人工智能基础概念---词元(token)
词元(Token)是自然语言处理(NLP)中的一个基础概念,是将文本数据分割成更小的单位,这些单位可能是单词、字符、或者子词。词元是语言模型,如 GPT(Generative Pre-trained Transformer)等在训练和推理过程中操作的最基本单位。词元可以被视为语言的最小信息单位。单词词元化:在许多早期的 NLP 模型中,词元被定义为一个完整的单词。例如,句子“我喜欢人工智能”会被分
前言
文本数据在其本质上是非结构化的,这意味着计算机无法像处理数值数据那样直接处理文本。因此,如何将自然语言转化为计算机可以理解和处理的格式,是自然语言处理中的重要课题之一。而词元化(Tokenization)正是实现这一目标的主要手段之一。
在机器学习领域,NLP、文生图、图像识别与处理等领域,机器无法直接读取词汇、语句、图像、声音等等,而是通过 Token 来进行的。
词元的定义
词元(Token)是自然语言处理(NLP)中的一个基础概念,是将文本数据分割成更小的单位,这些单位可能是单词、字符、或者子词。词元是语言模型,如 GPT(Generative Pre-trained Transformer)等在训练和推理过程中操作的最基本单位。
词元可以被视为语言的最小信息单位。在不同的应用场景下,词元的定义可能有所不同:
- 单词词元化:在许多早期的 NLP 模型中,词元被定义为一个完整的单词。例如,句子“我喜欢人工智能”会被分成三个词元:“我”,“喜欢”,“人工智能”。这种词元化方法相对简单,且直观,因为一个单词通常对应一个特定的意义。
- 字符词元化:有些任务中,词元被定义为单个字符。例如,句子“GPT”会被分成“G”,“P”,“T”三个字符词元。字符级别的词元化能捕捉到一些细粒度的语言特征,尤其适合处理拼写错误或一些低频词汇的场景。
- 子词词元化:现代 NLP 模型,特别是像 GPT 这样的大型语言模型,通常使用子词词元化方法。子词词元化的基本思想是将文本拆解为比单词更小的单元,但保留了比字符更有意义的语言特性。比如,英语单词“playing”可能会被分成两个子词词元:“play”和“-ing”。这种方法既能捕捉到单词的语义信息,又能处理低频或罕见的单词,极大地提高了模型的泛化能力。
词元的转化
在提示词文本发送给神经网络之前,Tokenizer 将组合词、句子、段落、文章这类型的长文本分解为最小单位的 Token 词元,然后再通过 Embedding (神经网络算法——Embedding(嵌入))的方式把 token 转化为向量表示的数据结构,最后输入给神经网络。
比如下图中这句话“This is a input text.” 首先被 Tokenizer 转化成最小词元,其中[CLS][SEP]为一句话的起始与结束符号(CLS:classification 告知系统这是句子级别的分类的开始、SEP:separator 告知系统结束本句或分割下一句),然后再通过 Embedding 的方式转化为向量。
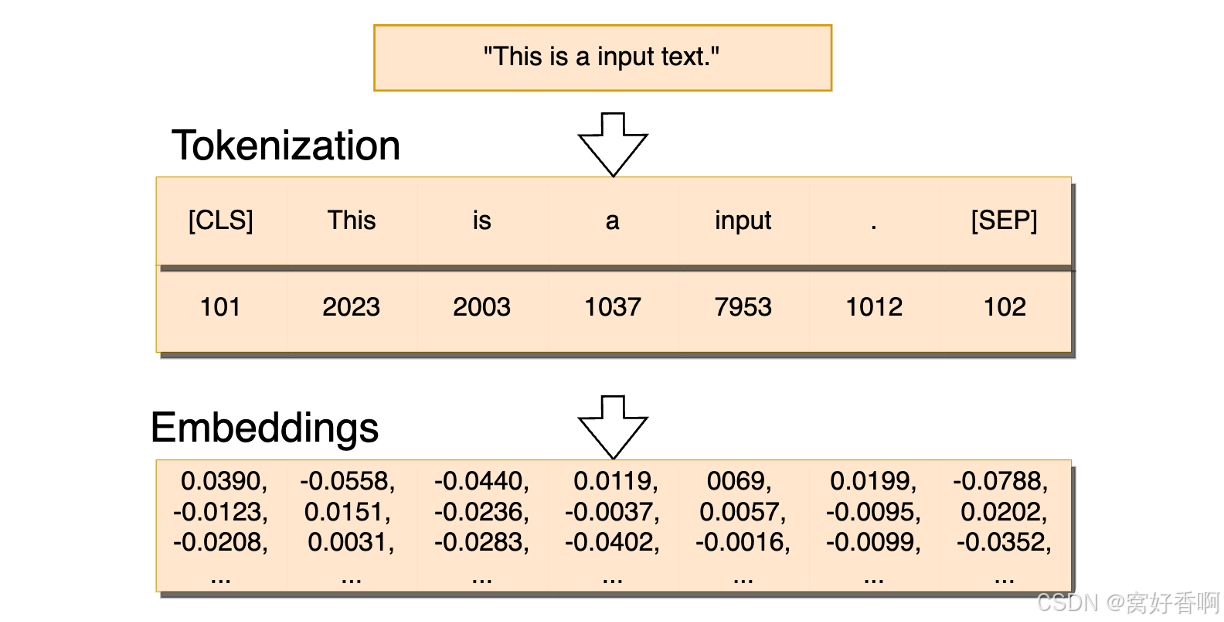
大模型竞争领域的三大法宝:word embedding向量集,算力资源,模型网络设计

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)