机器学习入门-鸢尾花数据集(上)
鸢尾花数据集是常见的入门任务,文章将详细介绍整个任务流程,简化繁琐的流程,包含内容见文章目录,供大家快速入门机器学习。鸢尾花数据集(Iris Dataset)是一个经典的机器学习数据集,最初由美国统计学家 Ronald A. Fisher 在 1936 年提出,作为他的论文《The use of multiple measurements in taxonomic problems》中使用的案例数
鸢尾花数据集是常见的入门任务,文章将详细介绍整个任务流程,简化繁琐的流程,包含内容见文章目录,供大家快速入门机器学习。
一. 数据理解
鸢尾花数据集(Iris Dataset)是一个经典的机器学习数据集,最初由美国统计学家 Ronald A. Fisher 在 1936 年提出,作为他的论文《The use of multiple measurements in taxonomic problems》中使用的案例数据。该数据集旨在研究鸢尾花的形态学特征之间的关系,并通过这些特征对鸢尾花的不同类别进行分类。
数据来源: 鸢尾花数据集最早是在Fisher的研究中手动测量而得,随后成为统计学和机器学习领域的经典数据集。如今,该数据集广泛应用于机器学习入门教学和模型性能验证中。现代版本的数据集可通过多个途径获取,例如:
- 在Scikit-learn库中提供的内置数据集。
- 在UCI Machine Learning Repository(https://archive.ics.uci.edu/ml/datasets/Iris)上公开共享。
- 本文使用kaggle的数据集(Iris Species | Kaggle)方便大家自取
数据集描述: 鸢尾花数据集由150个样本组成,每个样本描述了一种鸢尾花的特征,包括四个数值型特征和一个目标类别标签。特征数据为连续变量,目标标签为离散分类变量。

1.1 特征描述:
鸢尾花的每个样本由以下四个特征描述:
- 花萼长度(Sepal Length, cm):描述花萼的长度,单位为厘米。
- 花萼宽度(Sepal Width, cm):描述花萼的宽度,单位为厘米。
- 花瓣长度(Petal Length, cm):描述花瓣的长度,单位为厘米。
- 花瓣宽度(Petal Width, cm):描述花瓣的宽度,单位为厘米。
特征数据均为连续变量,单位均为厘米。这些特征是通过测量实际的鸢尾花物理尺寸获取的,并且已被标准化为浮点数值,便于算法处理。
