Exbody——从MDM、RobotMDM到全身运动控制策略Exbody:上半身模仿人体动捕数据,下半身RL训练
前言
在上一篇文章《OmniH2O——通用灵巧且可全身远程操作并学习的人形机器人(其前身H2O是HumanPlus的重要参考)》中的“2.3节趣味工作:语音指令控制机器人干活与GPT4o加持”时,我们提到
通过将与预训练的文本到人体动作生成扩散模型MDM[57-Human motion diffusion model]连接,实现了通过语音指令控制人形机器人
如下图所示
人类可以描述所需的动作,例如“举起你的右手”,然后MDM生成相应的动作目标,由OmniH2O跟踪「with humans describing desired motions, such as “raise your right hand”. MDM generatesthe corresponding motion goals that are tracked by the OmniH2O」
我个人感觉到很amazing,毕竟确实挺酷的,直接口头让机器人干活
- 语音模型根据人类语音转换成文本
- 然后类似MDM、Momask这样的模型再根据文本生成3D骨骼动画,作为机器人的动作目标
- 然后用训练好的策略 去驱动人形机器人达到该动作目标
我自己都想复现这个工作了..

故,本文来了
第一部分 从Human Motion Diffusion Model、PhysDiff到RobotMDM
1.1 动态扩散模型MDM
22年9月,来自TAU的研究者们通过此篇论文《Human Motion Diffusion Model》提出了运动扩散模型MDM,在该文中,作者通过在无分类器的方式下对CLIP进行条件化来实现文本到动作的转换,类似于文本到图像
如下图所示「运动扩散模型(MDM)通过在给定文本提示的情况下生成多样化的动作,反映了文本到动作映射的多对多特性,其中,较深的颜色表示序列中的较晚帧,即最后生成的帧」

1.1.1 MDM的整体框架与几何损失
MDM的目标是在给定任意条件c的情况下合成长度为N的人体动作x1:N。这个条件可以是任何将决定合成的现实世界信号,例如音频(Li等,2021;Aristidou等,2022)、自然语言(文本到动作)(Tevet等,2022;Guo等,2022a)或离散类别(动作到动作)(Guo等,2020;Petrovich等,2021)
此外,也可以进行无条件的动作生成,此时将其表示为空条件,生成的动作
是由关节旋转或位置
表示的人体姿势序列,其中
为关节的个数,
为关节表示的维数(总之,MDM 可以接受由位置、旋转或两者共同表示的运动,下文还会详述此点)
首先,在整体框架上
扩散建模为马尔可夫噪声过程,,其中
取自数据分布,且有
其中,是常数超参数,当
足够小时,可以得到如此近似
。从这里开始,用
表示在噪声步骤
的完整序列
在该语境中,条件运动合成将分布建模为逐步清理
的反向扩散过程。且不再像 Ho 等人所提出的那样预测
,而是遵循 Ramesh 等人(2022)的方法,直接预测信号本身,即
,其目标是(Ho 等人,2020)
其次,在几何损失上
在运动领域,生成网络通常使用几何损失进行正则化(Petrovich等,2021;Shi 等,2020)。这些损失用于强化物理属性并防止伪影,促进自然和连贯的运动
在这项工作中,作者尝试了三种常见的几何损失来调节(1)位置(在我们预测旋转的情况下),(2)脚部接触,以及(3)速度
如果预测关节旋转,FK(·)表示将关节旋转转换为关节位置的正向运动学函数(否则,它表示恒等函数)。是每一帧
的二进制足部接触掩码。仅与足部相关,它指示它们是否接触地面,并根据二进制真实数据设置(Shi等,2020)。本质上,它通过在接触地面时将速度归零来减轻足部滑动效应
总体而言,训练损失是
1.1.2 MDM的模型架构图
如下图所示

- 在左侧中可以看到该模型的输入总共有两个:一个运动序列
——一个噪声步骤中长度为N的序列,和一个条件编码
但这个条件编码需要先做一定处理,即它一开始是一个基于CLIP(Radford等,2021)的文本嵌入,首先被随机屏蔽以进行无分类器学习「通过使用CLIP(Radford等人,2021)文本编码器将文本提示编码为c来实现文本到运动的转换,并通过每个类别的学习嵌入实现动作到运动的转换」,然后与
一起投影到输入token
中——相当于噪声时间步
The model is fed a motion sequencex1:Nt of length N in a noising step t, as well as t itself and a conditioning code c. c, a CLIP (Radfordet al., 2021) based textual embedding in this case, is first randomly masked for classifier-free learningand then projected together with t into the input token ztk.
