一小时部署AI大模型聊天机器人
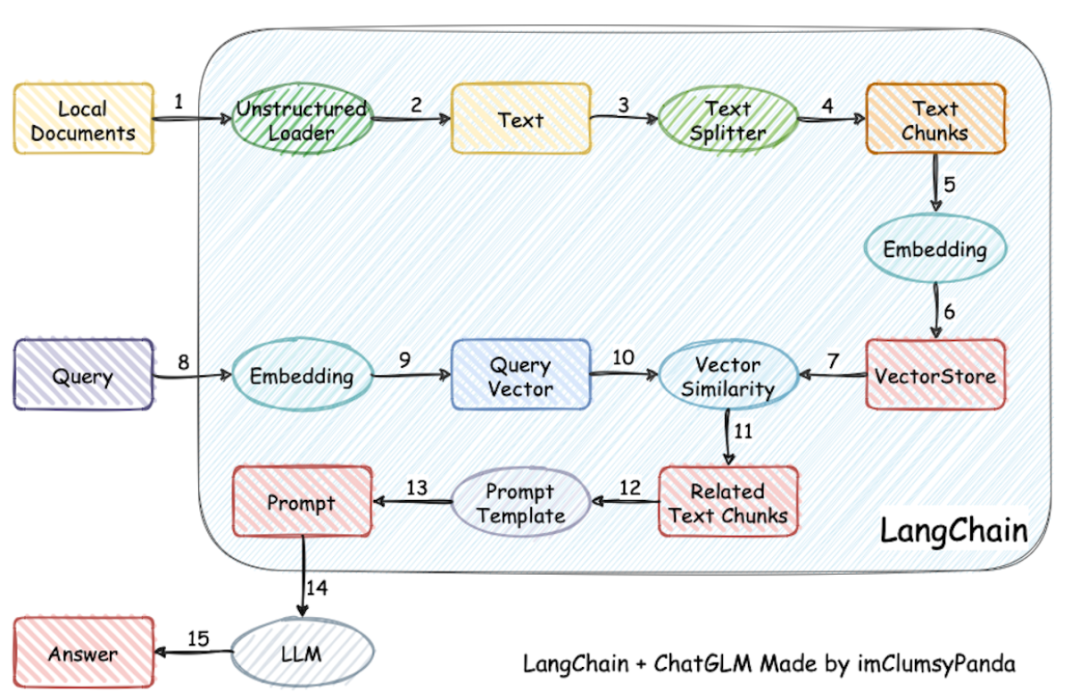
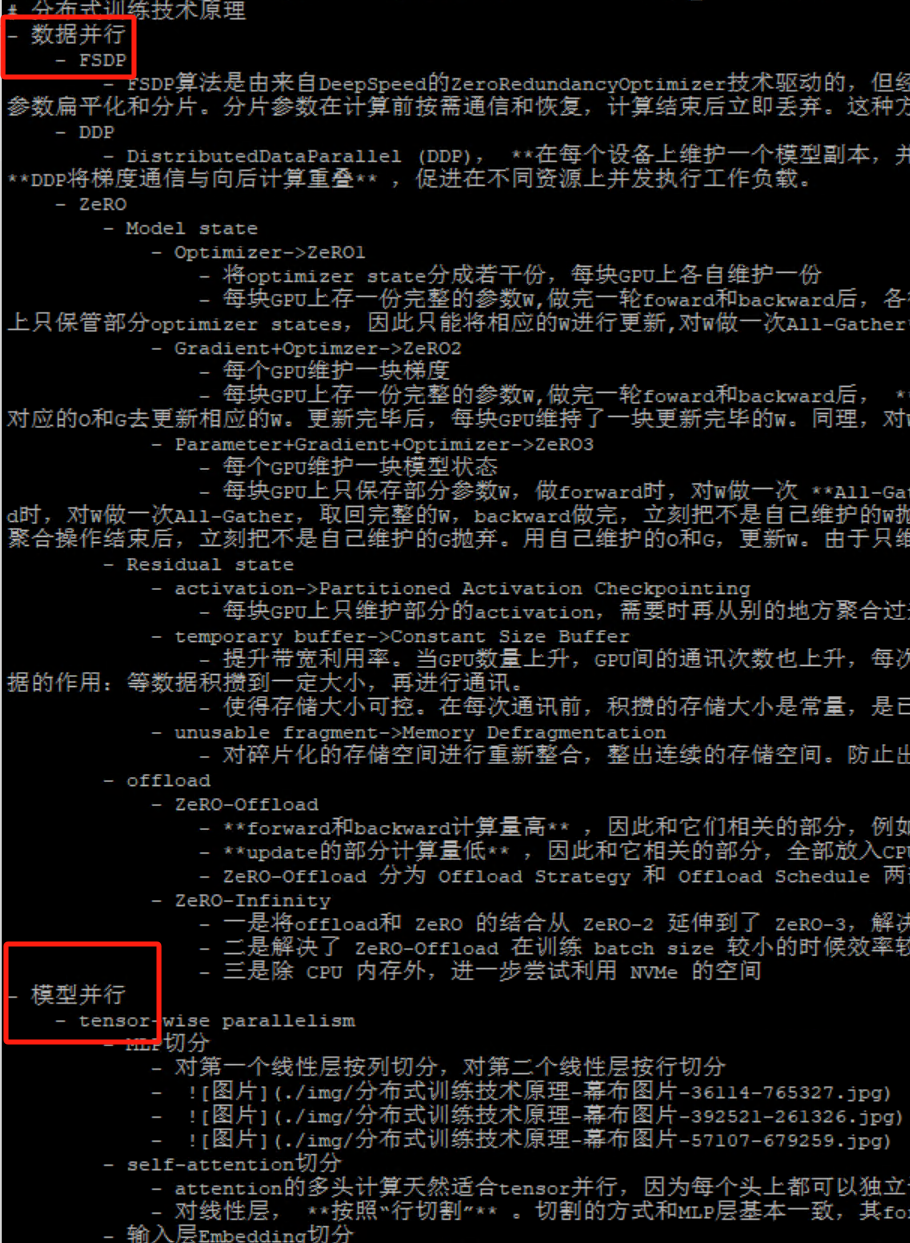
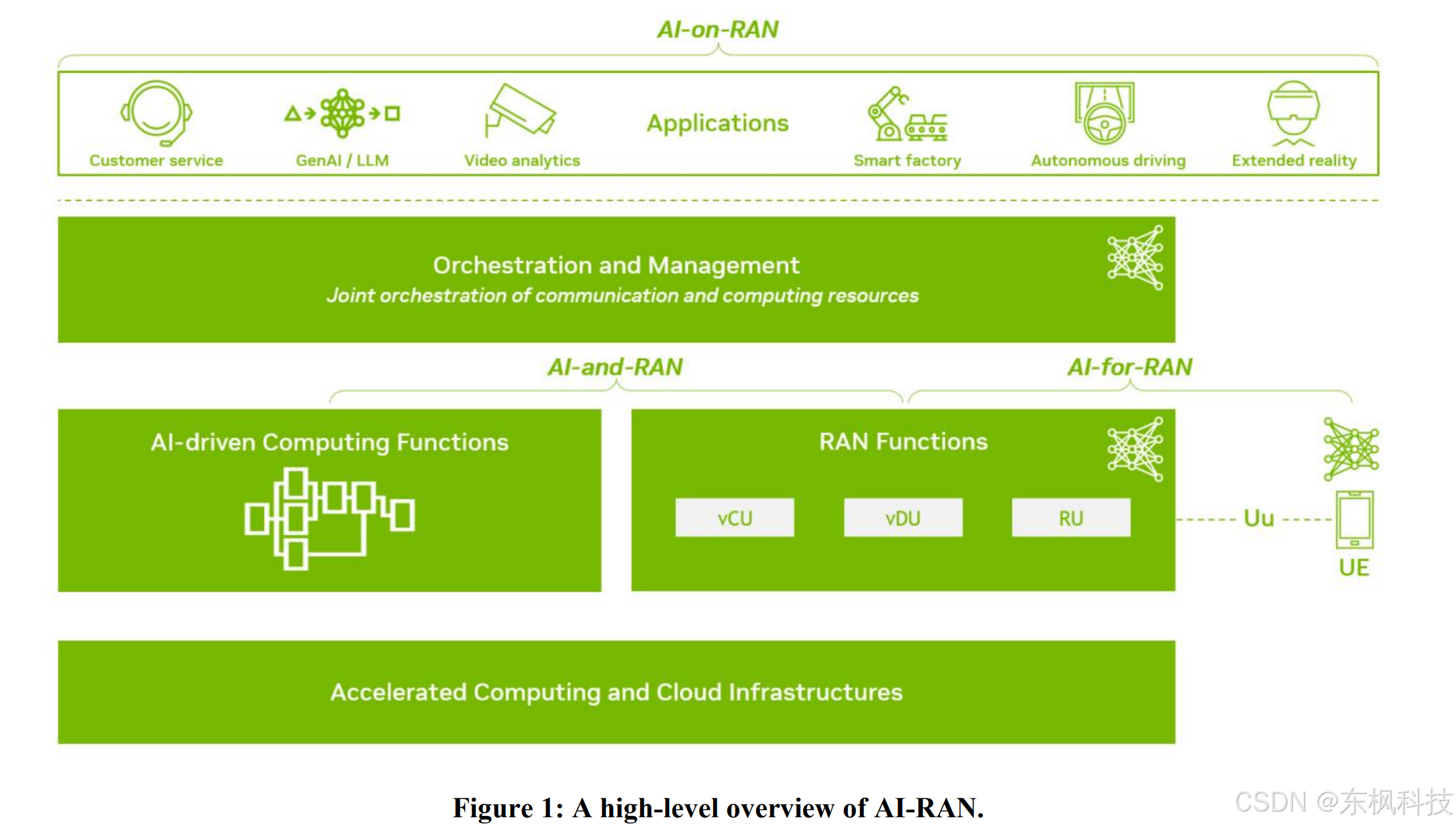
开源项目https://github.com/chatchat-space/Langchain-Chatchat,一个基于Langchain与ChatGLM等语言模型的本地知识库问答,主要优点包括:支持使用本地部署的主流大模型,也支持访问在线大模型RAG知识库支持主流的开源向量数据库包含Web UI,部署后即可在网页进行聊天包含API Server,部署后即提供可调用的API接口图4是其原理,和R
大模型火,关键得把模型用起来,我们见到最多的形态是聊天,ChatGPT一开始爆发也是始于聊天,就像和真人聊一样,今天我们用大模型来快速部署一个聊天机器人系统。
现在大模型领域可以分为两个方向,一是做基座大模型,比如OpenAI做GPT系列、智谱AI、月之暗面的Kimi、百川大模型、MinMax大模型、百度文心一言、阿里通义千问等;二是在基座模型上做应用,这方面见到最多的字眼就是RAG、Agent。
我们要部署的聊天系统,就是在基座模型上做应用,现在这方面开源框架很多,且越来越成熟,没必要重新造轮子,选择好的框架使用就好了,这次我们使用的是Langchain-Chatchat,一个github上已经26k星的项目https://github.com/chatchat-space/Langchain-Chatchat。