1.2类别标签:
数据集中的鸢尾花分为三种类别,分别对应三种不同的鸢尾花品种,每类样本数目均为50,数据分布均衡。这三类鸢尾花分别为:
- Setosa(山鸢尾):特征上明显可区分,与其他两类鸢尾花有显著差异。
- Versicolor(变色鸢尾):特征上部分与Virginica重叠。
- Virginica(维吉尼亚鸢尾):与Versicolor具有一定特征相似性,因此分类具有挑战性。
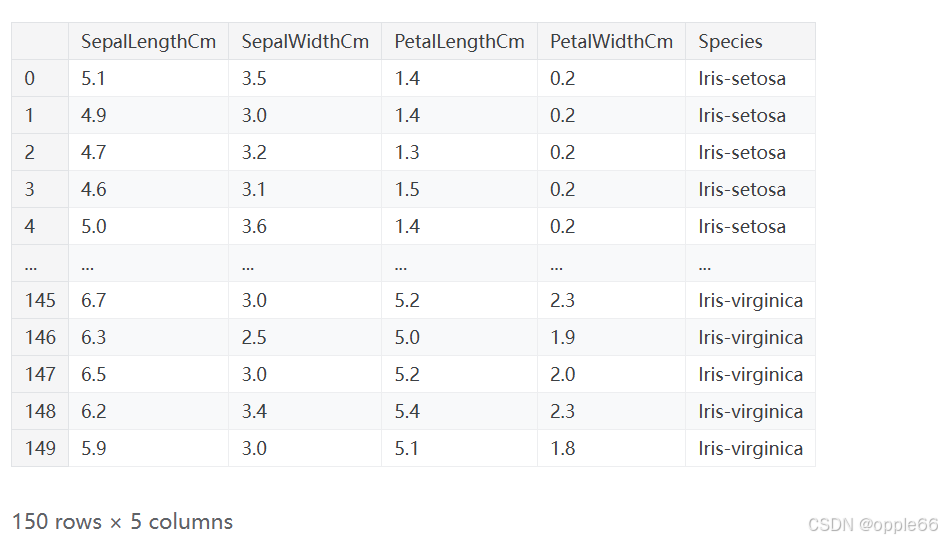
二. 数据可视化
df.describe().T #T transpose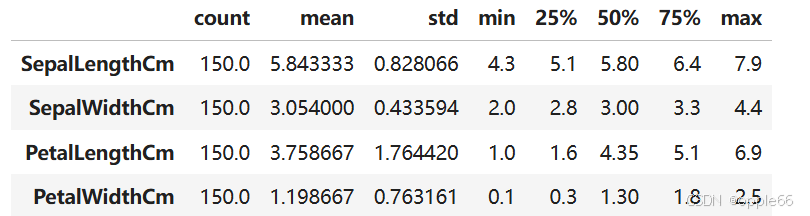
Correlation Matrix 相关性矩阵
pl.figure(figsize=(10,8))
sns.heatmap(df.select_dtypes(include=['number']).corr(), annot=True, cmap="Blues")
plt.show()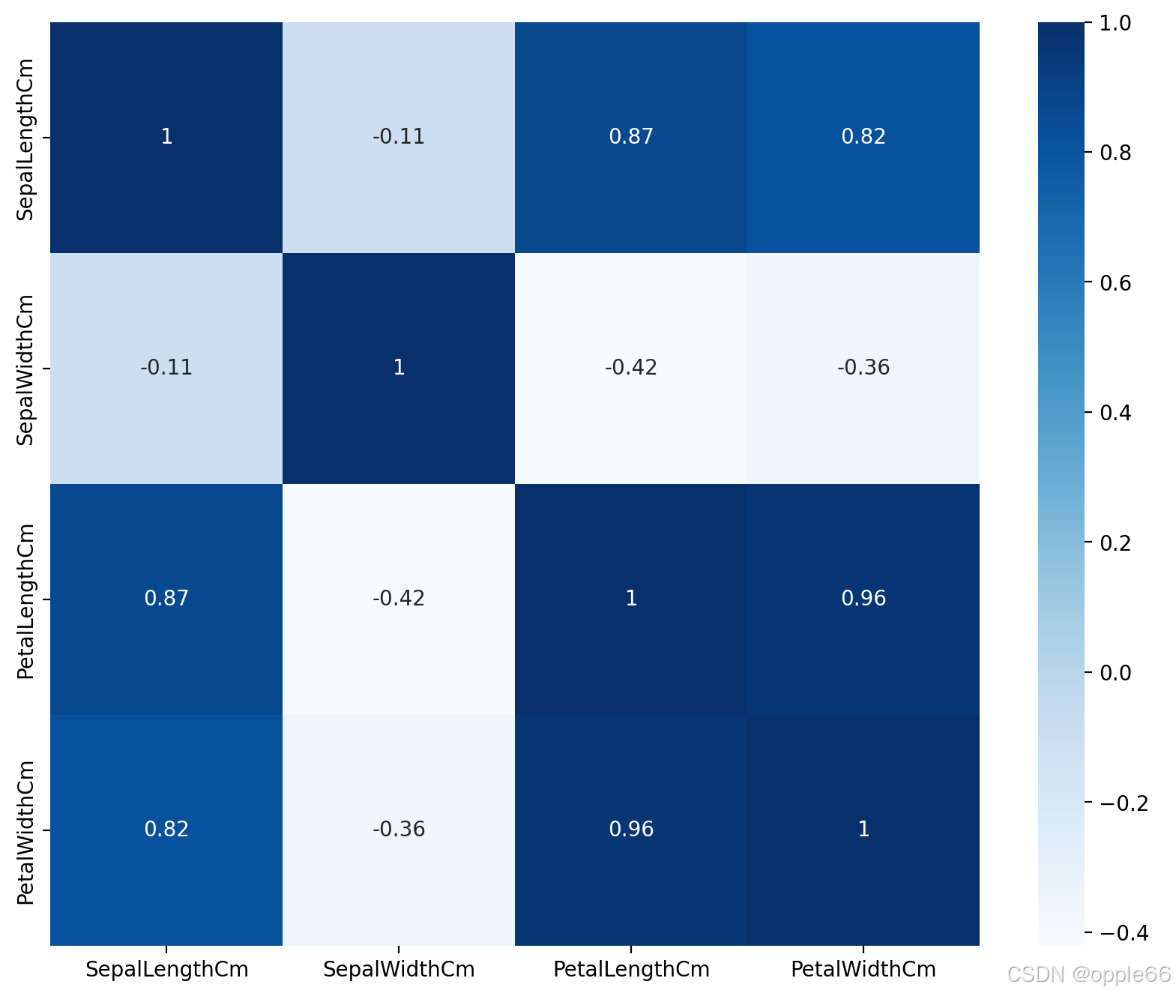
散点图 + KDE 密度图