且噪声输入xt的每一帧也被线性投影到与transformer相同的维度,并与标准位置嵌入相加。——即在在每个采样步骤中,transformer编码器预测最终的干净运动
- 在右侧则是采样MDM
给定一个条件,然后从T迭代到1。在每个步骤
具体而言,根据Ho等人(2020)的说法,从进行采样是以迭代的方式完成的
在每个时间步,然后将其重新加噪至
这一过程从开始重复,直到获得
且使用无分类器引导法训练我们的模型G(Ho & Salimans,2022),在实际操作中,G通过随机设置
来学习有条件和无条件的分布,这占样本的10%,使得
可以近似
// 待更
1.2 PhysDiff
1.3 RobotMDM
第二部分 UC San Diego的Exbody:全身运动控制
2.1 提出背景与相关工作
2.1.1 提出背景与其定义
如Exbody原论文所说,虽然基于物理的角色动画可以产生在虚拟环境下看起来自然、具有良好反应性的控制策略,但这类结果往往需要极高的执行器增益,通常在60kg/m范围内,这比当前硬件可实现的水平高出一个数量级
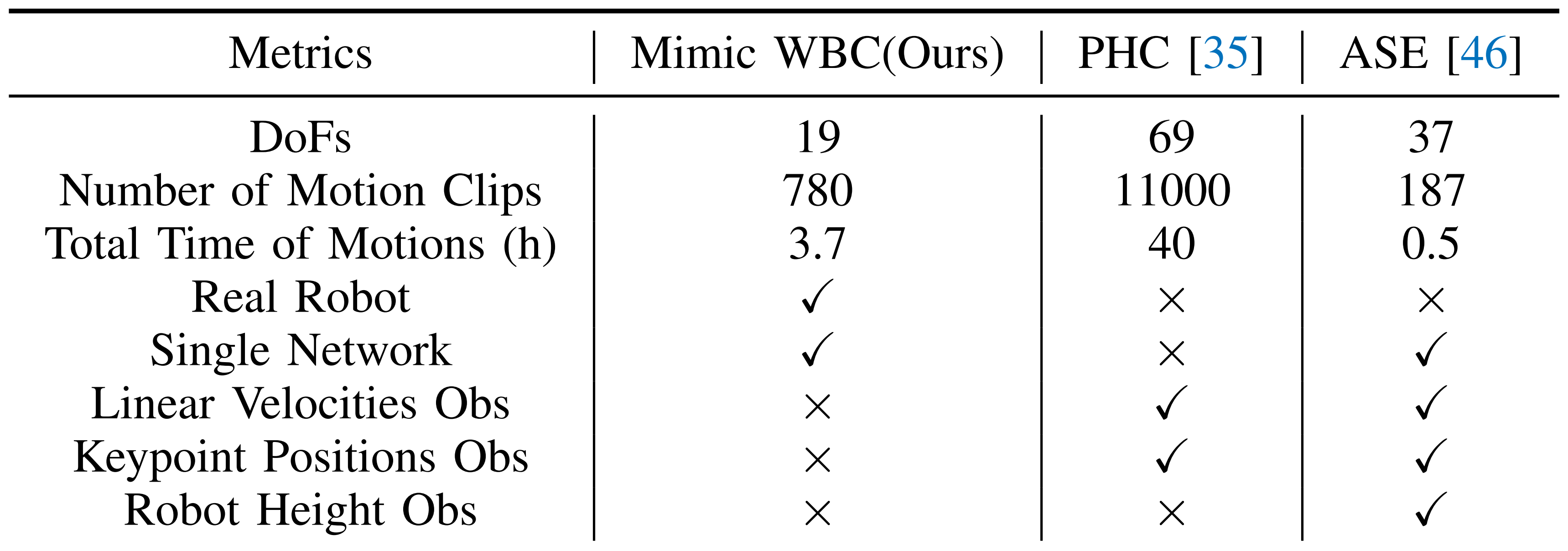
且作者还发现,人类参考动作往往涉及更多的自由度(DoF),远超机器人硬件所具备的。例如,基于物理的动画可以使用更多的自由度『例如,69个自由度[35]』,而真实世界中的机器人(例如,Unitree H1)仅有19个自由度
24年2月初,UC San Diego提出了一种面向人形机器人的全身运动控制策略Exbody,其对应的论文为《Expressive Whole-Body Control for Humanoid Robots》
- 其将来自图形学领域的大规模人体动作捕捉数据与深度强化学习(RL)相结合,在仿真环境中进行训练,从而生成可直接部署于真实机器人上的全身控制器
- Exbody的核心思想是不完全模仿参考动作。他们提出了一种新颖的控制器训练方法,该控制器以参考动作和根部移动指令作为输入,用于真实的人形机器人控制「We propose to train a novel controller that takes both a reference motion and a root movement commandas inputs for real humanoid robot control」
他们将这种方法称为表达性全身控制(Expressive Whole-Body Control,简称ExBody)
在使用RL进行训练时,鼓励人形机器人的上半身模仿多样化的人类动作以增强表现力,同时放松对其双腿的动作模仿要求
- 具体来说,双足行走的奖励函数被设计为稳健地跟随由参考动作提供的根部移动指令,而不是精确匹配每一个关节角度
且在高度随机化且具有挑战性的地形仿真中训练策略。这不仅实现了稳健的仿真到现实迁移,还学习得到一种不仅仅“重复”给定动作的策略
用户可以指令人形机器人以不同速度移动,在多样地形上朝不同方向转弯,同时上半身重现参考动作
如图1所示,可以让机器人与人类一起跳舞,在行走时挥手和握手,或在复杂地形上像木乃伊一样行走
- 作者在模拟和现实实验中采用了Unitree H1机器人
且为了从多样化的人类动作中学习,使用了CMU的MoCap数据集(大约包含780个参考动作)。这种丰富性不仅使得人形机器人动作更具表现力,也使得行走更加稳健
他们认为他们的结果表明,ExBody的方法通过放宽约束确实能够带来更好和更稳健的结果
2.1.2 相关工作
第一方面,对于全身控制与腿式机器人
腿式机器人在完成舞蹈、远距离抓取等任务或动作时,通常需要协调全身
- 这些动作以前主要通过动力学建模和控制来实现
40-Dynamic walk of a biped
61-Simbicon: Simple biped locomotion control
21-Anymal-a highly mobile and dynamic quadrupedal robot
41-Whole-body control of humanoid robots
9-Whole body humanoid control from human motion descriptors
26-The 3d linear inverted pendulum mode: A simple modeling for a biped walking pattern generation