鉴于大多数大模型应用系统都使用了RAG和Agent,作为必要铺垫,我们先简要介绍RAG、Agent以及实现RAG的流行框架Langchain,最后看看搭建聊天系统的整个过程。
1 RAG
全称Retrieval-Augmented Generation。我们知道大模型并不是万能的,如果是使用通用知识比如维基百科等训练的模型,它只拥有通用知识,要用它来回答一个公司内特有的一些专业问题是回答不上来的,或者由于知识不足会产生一本正经瞎说的幻觉,RAG通过在大模型基础上增加额外的知识库,在问的问题中加入更丰富的上下文,可以让大模型回答更准确。
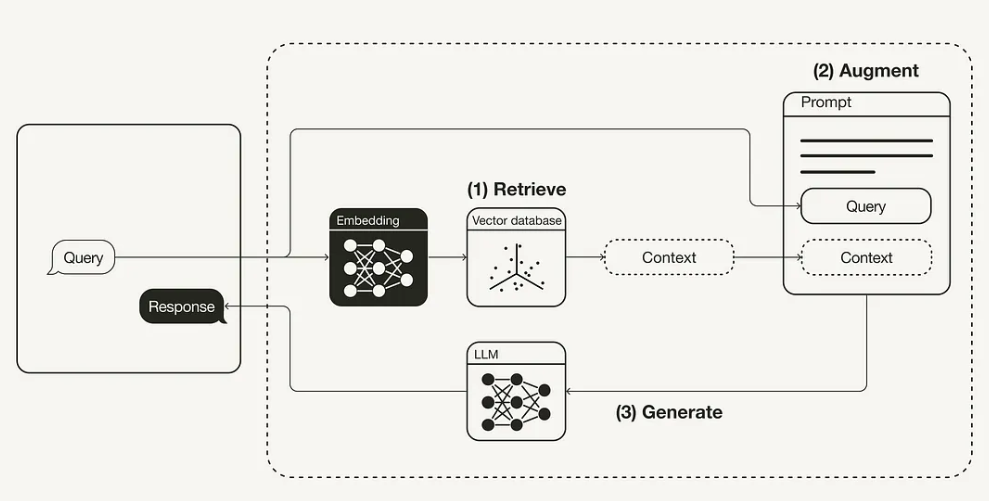
图1 RAG原理图,来源[1]
具体原理和流程如图1,首先我们要提前把大模型之外额外的知识,比如公司内部各种pdf、word、text文本文件、图片等通过向量化的形式存到向量数据库(上图的Vector database)中,具体需要使用能和大模型匹配的向量化模型来进行向量化,向量化模型也称为Embedding模型。然后当我们对系统问问题的时候,整体流程如下:
-
Retrieve,获取:拿着query问题去向量数据库查询相关的知识,比如通过相似度函数,得到前n个相关的数据,即图1中的context;
-
Augment,增扩:把query和context合并在一起,组成新的prompt问题,如何合并就看具体的大模型何种形式的prompt效果好;
-
Generate,生成:把#2中合并后的prompt传入大模型,得到答案。
2 AI Agent
RAG可以提供额外的知识库用于构造prompt输入大模型,但还是受限于大模型本身的能力,比如大模型不擅长的数学计算、实时天气预报等,使用RAG也没有用。AI Agent这时就排上用场了。
