(bigram)和三元语法(trigram)。
对于unigram来说,满足了独立性假设,马尔可夫假设可以看做在独立性假设的基础上加上了条件依赖。
例如,长度为4的序列
严格来说,对于2-gram和3-gram来说,这样计算的概率有偏差,对于2-gram,w1也应该计算条件概率,这时需要给句子加上起始和结束位标志。下面举个例子计算2-gram。
<s>I am Sam</s>
<s>Sam I am</s>
<s>I do not like green eggs and ham</s>
...
因此
但是在实际情况下,如果要严格计算语言模型,需要对语料进行分句,然后在句首和句尾添加起始符和结束符,这样比较麻烦。所以在很多情况下我们会使用上面说的计算方法来近似,可能也是因为这个原因我们很少看见加起始符和结束符的计算操作,只要句子计算的标准保持一致,还是能够准确判断概率大小的。(我的观点,不一定准确,如果有不对的地方欢迎指正~)
4 平滑技术
为了解决零概率问题呢,我们需要给“未出现的n-gram条件概率分布一个非零估计值,相应得需要降低已出现n-gram条件概率分布,且经数据平滑后一定保证概率和为1”。这就是平滑技术的基本思想。
4.1 拉普拉斯平滑
这是最古老的一种平滑方法,又称加一平滑法,其保证每个n-gram在训练语料中至少出现1次。以计算概率 P(“优惠”|“发票”,“点数”)为例,公式如下:
在所有不重复的三元组的个数远大于(“发票”,“点数”)出现的次数时,即训练语料库中绝大部分n-gram都是未出现的情况(一般都是如此),拉普拉斯平滑有“喧宾夺主”的现象,效果不佳。
4.2 古德图灵(Good Turing)平滑
通过对语料库的统计,我们能够知道出现r次(r>0)的n元组的个数为
- 出现0次的n元组也不能认为其是0次,应该给它一个比较小的估计值,比如为
次。
- 为了保证总共的(出现和未出现的)n元组的次数不变,其他所有已出现的n元组的次数r应该打一个折扣,比如为
次。
- 然后再用新的
去计算各个条件概率。
所以问题的关键是计算
所以干脆令:
一般来说,出现一次的词的数量比出现两次的多,出现两次的比三次的多。这种规律称为Zipf定律(Zipf’s Law)。下图是一个小语料上出现r次的词的数量
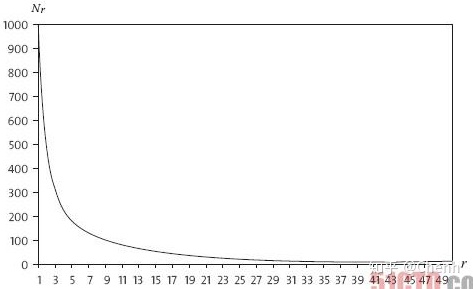
可以看出r越大,词的数量
当然,在实际的自然语言处理中,一般会设置一个阈值T(一般取8~10),仅对出现次数小于T的词做上述平滑。并且,因为实际语料的统计情况使得
4.3 组合估计平滑
不管是拉普拉斯平滑,还是古德图灵平滑技术,对于未出现的n元组都一视同仁,而这难免存在不合理。 因为哪怕是未发生的事件,相互之间真实的概率也会存在差别。
另一方面,一个n元组可能未出现,但是其(n-1)元组或者(n-2)元组是出现过的,这些信息如果不利用就直接浪费掉了。在没有足够的数据对高元n-gram模型进行概率估计时,低元n-gram模型通常可以提供有用的信息。因此可以利用利用低元n-gram模型的信息对高元n-gram模型进行估计:
- 如果低元n-gram模型的概率本来就很低,那么就给高元n-gram模型一个较低的估计值;
- 如果低元n-gram模型有一个中等的概率,那么就给高元n-gram模型一个较高的估计值。
常用的组合估计算法有线性差值法和Katz回退法。具体公式比较复杂,这里就不列了。感兴趣的同学可参考 Christopher D. Manning 的《统计自然语言处理基础》
5 动手实现n-gram语言模型(bigram为例)
import pandas as pd
import re
import jieba
from collections import Counter
original_data = pd.read_csv('./data/sqlResult_1558435.csv', encoding='gb18030')
articles = original_data['content'].tolist()
# 去除标点符号、英文字符、数字
def clean(article):
clean_article = ''.join(re.findall('w+', str(article))) # 去除标点符号
pattern = re.compile('[A-Za-zd]+')
clean_article = pattern.sub('', str(clean_article)) # 去除英文字符和数字
return clean_article
# 将清洗后的文本保存到文件中
def save(articles):
with open('./data/article_9k.txt', 'w', encoding='utf-8') as f:
for a in articles:
f.write(a + 'n')
clean_articles = [clean(article) for article in articles]
save(clean_articles)
# 分词处理
def cut_text():
words_list = []
with open('./data/article_9k.txt', 'r') as f:
count = 0
for line in f:
words = list(jieba.cut(line.strip('n')))
words_list += words
return words_list
words_list = cut_text()
words_count = Counter(words_list)
TOKENS_2GRAM = [''.join(words_list[i:i+2]) for i in range(len(words_list)-1)]
words_count2 = Counter(TOKENS_2GRAM)
words_list_len = len(words_list)
unique_words_len = len(words_count)
unique_bigram_len = len(words_count2)
# 计算词独立出现的概率,采用拉普拉斯平滑
def prob_1(word):
return (words_count[word] + 1) / (words_list_len + unique_words_len)
# 计算条件概率,采用拉普拉斯平滑
def prob_2(word1, word2):
return (words_count2[word1+word2] + 1) / (words_count[word1] + unique_bigram_len)
# 构建2-gram语言模型
def bigram_model(sentence):
words = list(jieba.cut(sentence))
probility = prob_1(words[0])
for index in range(len(words)-1):
probility *= prob_2(words[index], words[index+1])
return probility
sent1 = "我爱你"
sent2 = "我你爱"
sent3 = "今天天气真好"
sent4 = "今天真天气好"
sent5 = "你先走"
sent6 = "你走先"
print(bigram_model(sent1))
print(bigram_model(sent2))
print(bigram_model(sent3))
print(bigram_model(sent4))
print(bigram_model(sent5))
print(bigram_model(sent6))输出:
5.9607783295715594e-06
1.2585314454141385e-14
6.751764045254859e-19
6.959695538300923e-24
1.2520998402585423e-15
3.909475699071306e-16

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)