sns.pairplot(df, hue='Species', height=3).map_lower(sns.kdeplot, levels=2)
plt.show() 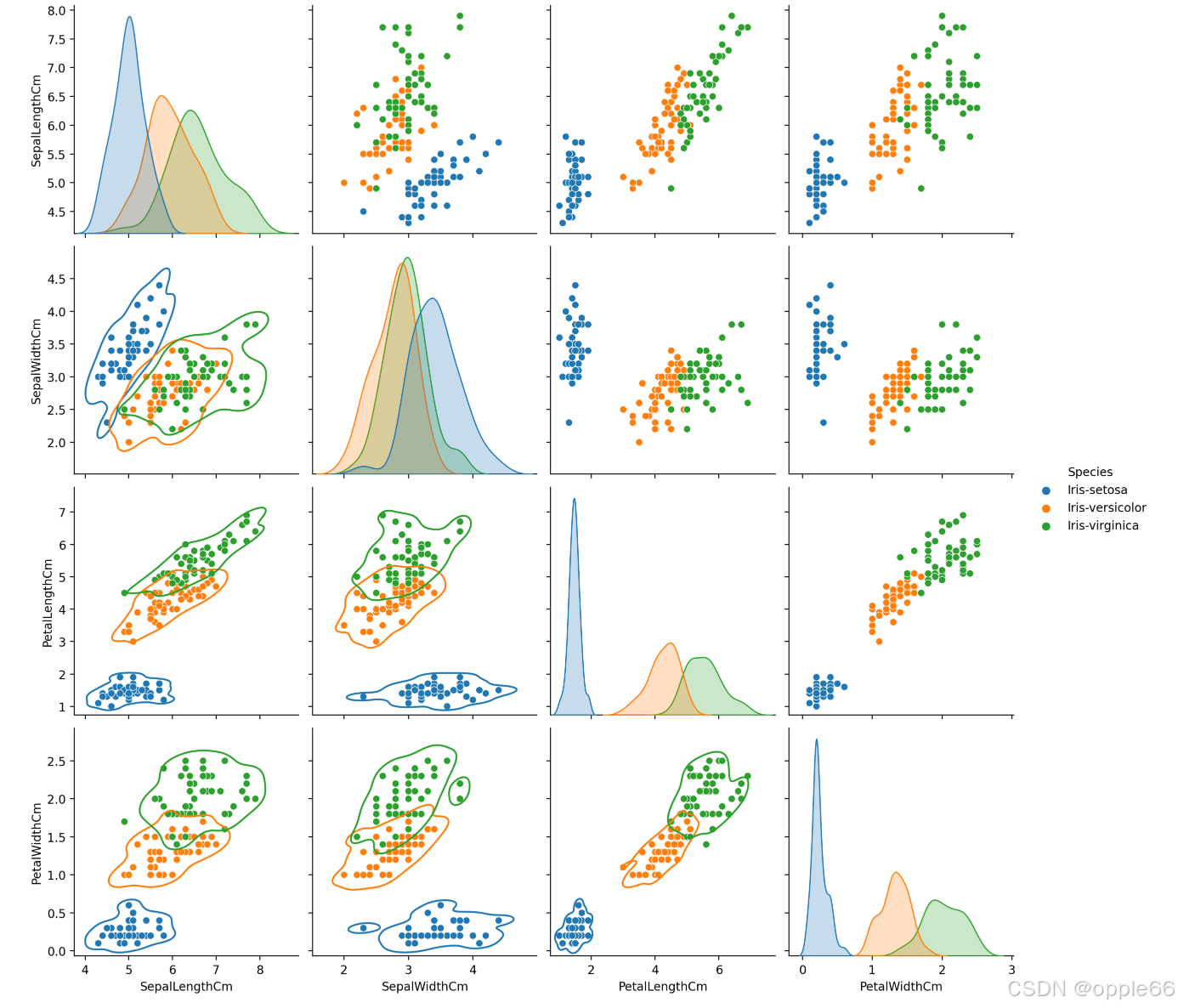 3D 散点图
3D 散点图
from plotly.express import scatter_3d
scatter_3d(x='PetalLengthCm',
y='PetalWidthCm',
z='SepalLengthCm',
color='Species',
color_discrete_sequence=['yellow', 'red', 'purple'],
data_frame=df).show() 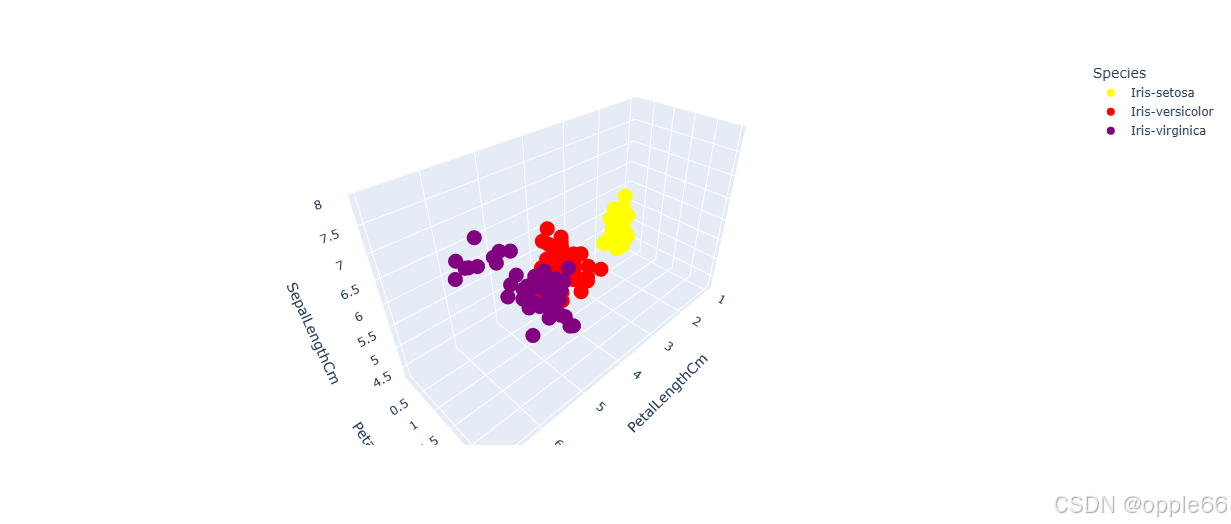 小提琴图 带状图
小提琴图 带状图
import matplotlib.pyplot as plt
import seaborn as sns
fig, axes = plt.subplots(2, 4, figsize=(20, 10))