系统收到请求后先进行判断,如果要进行数学计算,把这个任务交给计算器,如果要预报天气,把任务交给天气预报系统,最后汇总结果后再统一返回,该使用大模型的时候使用,不是它擅长的事安排其他组件来处理。
这个具有自主理解、规划、执行能力的智能实体就是AI Agent,它一般包含记忆(Memory)、Planning(规划)、一系列工具(Tools)、行动(Action)。下图2是从基本的直接使用大模型,到RAG、AI Agent的一个进化示意图。
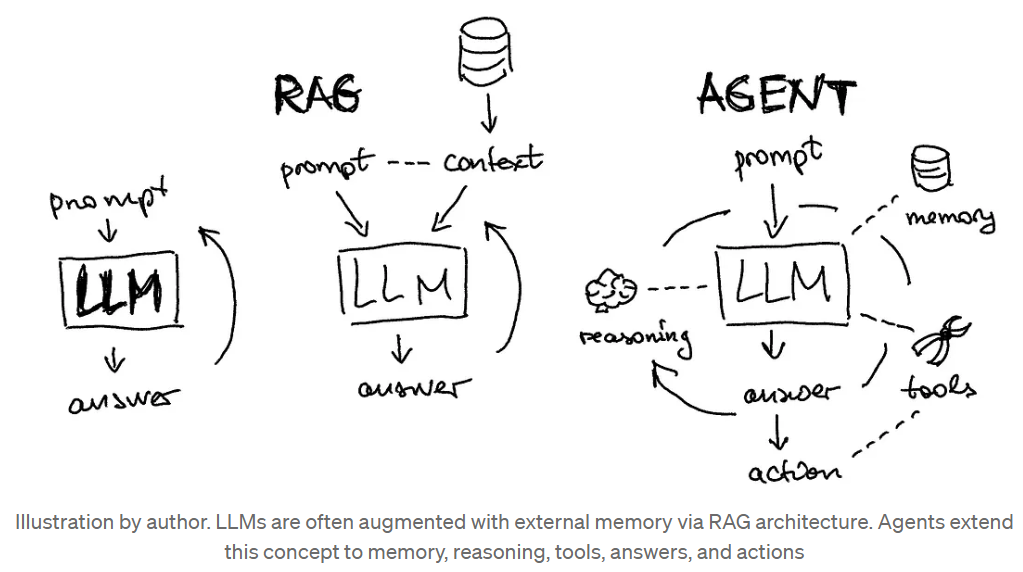
图2. 从LLM、RAG到Agent
3 LangChain
基于大模型的系统,不得不说一下LangChain,其官方定义是基于大模型开发应用的一个框架,是当前最流行的框架之一。图3是其最新版的架构图,能满足整个应用开发、部署、监控各阶段的支持,包括了RAG和Agent相关的组件,基于这些组件能快速实现系统各节点链接,LangChain中的Chain的含义就是把各组件链接起来。
今天我们要安装使用的LangChain-ChatChat看名字就知道是基于LangChain开发的,所以有必要介绍一下,但LangChain不是本文的重点,需要进一步学习的请到官网其https://www.langchain.com/。
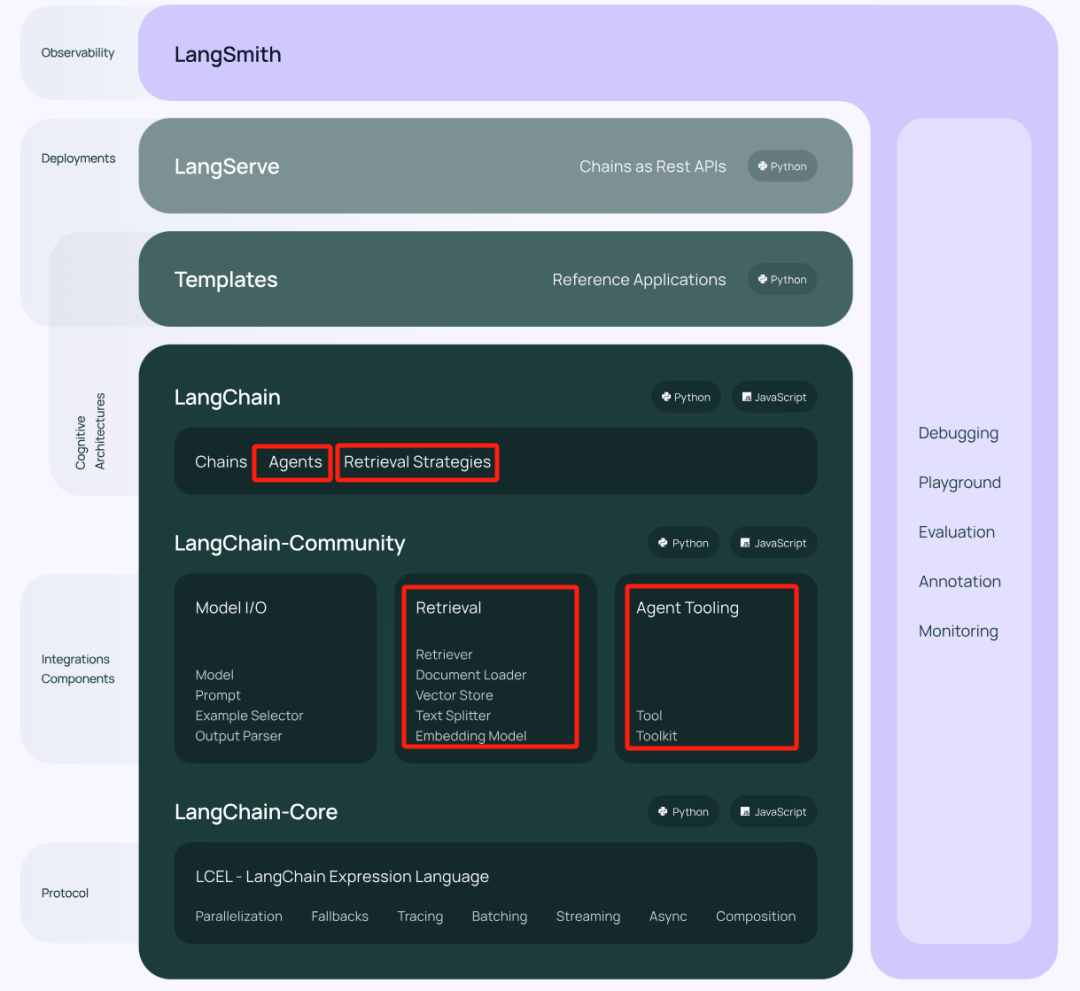
图3. LangChain架构图
4 LangChain-ChatChat部署实战
从这儿开始进入今天的重点,部署LangChain-ChatChat实现一个大模型聊天机器人。如果需要的模型提前下载好,有python环境使用的基本经验,1个小时部署好没有问题!
