raptor五个数排序流程图_数据结构与算法(一):排序(上)
做这个系列一是记录自己的学习过程,二是整合目前我所接触的比较好的资料,给出最直观,最通俗的算法解释总体概况十大排序算法:(比较排序):冒泡、选择、插入、归并、快速、希尔、堆排序基数排序、桶排序、计数排序冒泡排序(Bubble Sort)流程从头开始比较相邻的一对元素,如果前者大于后者,则交换。如果前者小于后者,则不变经过第一轮循环,最末尾的元素就是最大的元素经...
做这个系列一是记录自己的学习过程,二是整合目前我所接触的比较好的资料,给出最直观,最通俗的算法解释
总体概况
十大排序算法:(比较排序):冒泡、选择、插入、归并、快速、希尔、堆排序
基数排序、桶排序、计数排序

冒泡排序(Bubble Sort)
流程
-
从头开始比较相邻的一对元素,如果前者大于后者,则交换。如果前者小于后者,则不变
-
经过第一轮循环,最末尾的元素就是最大的元素
-
经过第二轮循环,倒数第二个元素为第二大的元素
-
……
-
经过N轮循环,则数组已从小到大排序
第一轮循环用代码表示
int[] array = {23, 53, 1, 32, 5, 77, 64};for (int begin = 1; begin < array.length; begin++) { if (array[begin] < array[begin-1]){ int tmp = array[begin]; array[begin] = array[begin-1]; array[begin-1] = tmp;//交换 }}for (int i = 0; i < array.length; i++) { System.out.print(array[i]+" ");}首先自己定义一个数组,并用for循环进行从头到尾的遍历,这边从1开始是因为我们需要拿到begin-1的值,begin-1是非负数,所以begin从1开始
array[begin-1]为前者 array[begin] 即为后者
按我们逻辑:前者大于后者时交换,所以接下来是一个典型的交换方法
原数组:[23 , 53 , 1 , 32 , 5 , 77 , 64]
在一轮循环结束看一下数组的变化:

此时最后一位已经固定了(最大值),下一次循环循环到倒数第二位,这么依次下来需要用到外层循环(直到固定到第一位):
for (int end = array.length - 1; end > 0; end--) { for (int begin = 1; begin <= end; begin++) { if (array[begin] < array[begin - 1]) { int tmp = array[begin]; array[begin] = array[begin - 1]; array[begin - 1] = tmp;//交换 } }}这就是著名的冒泡排序!
完全有序情况优化
如果拿到的数组就是有序的,那我们还需要经历这两重for循环吗?
目前的代码不管数组是有序还是无序,都要经历整个过程
所以我们对此进行优化
在第一次扫描元素后,我们就知道数组是否有序
在开始时定义一个元素sorted = true,如果进入了循环中的if语句,则把sorted置为false
定义sorted的值我们放在外层循环中。原因是可能整个数组在开始时候有序,这是最理想的情况,还有的情况就是在循环了几次之后发现变成有序的了,这时候后面的循环就没有必要进行下去了。所以需要在每一次扫描前把sorted置为true。