# Violin Plots
for ax, col in zip(axes.flatten(), df.columns[:-1]):
sns.violinplot(x='Species', y=col, data=df, ax=ax, palette="coolwarm")
# Strip Plots
for ax, col in zip(axes.flatten()[4:], df.columns[:-1]):
sns.stripplot(x='Species', y=col, data=df, ax=ax, palette="Dark2", jitter=True, alpha=0.7)
plt.tight_layout(pad=1, w_pad=1.5, h_pad=2)
plt.show()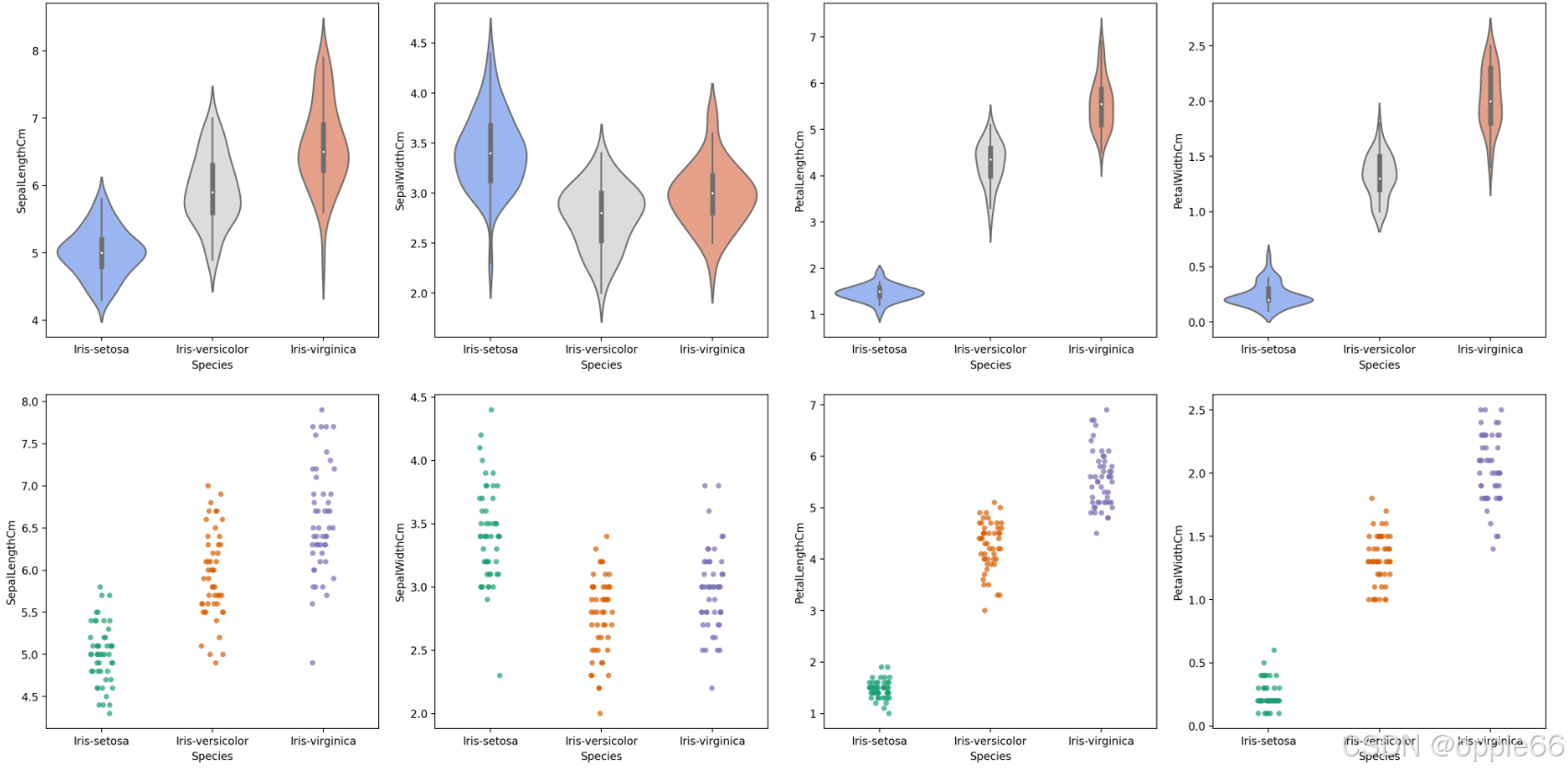 感谢收看,作为上半部分主要做了数据集解读数据可视化,下半部分会给出机器学习模型的代码,记得点赞支持一下!谢谢!
感谢收看,作为上半部分主要做了数据集解读数据可视化,下半部分会给出机器学习模型的代码,记得点赞支持一下!谢谢!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)