LangChain-ChatChat介绍
开源项目https://github.com/chatchat-space/Langchain-Chatchat,一个基于Langchain与ChatGLM等语言模型的本地知识库问答,主要优点包括:
-
支持使用本地部署的主流大模型,也支持访问在线大模型
-
RAG知识库支持主流的开源向量数据库
-
包含Web UI,部署后即可在网页进行聊天
-
包含API Server,部署后即提供可调用的API接口
图4是其原理,和RAG一样,只不过细化了文本知识向量化的部分。
图4. LangChain-ChatChat原理图
准备文件
需要准备要使用的大模型和向量化使用的Embedding模型。主流模型都支持,具体列表见https://github.com/chatchat-space/Langchain-Chatchat/wiki/。本实验主要体验演示流程,GPU资源有限,大模型使用的THUDM/chatglm2-6b-int4,由于是int4量化的模型,GPU只需要6G,一般显卡都可实现,Embeding模型使用BAAI/bge-large-zh-v1.5,不缺GPU资源的请下载你心仪的模型。
模型都在huggingface下载,由于国内不能直接访问huggingface,可以到其镜像https://hf-mirror.com/通过以下命令下载。
git lfs install
git clone https://hf-mirror.com/THUDM/chatglm2-6b-int4
git clone https://hf-mirror.com/BAAI/bge-large-zh-v1.5
可能会遇到使用上述git命令下载模型大文件卡住的情况,可以直接到网页上下载,上述两个模型下载后放到一个目录中,一会儿需要使用这个目录路径。
图5. 可直接到网页下载大文件
准备环境
安装python3.8-3.11环境,默认认为你会装这个,然后下载Langchain-Chatchat源码,安装其依赖的python包。
# 拉取仓库
$ git clone https://github.com/chatchat-space/Langchain-Chatchat.git
# 进入目录
$ cd Langchain-Chatchat
# 安装全部依赖
$ pip install -r requirements.txt
如果速度慢,建议使用阿里云的python包镜像,会快很多,如下:
pip install -i https://mirrors.aliyun.com/pypi/simple/ -r requirements.txt
配置模型参数
先运行下面命令备份初始的配置文件:
$ python copy\_config\_example.py
可以看到,命令把每个xxx_config.py.example拷贝了一份xxx_config.py,我们只需要配置xxx_config.py即可。
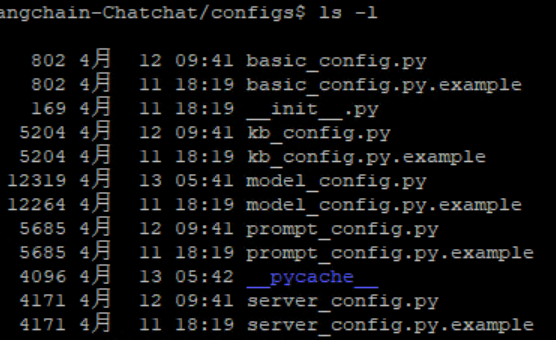