57-Hybrid zero dynamics of planar biped walkers
然而,对于具有高自由度的人形机器人
17-Mabel, a new robotic bipedal walker and runner
27-Development of wabot
20-The development of honda humanoid robot
7-The mit humanoid robot: Design,motion planning, and control for acrobatic behaviors
2-Boston Dynamics
1-Agility Robotics
这将需要大量的工程和建模[51-A compliant hybrid zero dynamics controller for stable, efficient and fast bipedal walking on mabel],并且对真实世界的动力学变化非常敏感 - 最近针对四足机器人的基于学习的方法
15-Deep whole-body control: learning a unified policy for manipulation and locomotion
22-Efficient multitask learning with an embodied predictive model for door opening and entry with wholebody control
5-Legs as manipulator: Pushing quadrupedal agility beyond locomotion
23-Learning wholebody manipulation for quadrupedal robot
48- Curiositydriven learning of joint locomotion and manipulation tasks
25-Dribblebot: Dynamic legged manipulation in the wild
24-Hierarchical reinforcement learning for precise soccer shooting skills using a quadrupedal robot
实现了全身运动和操作能力
这些进展同样促进了基于学习的人形机器人控制
29-Words into action: Learning diverse humanoid robot behaviors using language guided iterative motion refinement
52-Humanmimic: Learning natural locomotion and transitions for humanoid robot
via wasserstein adversarial imitation
31- Robust and versatile bipedal jumping control through multi-task reinforcement learning
49-Deep imitation learning for humanoid loco-manipulation through human teleoperation
然而,大多数研究更侧重于机器人行走或学习相对较小的数据集
与之前的所有工作不同,Exbody的研究实现了在现实世界中,类人生机器人可进行全身控制以表现富有表现力的动作
第二,对于崎岖地形的研究
崎岖地形的研究已经被广泛开展
- 包括通过奖励规范化
39- Rapid locomotion via reinforcement learning
28-Rma: Rapid motor adaptation for legged robots
14-Minimizing energy consumption leads to the emergence of gaits in legged robots
13- Learning deep sensorimotor policies for vision-based autonomous drone racing
模仿学习[11-Adversarial motion priors make good substitutes for complex reward functions]
