通俗解释人工智能领域的Scaling Laws 是什么意思?
人工智能领域的Scaling Law是什么?尺度定律(Scaling Law)是被业界认为是大模型预训练第一性原理。在机器学习领域,特别是对于大型语言模型而言,与其、以及用于训练的之间存在的一种可预测的关系。这种关系通常表现为随着这些变量的增长,模型会按照一定的幂律函数进行提高性能,即函数loss减小。
·

什么是Scaling law?
人工智能领域的Scaling Law是什么?尺度定律(Scaling Law)是被业界认为是大模型预训练第一性原理。在机器学习领域,特别是对于大型语言模型而言,模型的性能与其训练数据集大小,模型规模(参数数量)、以及用于训练的计算资源之间存在的一种可预测的关系。
这种关系通常表现为随着这些变量的增长,模型会按照一定的幂律函数进行提高性能,即函数loss减小。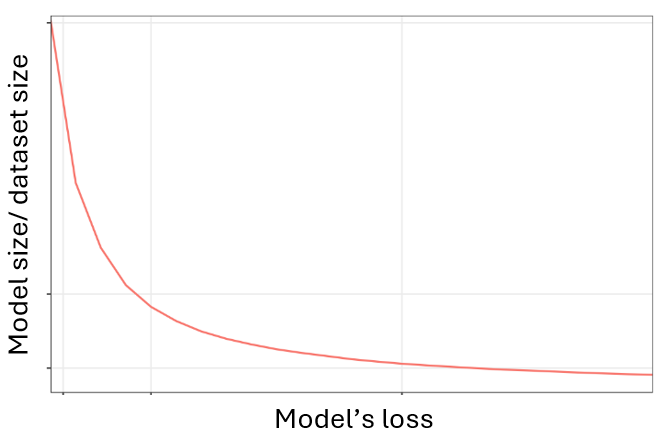
模型性能的核心限制因素?
- 理论极限:模型性能受限于三大要素的平衡——计算量(Compute)、模型参数量(Parameters)、数据量(Data),即著名的"三要素平衡法则"
- 硬件限制:FLOP/s 每秒浮点运算次数是基础指标,此外还受内存带宽、显存容量、通信延迟等约束,如现代GPU的显存墙问题(Memory Wall)
在算力有限的情况下,为了优化模型,应该把资源放在提高模型参数量上还是提高输入数据量?答:数据充分性比单纯扩大模型更重要
- Chinchilla定律的突破性发现:在1.4万亿token训练时,最优模型规模应为700亿参数(而非传统认知的2800亿),揭示了数据充分性(Data Sufficiency)比单纯扩大模型更重要。
- 数据质量的效率提升:通过改进训练策略(课程学习、数据清洗、混合精度),当前SOTA模型在相同数据量下可获得2-5倍的性能提升
DeepSeek 的横空出世代表Scaling law失效了吗?
- Scaling Law依然有效,但优化和高效训练方法可以提升性能,而不是单纯扩大规模。
- 的确,计算资源、数据量和模型参数量是关键,但还有其他因素,比如模型架构、训练方法等。
- Scaling Law的核心内涵是性能与计算资源的幂律(Power law)关系,而非简单的参数堆砌。DeepSeek的成功验证了"高效缩放"(Efficient Scaling)新范式。
当前研究已进入"智能工程学"新阶段,性能提升不再依赖单一要素的扩展,而是需要算法-硬件-数据的协同创新。DeepSeek等模型的出现标志着Scaling Law进入第二发展阶段——从粗放式规模扩张转向精密系统优化。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)