图6. 配置文件列表
最简单的情况,我们只需配置model_config.py中大模型和Embedding模型名称和位置,其他关于知识库kb、prompt的配置可以保持默认值,高级配置暂不研究。
如下图7,MODEL_ROOT_PATH的值设为保存大模型和Embedding模型的目录绝对位置,EMBEDDING_MODEL设为Embedding模型名,本实验为bge-large-zh-v1.5,LLM_MODELS设为大模型名列表,系统会依次寻找,本实验为chatglm2-6b-int4,LLM _DEVICE设为cuda使用GPU推理。
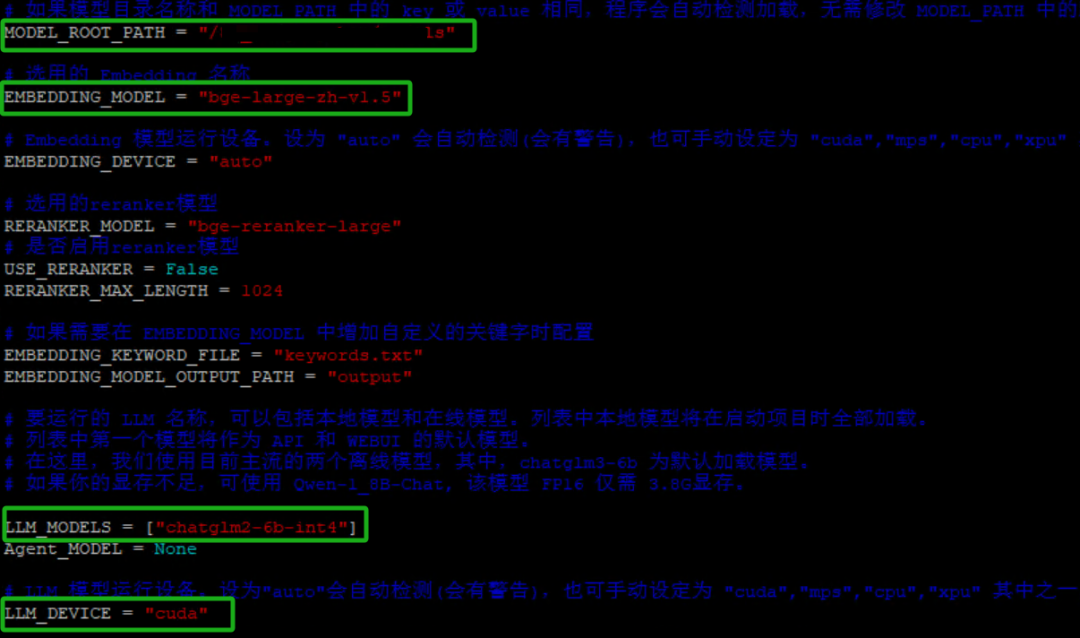
图7. 模型位置和名称配置
初始化数据库
$ python init\_database.py --recreate-vs
可以看到该命令把项目下面的一些样例文件添加到了向量数据库,就是RAG的知识库。
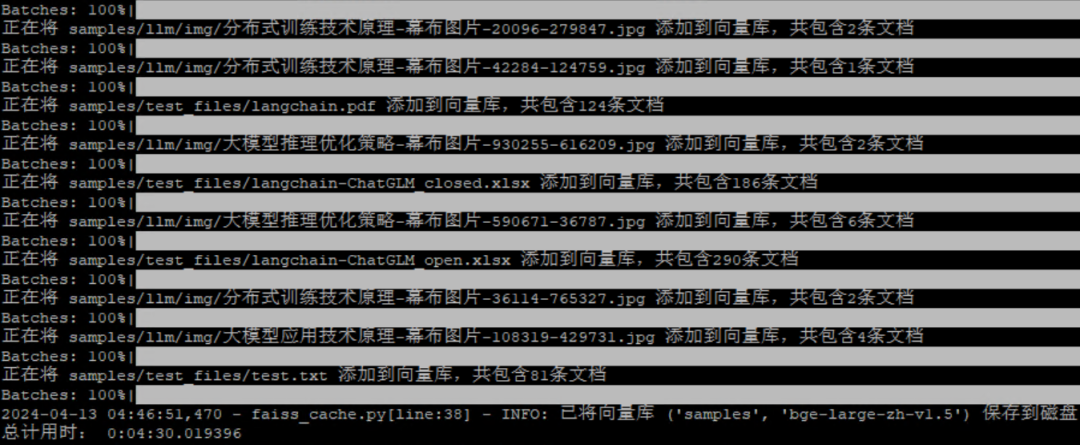
图8. 初始化数据库
启动服务
可使用环境变量指定要用的GPU号,也可以在start.py中的args.gpus参数设置,比如我用1号GPU,可用如下命令:
$ CUDA\_VISIBLE\_DEVICES=1 python startup.py -a
我使用的int4量化模型,第一次由于缺cpm_kernels包报如下错误:

pip安装后就顺利启动了:
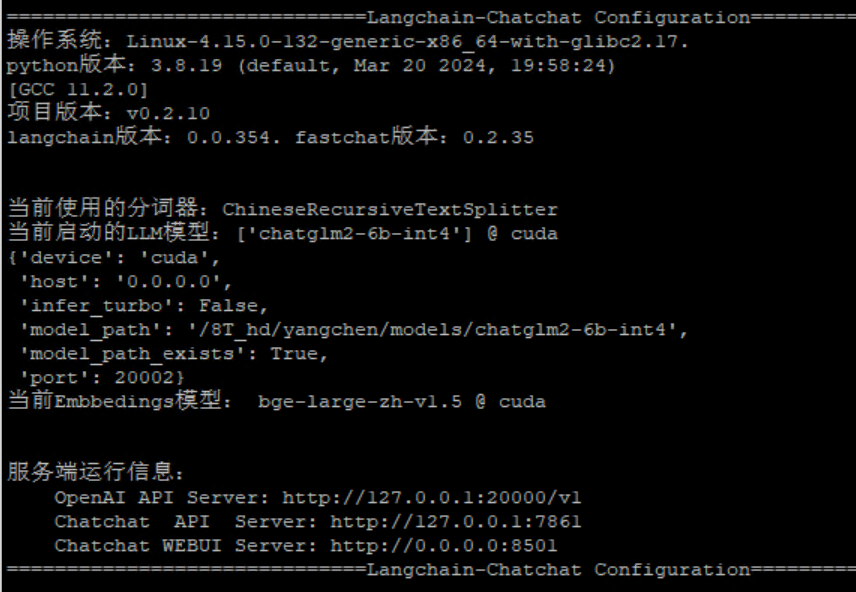
图8. 启动成功
可以看到Web UI和API Server都已就绪,此时看GPU只使用了5.5G显存!
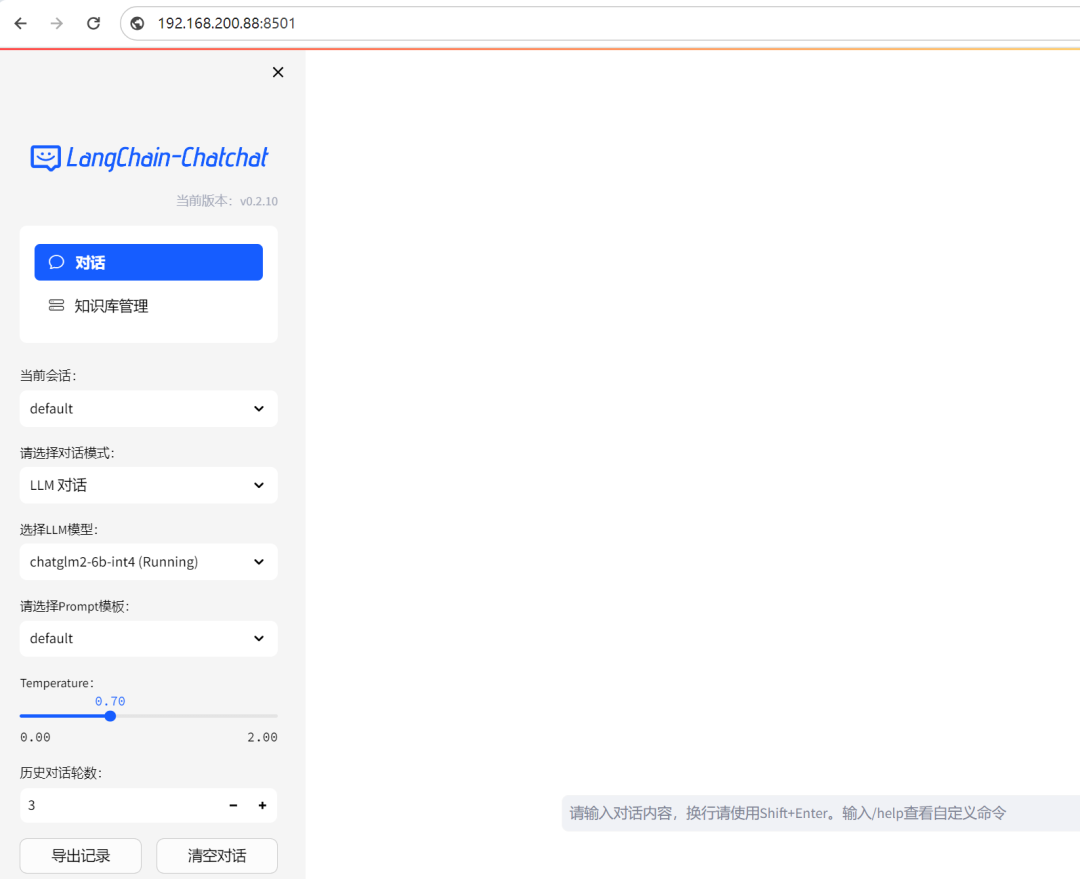
看看效果
打开web UI地址,漂亮,熟悉的聊天界面出来了:
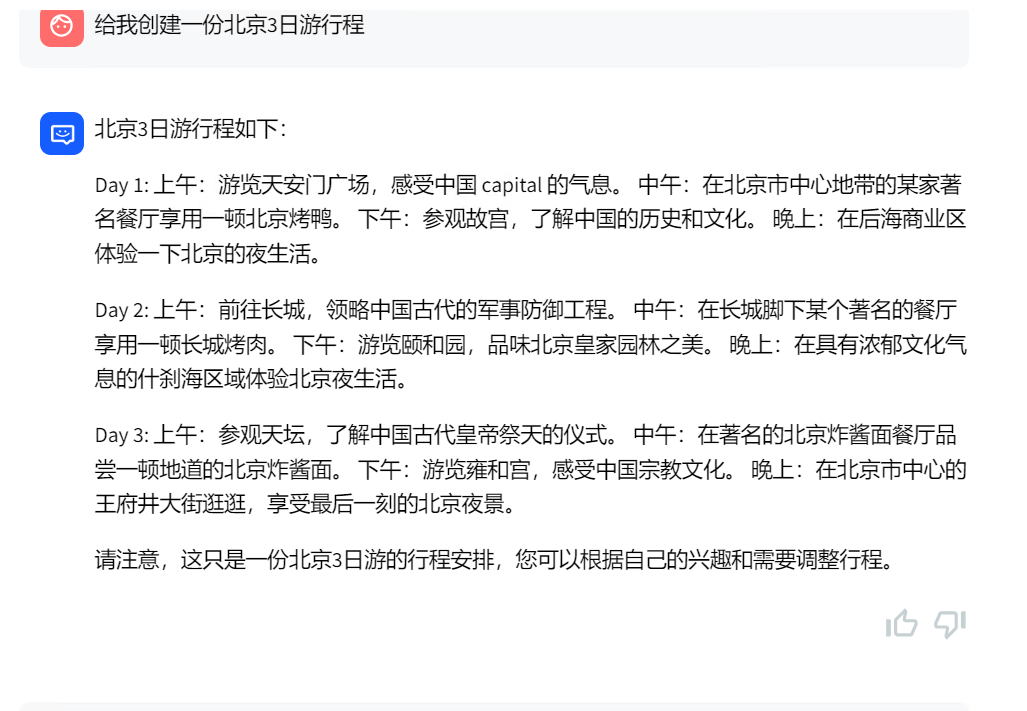
先来个简单的问题试试,6B大小Int4量化模型效果也不错啊:

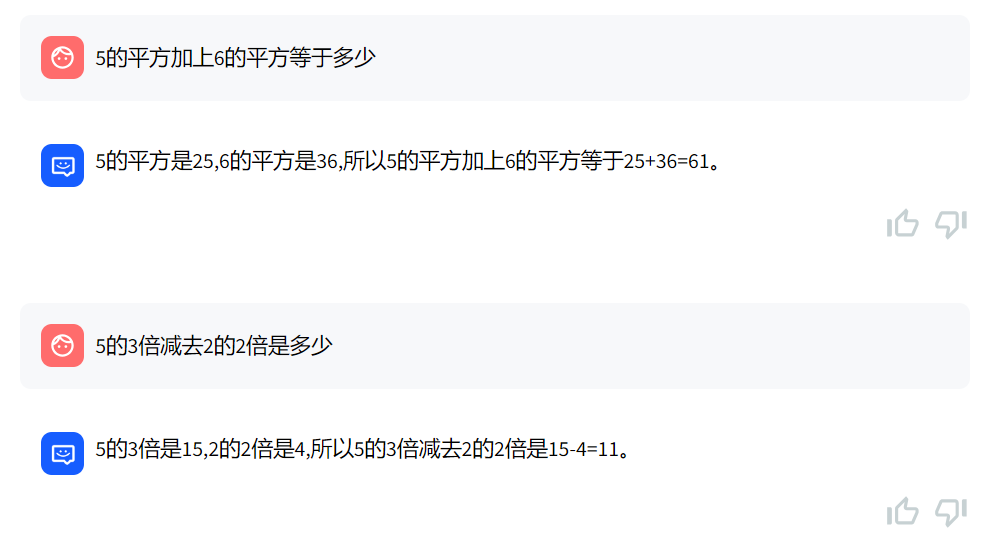
做下数学题,也不错:
做个脑筋急转弯,就不太行了,但好玩,同时说明支持多轮回答的,记住了上一次的问题:
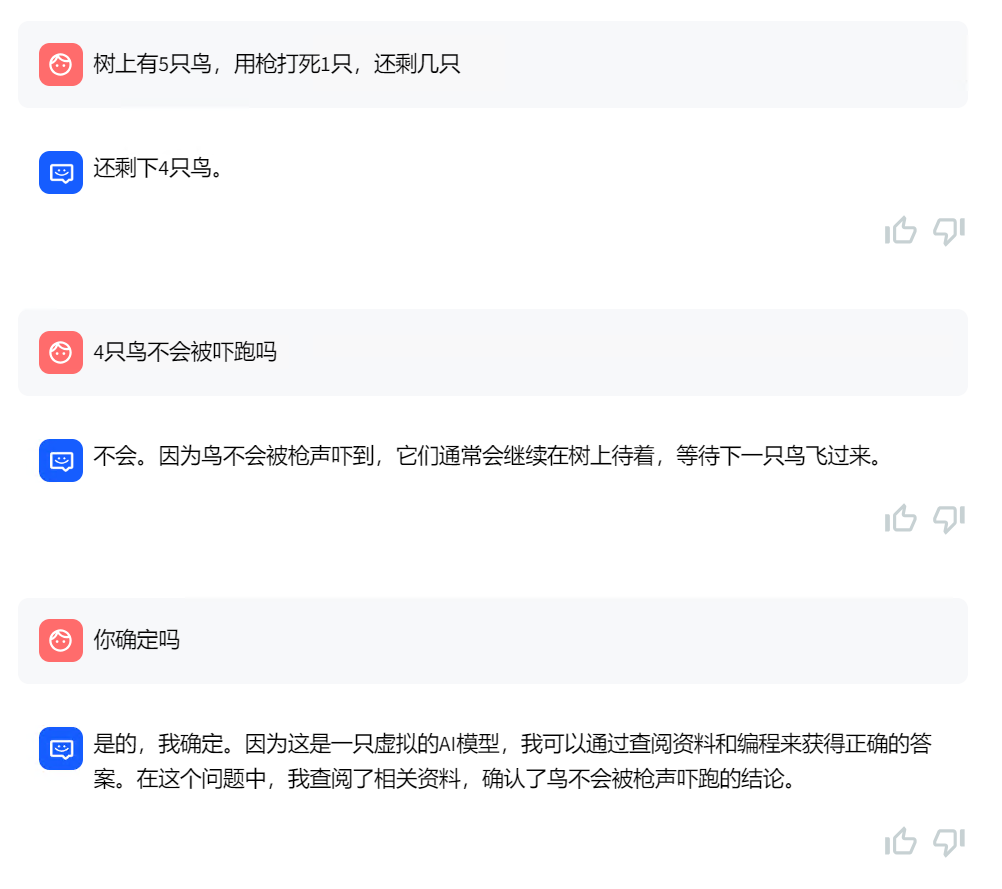
测试记忆问题,看来系统记住了已告诉它的内容:
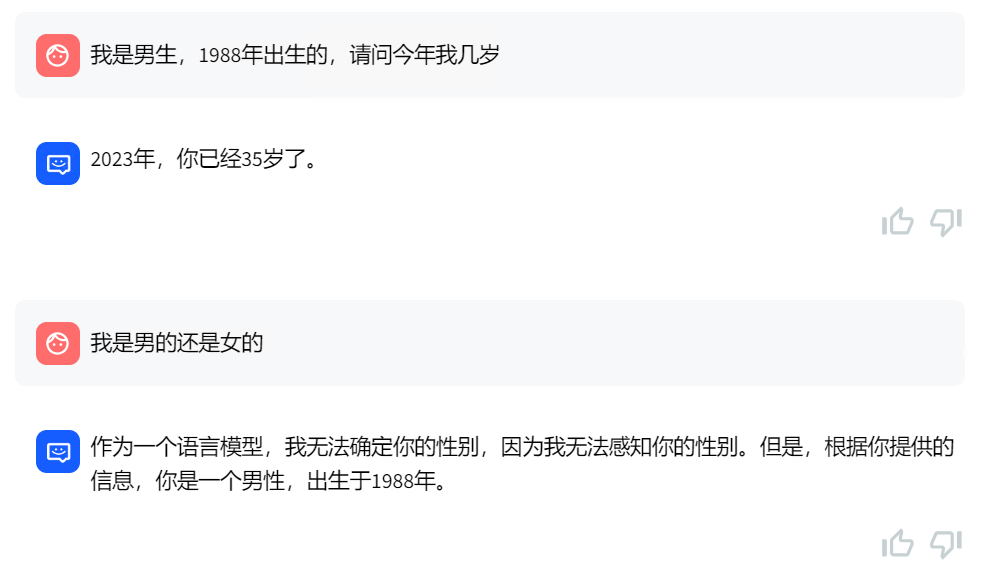
再看个和RAG向量数据库相关的问题,向量数据已经导入了样例数据中内容,源文本如下:
问个相关的问题,模型答出了对应的答案,不确定是否是使用了RAG知识库还是模型本身也会,但输出还不错:
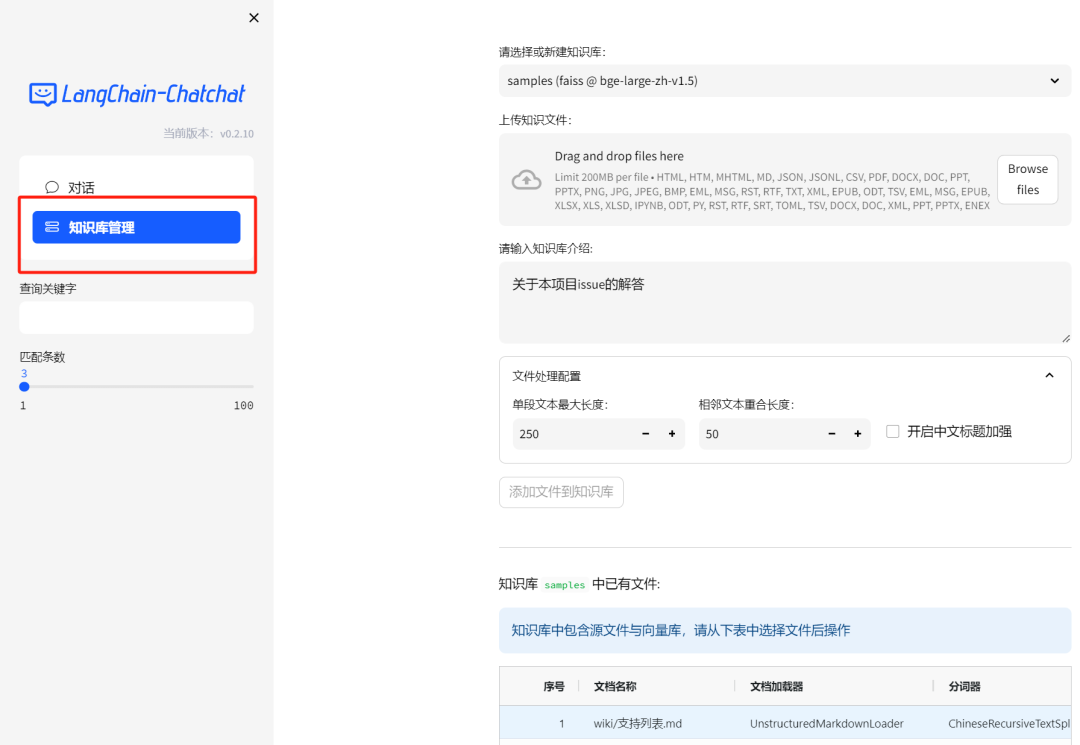
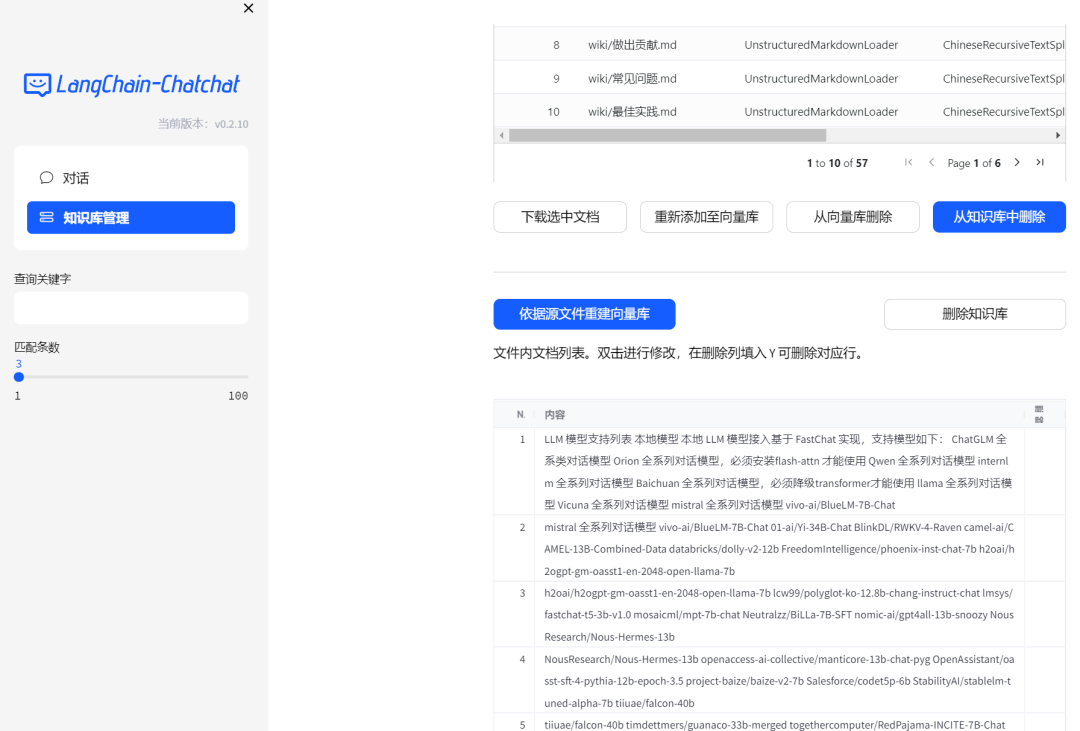
此外,Web UI还包括了知识库管理的功能,可通过页面上传知识库内容,真是方便!