for (int end = array.length - 1; end > 0; end--) { boolean sorted = true; for (int begin = 1; begin <= end; begin++) { if (array[begin] < array[begin - 1]) { int tmp = array[begin]; array[begin] = array[begin - 1]; array[begin - 1] = tmp;//交换 sorted = false; } } if (sorted) break;}显而易见,通过这种方式我们处理了在进行几次循环后完全有序的情况,确实比之前的快了不少,但是还不够优化。原因是很少能出现这种完全有序的情况。
所以遇到中间局部有序的情况,需要进一步优化
局部有序情况优化
每次扫描数据的时候,记录最后一次交换的位置
定义一个索引指向最后一次交换的位置
for (int end = array.length - 1; end > 0; end--) { int sortedIndex = 1; for (int begin = 1; begin <= end; begin++) { if (array[begin] < array[begin - 1]) { int tmp = array[begin]; array[begin] = array[begin - 1]; array[begin - 1] = tmp;//交换 sortedIndex = begin; } } end = sortedIndex;}而这边索引值的初始值设为1,原因是当数组本来就完全有序的时候(不经过中间的if判断),我们不需要进行循环,所以在后面end置为sortedIndex的初始值。
最坏、平均情况(sortedIndex完全没有起作用)
时间复杂度:O(n^2)
最好情况(数据完全有序)
时间复杂度:O(n)
空间复杂度:O(1)
稳定性
如果两个数据排序内容相同,但是是不稳定的。

假如有一个学生数据类型(名字,分数)
当两个学生的成绩相等,排序的时候是不管名字的。所以谁在前谁在后还不一定,这就导致了不稳定性
冒泡排序无疑是稳定的
原因是:遇到两个相等的,是不会交换的
if (array[begin] < array[begin - 1])原地算法
-
不依赖额外的资源或者依赖少数的额外资源,仅依靠输出来覆盖输入
-
空间复杂度为O(1)的都可以认为是原地算法
冒泡排序属于原地算法
选择排序(Selection Sort)
流程
-
从序列中找出最大的那个元素,然后与最末尾的元素交换位置
执行完一轮后,最末尾的那个元素就是最大的元素
-
忽略上述找到的最大元素,重复执行步骤1
选择排序与冒泡排序比较像,两者都是两重循环
for (int end = array.length - 1; end > 0; end--) { int maxIndex = 0; for (int begin = 0; begin <= end; begin++) { if (array[maxIndex]<= array[begin]){ maxIndex = begin; } } int tmp = array[maxIndex]; array[maxIndex] = array[end]; array[end] = tmp;}选择排序的交换次数是远远小于冒泡排序的,平均性能优于冒泡排序
最好、最坏情况:
时间复杂度:O(n^2)
空间复杂度:O(1)
选择排序属于稳定排序
优化
利用堆的数据结构,在取最大时时间复杂度可以到达O(lLogn),所以加上一层循环后时间复杂度可以到达O(nLogn)
堆排序(Heap Sort)
-
堆排序可以认为是对选择排序的一种优化
流程
-
对序列进行原地建堆(heapify)
-
重复执行以下操作,知道堆的元素数量为1
-
交换堆顶元素与尾元素
-
堆的元素数量减1
-
对0位置进行1次siftDown操作
流程图
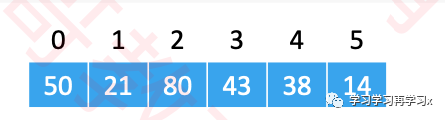
|
V
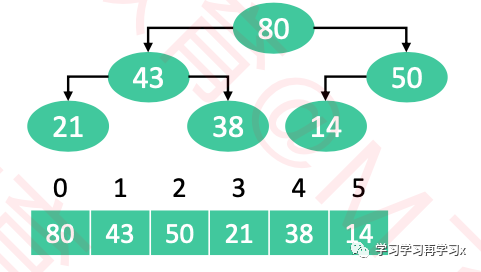