以及步态启发式[30-Reinforcement learning for robust parameterized locomotion control of bipedal robots,50-Blind bipedal stair traversal via sim-to-real reinforcement learning]的方法
另,基于视觉的运动已经在跨越楼梯
4- Legged locomotion in challenging terrains using egocentric vision
60-Neural volumetric memory for visual locomotion control
38- Learning to jump from pixels
10-Learning vision-based bipedal locomotion for challenging terrain
征服跑酷障碍[63-Robot parkour learning,6-Robot parkour learning]
操控箱体[8-Sim-to-real learning for humanoid box loco-manipulation]
等方面取得了巨大成功 - 然而,这些工作尚未完全利用示范数据。即使是利用重新定位的动物运动或预优化轨迹的工作,仍然使用了非常小的数据集
[43- Learning agile robotic locomotion skills by imitating animals
56-Amp in the wild: Learning robust, agile, natural legged locomotion skills
11-Adversarial motion priors make good substitutes for complex reward functions
16-Opt-mimic: Imitation of optimized trajectories for dynamic quadruped behaviors
59-Generalized animal imitator: Agile locomotion with versatile motion prior]
而Exbody的框架能够受益于大规模动作数据集的学习
第三,基于物理的角色动画
全身类人动作控制在计算机图形学领域得到了广泛研究,其目标是生成逼真的角色行为
- 诸如[45, 46, 53, 19]之类的对抗方法随着动作越来越多会出现模式崩溃的问题。Peng 等人[46]使用单位球体潜在空间来表示 187 种动作
然而,它仍然存在模式崩溃的问题,并且利用了额外的技能发现目标 - 基于模仿的方法[58, 55, 62, 42]通过 “解耦控制和动作生成” 来缓解此问题,其中训练了一个通用的动作跟踪控制器来跟踪任何动作,而动作生成器则输出要跟踪的动作
mitation-basedmethods [58, 55, 62, 42] alleviate this problem by decoupling control and motion generation, where a general motion track-ing controller is trained to track any motions and a motion generator outputs motions to track.
这些工作展示了成功转移到真实的机器人四足动物[44,11]
[58]将整个CMU MoCap数据分成几个簇,并训练专家混合策略以再现整个数据集的物理上合理的控制器
Luo等人[35]通过逐步分配新网络来学习新动作,使用了类似的想法 - 然而,这些方法很难转移到真实的人形机器人,因为不现实的角色模型『SMPL人形模型[33]总共有69个自由度,23个球形关节被驱动,每个关节有3个自由度,通常没有扭矩限制』,以及使用了仿真环境中的特权信息(机器人世界坐标、速度等),如表 I 所示
因此,作者提出了表达性全身控制以解决此问题。ExBody 放宽了下半身跟踪目标,而是使用了全身根部运动目标
且考虑到机器人的能力,他们选择了一组运动,主要包括步行、日常行为和表情,并且只使用一个单一的网络来处理所有运动
2.1.3 问题定义:根部运动控制与Expressive Whole-Body Control