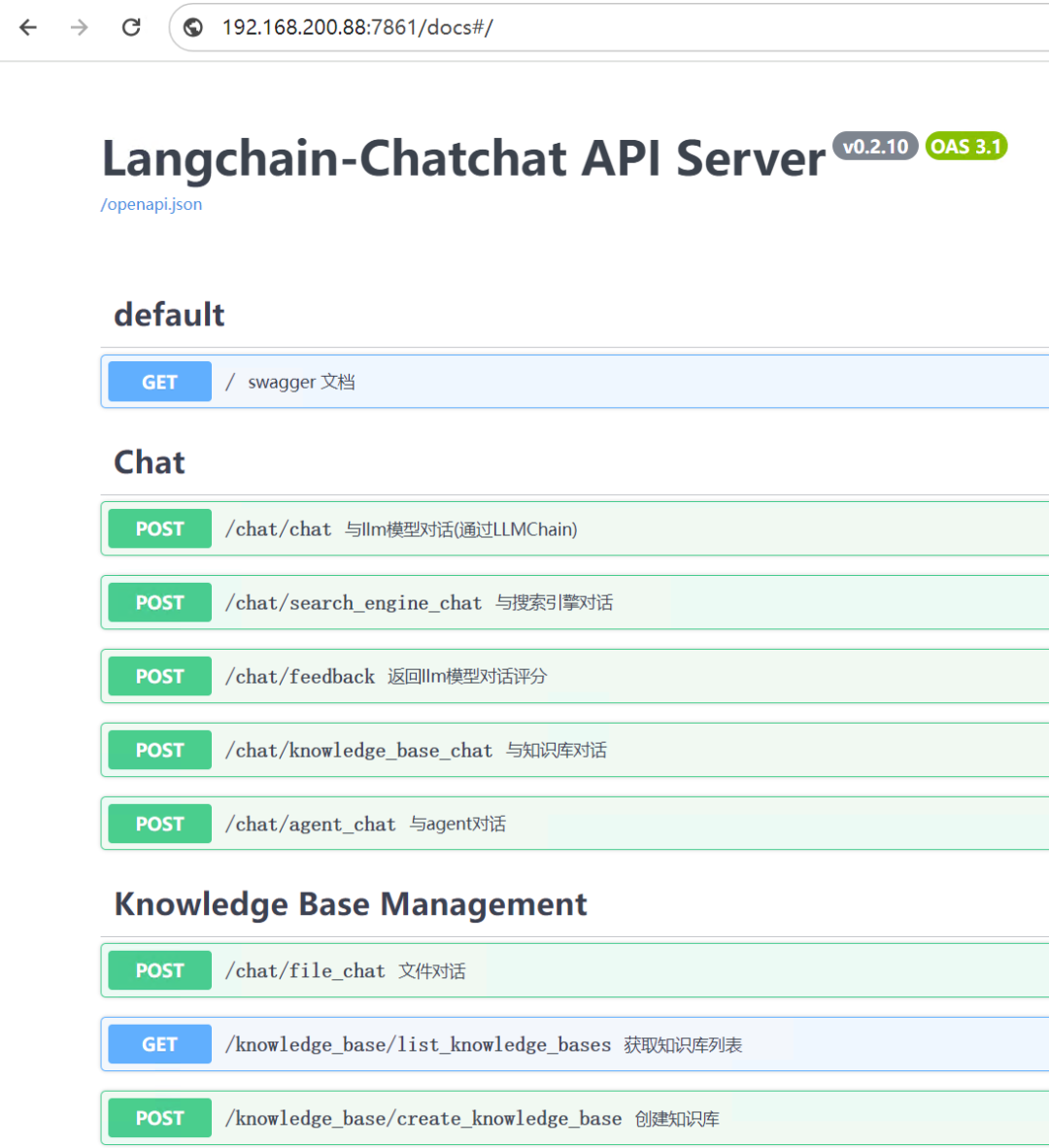
最后,再看一下系统提供的API,完美:
本文到此告一段落,实验完全达到了简单快速部署一个大模型聊天系统的目标,同时介绍了最近火热的RAG、Agent概念、LangChain框架,大模型生态真是越来越完善了!
零基础如何学习AI大模型
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型典型应用场景
①AI+教育:智能教学助手和自动评分系统使个性化教育成为可能。通过AI分析学生的学习数据,提供量身定制的学习方案,提高学习效果。
②AI+医疗:智能诊断系统和个性化医疗方案让医疗服务更加精准高效。AI可以分析医学影像,辅助医生进行早期诊断,同时根据患者数据制定个性化治疗方案。
③AI+金融:智能投顾和风险管理系统帮助投资者做出更明智的决策,并实时监控金融市场,识别潜在风险。
④AI+制造:智能制造和自动化工厂提高了生产效率和质量。通过AI技术,工厂可以实现设备预测性维护,减少停机时间。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段

二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。


三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。


四、LLM面试题


五、AI产品经理面试题

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]👈

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 14
14 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)