|
V
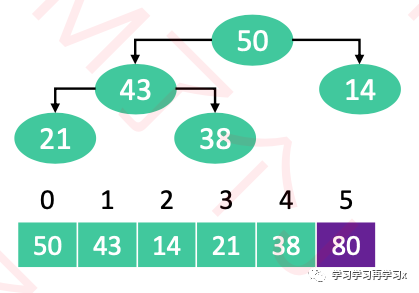
|
V
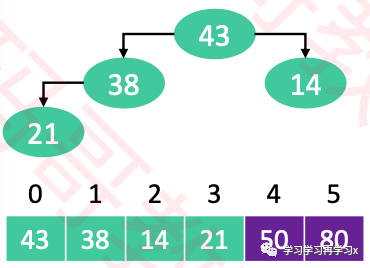
...以此类推
由于需要将所有的排序分布在不同的类,所以这边我们将代码重构了一下,写了一个Sort的父类包含元素的比较以及元素的交换:
public abstract class Sort { protected Integer[] array; protected int cmpCount; protected int swapCount; public void sort(Integer[] array) { if (array == null || array.length < 2) return; this.array = array; sort(); } protected abstract void sort(); /* * 返回值等于=0,说明相等 * 返回值小于0,代表array[i1] * 返回值大于0,array[i1]>array[i2] */ protected int cmp(int i1, int i2) { cmpCount++; return array[i1] - array[i2]; } protected int cmpElements(Integer v1,Integer v2){ cmpCount++; return v1-v2; } /* * 交换 */ protected void swap(Integer i1, Integer i2) { swapCount++; int tmp = array[i1]; array[i1] = array[i2]; array[i2] = tmp; }让所有的排序继承这个父类(Sort)
堆排序的逻辑很简单:
我们这边运用最大堆(最大的数在堆顶,每个节点的左子树小于该节点,每个节点的右子树大于该节点)
关于如何原地建堆这边不阐述了,这是基本的数据结构
程序代码如下:
public class HeapSort extends Sort{ private int heapSize; @Override protected void sort() { //原地建堆 heapSize = array.length; for (int i = (heapSize>>1)-1; i >=0; i--) { siftDown(i); //将数组中的元素放入堆中 } while (heapSize>1){ //交换堆顶元素和尾部元素 swap(0,--heapSize); //对换上来的元素调整位置siftDown siftDown(0); } } private void siftDown(int index){ Integer element = array[index]; int half = heapSize >>1; while(index int childIndex = (index<<1)+1; Integer child = array[childIndex]; int rightIndex = childIndex+1; if (rightIndex0){ child = array[childIndex = rightIndex]; } if (cmpElements(element,child)>=0) break; array[index] = child; index = childIndex; } array[index] = element;siftDown不多阐述,这是关于堆中调整位置的方法。有兴趣的可以自行查看网上资料
在数据足够多,数据量大的时候,堆排序的优势就非常明显了
时间复杂度:O(nLogn)
空间复杂度:O(1)
堆排序不是一个稳定的排序