作者将人形运动控制视为学习一个目标条件的运动策略
其中
是指定行为的目标空间,S 是观察空间,A 是包含关节位置和扭矩的动作空间
- 在本文的其余部分假设,在不失一般性的情况下,观察空间和动作空间由H1 人形机器人设计给出
且作者声明,他们认为他们提出的方法应该可以推广到类似的身体形式,即使它们在具体的驱动自由度数量上有所不同
一方面,是基于指令的行走控制(Command-conditioned Locomotion Control)——根部运动控制
作者的的目标是为 Unitree H1 硬件生成一个稳健的控制策略,该策略能够通过线性速度、以横滚/俯仰/偏航
表示的机身姿态,以及在根链接处测量的机身高度
来进行指令控制
形式上,根部运动控制的目标空间为
- 观测
包括机器人的当前本体感知信息
是机器人根部的角速度,
,
分别是横滚和俯仰
注意,策略并未观测当前速度、绝对身体高度
以及当前偏航角
,因为这些是对真实机器人来说的特权信息
如下表1所示,在 PHC中,策略观察每个刚体的线速度Linear velocities和关键点位置keypoint positions,而在 ASE 中,线速度仅针对根部root。PHC 和 ASE都观察到在真实机器人上不可用的特权状态- 且作者让策略观察当前偏航角与期望偏航角之间的差异
,以将全局量转换为局部框架,从而可以在部署时直观地指令
- 动作
是关节级比例-微分(PD)控制器的目标位置
PD 控制器使用指定的PD 增益和阻尼系数
计算每个电机的扭矩
二方面,是富有表现力的全身控制(Expressive Whole-Body Control,ExBody)
作者将命令调节的运动控制扩展为包含机器人运动的描述,这些描述未被 中的根姿态和速度捕获
故作者将其表述为更通用的目标空间,其中表达目标
包括期望的关节角度和身体的各种3D 关键点位置
具体来说,在这项工作中,作者处理一个放宽的问题,其从 中排除了身体下半部分的关节和关键点。这是因为机器人与人类的身体结构不同,包含来自人体运动捕捉数据的下半身特征往往会使问题过于受限,导致控制策略脆弱且性能较差
形式上,对于本文的其余部分,使用
其中
是上半身九个执行器的关节位置
是两个肩膀、两个肘部以及左右手的3D 关键点
表达性全身控制ExBody的目标是同时跟踪:根部运动目标(针对全身),以及表达式目标(针对上半身)
『The goal of expressive whole-body control (ExBody)is to simultaneously track both the root movement goal (for the whole body) gm ∼Gm, as well as the target expression goal (for upper body) ge ∼Ge』
2.2 表达式全身控制ExBody
如下图图2所示
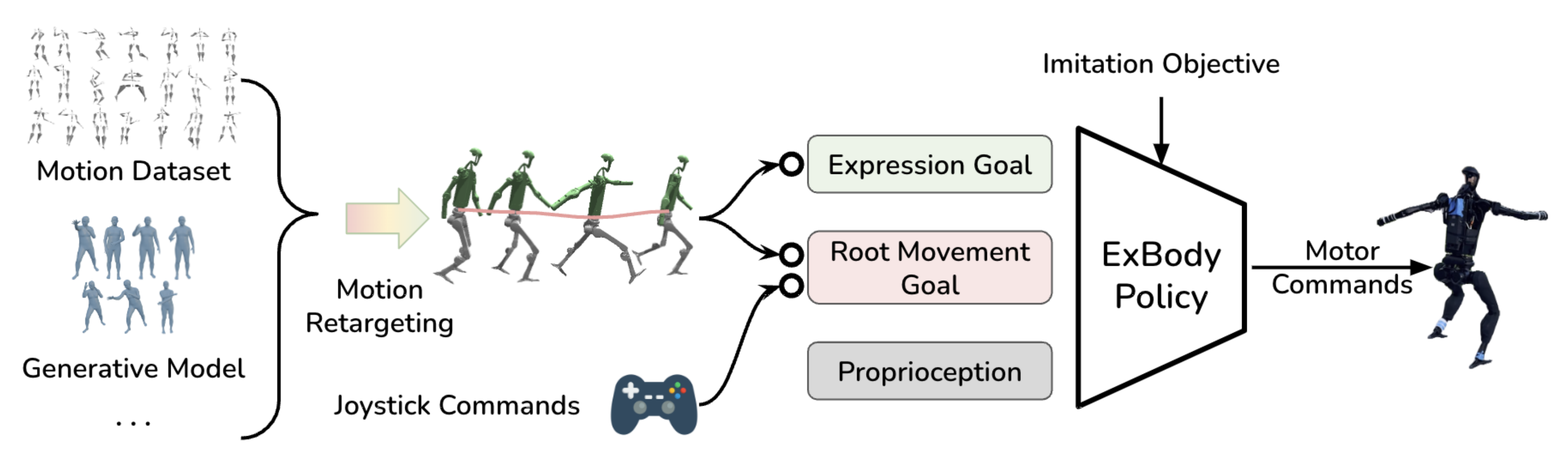
- 框架能够使用来自多种来源的数据进行训练,例如静态人体运动数据集、生成模型、视频到姿态模型等,这些资源广泛可用
- 在运动重定向之后,获得了一系列与机器人运动学结构兼容的运动片段
且作者从重定向的运动片段的丰富特征中提取表达目标和根部运动目标
,作为“目标条件强化学习目标”的目标
We extract expression goal ge and root movement goal gm from the rich features from retargeted motion clips as the goal of our goal-conditioned RL objective.
根部运动目标
在接下来的章节中,将介绍该方法的关键组成部分,包括针对类人机器人硬件对人体动作捕捉数据的精心筛选与重定向策略,以及如何利用这些先验知识提升强化学习训练过程的效果
2.2.1 人类行为数据的筛选策略
如ExBody原论文所说,作者从CMU MoCap数据集中有选择性地使用了一部分数据,排除了涉及与他人、重物或崎岖地形发生物理交互的动作
且由于ExBody框架无法真实地实现与环境有显著交互的动作,因此该过程是半自动完成的。最终所得的动作如表II所示
// 待更

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 29
29 0
0- 0



 已为社区贡献76条内容
已为社区贡献76条内容

所有评论(0)