插入排序(Insertion Sort)
-
插入排序非常类似于扑克牌的排序

流程
-
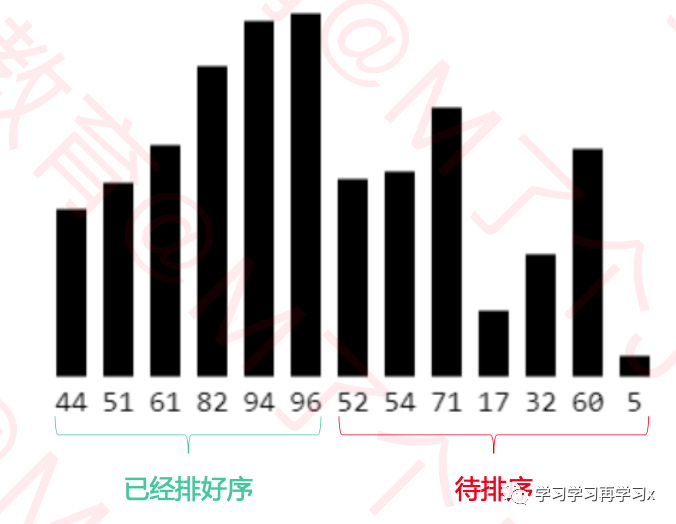
在执行过程中,插入排序会将序列分为两个部分
-
头部是已排好序的,尾部是待排序的
-
从头开始扫描每一个元素
-
每当扫描到一个元素,就将它插入到合适的位置,使得头部数据依然保持有序
代码如下:
for (int begin = 1; begin < array.length; begin++) { int cur = begin; while (cur > 0 && cmp(cur, cur - 1) < 0) { swap(cur, cur - 1); cur--; }}逆序对(Inversion)
-
什么是逆序对?
数组<2,3,8,6,1>的逆序对:<2,1> <3,1> <8,1> <8,6> <6,1>
-
插入排序的时间复杂度与逆序对的数量成正比关
-
逆序对的数量越多,插入排序的时间复杂度越高
最坏、平均时间复杂度:O(n^2)
最好时间复杂度:O(n) (数组完全升序)
空间复杂度:O(1)
插入排序属于稳定的排序
-
当逆序对的数量极少时,插入排序的效率特别高
-
甚至比O(nLogn)级别的快速排序还要快
-
数据量不是特别大的时候,插入排序的效率也是非常好的
优化
-
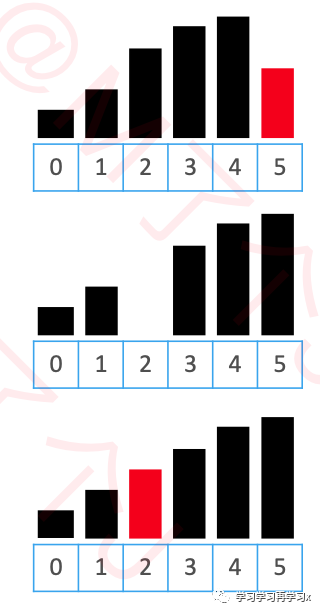
思路是将【交换】转为【挪动】
-
先将待插入的元素备份
-
头部有序数据中比待插入元素大的,都朝尾部方向挪动一个位置
-
将待插入元素放到最终的合适位置
for (int begin = 1; begin < array.length; begin++) { int cur = begin; int v = array[cur]; while (cur > 0 && cmpElements(v, array[cur - 1]) < 0) { array[cur] = array[cur-1]; cur--; } array[cur] = v;}二分搜索(Binary Search)
-
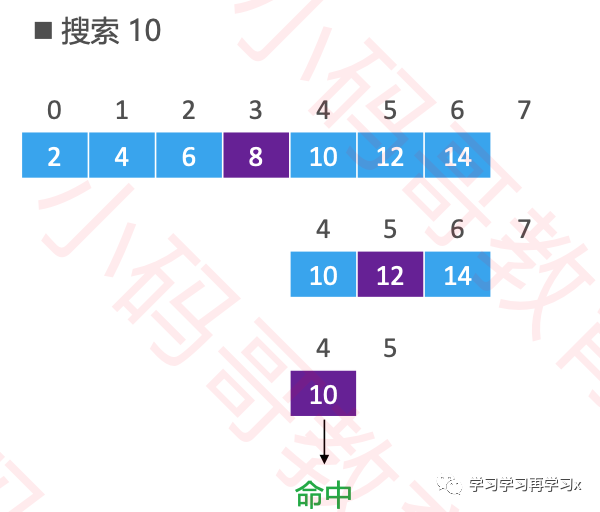
如何确定一个元素在数组中的位置?(假设数组里面全是整数)
-
如果是无序数组,从第0个位置开始遍历搜索,平均时间复杂度:O(n)
-
如果是有序数组,可以使用二分搜索,最坏时间复杂度:O(Logn)
思路
-
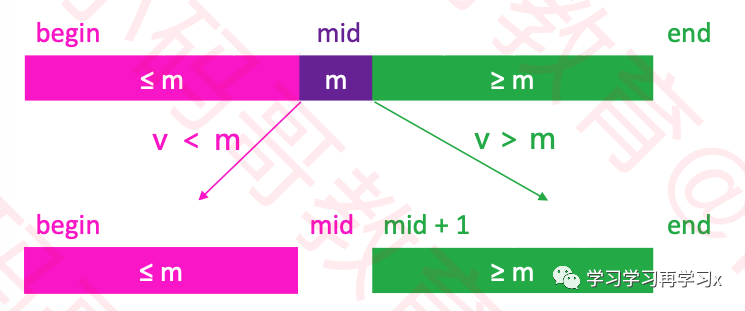
有序数组中在[begin,end]中搜索v这个数,我们需要先找到begin跟end中间的数mid
-
如果v
-
如果v>mid的时候,则可以判断v在[mid+1,end]中,此时把mid+1赋值给begin
-
如果正好v=mid的时候,直接返回
案例:
实现方法
public static int indexOf(Integer[] array, int v) { if (array == null || array.length == 0) return -1; int begin = 0; int end = array.length; while (begin < end) { int mid = (begin + end) >> 1; if (v < array[mid]) { end = mid; } else if (v > array[mid]) { begin = mid + 1; } else { return mid; } } throw new IllegalArgumentException("Not Found");}逻辑比较简单,代码也通俗易懂
但是同时出现了问题,正如上文所说的稳定性问题:如果存在多个重复的值,那么我们二分查找的是哪一个呢?
答案是不确定的,这跟元素的位置有关
>1;"],[20,"\n","24:\"KBKJ\"|36:79|7:0"],[20," if (v> 1;"],[20,"\n","24:\"Z0nU\"|36:79|7:0"],[20," if (cmp(index, mid) < 0) {"],[20,"\n","24:\"JUmJ\"|36:79|7:0"],[20," end = mid;"],[20,"\n","24:\"f2Nm\"|36:79|7:0"],[20," } else {"],[20,"\n","24:\"sD02\"|36:79|7:0"],[20," begin = mid +1;"],[20,"\n","24:\"CYCF\"|36:79|7:0"],[20," }"],[20,"\n","24:\"NCcX\"|36:79|7:0"],[20," }"],[20,"\n","24:\"lDv5\"|36:79|7:0"],[20," return begin;"],[20,"\n","24:\"Y5vW\"|36:79|7:0"],[20,"}"],[20,"\n","24:\"yVGI\"|36:79|7:0"],[20,"\n","24:\"Y8G6\""],[20,"插入排序函数中的循环每次获取到待插入元素需要插入的位置","8:1"],[20,"\n","24:\"AyZE\""],[20,"\n","24:\"x7NN\""],[20,"for (int begin = 1; begin < array.length; begin++) {"],[20,"\n","24:\"7EzZ\"|36:79"],[20," int v = array[begin];//备份一次待插入元素"],[20,"\n","24:\"FFRG\"|36:79"],[20," int insertIndex = search(begin);"],[20,"\n","24:\"tOfZ\"|36:79"],[20," //将(insertIndex,begin)的所有元素向右挪动1个位置"],[20,"\n","24:\"PICk\"|36:79"],[20," for (int i = begin; i >insertIndex ; i--) {"],[20,"\n","24:\"2ImW\"|36:79"],[20," array[i] = array[i-1];"],[20,"\n","24:\"pyHj\"|36:79"],[20," }"],[20,"\n","24:\"WSEY\"|36:79"],[20," array[insertIndex] = v;"],[20,"\n","24:\"cUvn\"|36:79"],[20,"}"],[20,"\n","24:\"57UP\"|36:79"],[20,"\n","24:\"hvpI\""],[20,"需要注意的是,使用了二分搜索后,只是减少了比较次数,但是插入排序的平均时间复杂度还是O(n^2)","8:1"],[20,"\n","24:\"T83u\""],[20,"\n","24:\"wS2z\""],[20,"\n","24:\"Vwog\""]]">二分搜索优化
-
在元素v的插入过程中,我们可以用二分搜索找到合适的位置,再将元素v插入
-
上面所铺垫的二分查找的返回值是数组的index(索引),所以这边可以使用索引的方式插入

-
要求二分搜索返回的插入位置:第一个大于元素v的位置
-
如果v=5,则返回2
-
如果v=1,则返回0
-
如果v=8,则返回5
-
....
-
实例
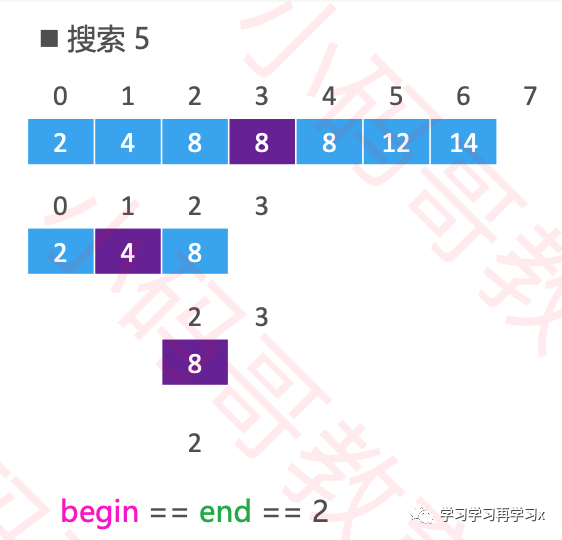
当我们while循环结束后,begin与end的值相等,所以这时候插入位置就是begin/end的值
public static int search(Integer[] array, int v) { if (array == null || array.length == 0) return -1; int begin = 0; int end = array.length; while(begin < end){ int mid = (begin+end)>>1; if (v end = mid; }else{ begin=mid+1; } } return begin;}在排序中使用二分搜索的方法插入元素
/* * 利用二分搜索找到index位置元素的待插入位置 */private int search(int index) { int begin = 0; int end = index; while (begin < end) { int mid = (begin + end) >> 1; if (cmp(index, mid) < 0) { end = mid; } else { begin = mid +1; } } return begin;}插入排序函数中的循环每次获取到待插入元素需要插入的位置
for (int begin = 1; begin < array.length; begin++) { int v = array[begin];//备份一次待插入元素 int insertIndex = search(begin); //将(insertIndex,begin)的所有元素向右挪动1个位置 for (int i = begin; i >insertIndex ; i--) { array[i] = array[i-1]; } array[insertIndex] = v;}需要注意的是,使用了二分搜索后,只是减少了比较次数,但是插入排序的平均时间复杂度还是O(n^2)
第一次写技术文章,有的地方描述的可能不是很清楚,如果有更好的想法或者更加优化的方法,不介意的话可以找作者讨论一下哦?~

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)