
使用 LangChain 代理创建多模式聊天机器人的开发人员指南
使用_@tool_装饰器是在 LangChain 框架中定义自定义工具的最简单方法。装饰器默认使用函数名称作为工具名称,可以通过传递字符串作为第一个参数来覆盖该名称。此外,装饰器使用函数的文档字符串作为工具的描述,因此必须提供文档字符串。您还可以通过将工具名称和 JSON 参数传递到工具装饰器中来自定义它们(请参阅下面的第二个工具 get_countries_by_name)。代理将工具描述作为上

在生成式人工智能领域,代理已成为创新的关键要素。它们使大型语言模型 (LLM) 能够更好地推理并执行复杂的任务,例如与外部数据源交互。这包括执行 Google 搜索、调用外部 API 或生成个性化图像。在我之前的帖子中,我解释了如何使用 OpenAI 的 GPT 创建个性化的 GPT 模型,该模型能够生成图像和文本。这篇文章向您展示了如何开发这种类型的解决方案,让您完全控制您选择的 LLM。您可以处理您的专有数据、对外部 API 的调用等。我创建了一个多模式聊天机器人,它利用 LangChain、ChatGPT、DALL·E 3 和 Streamlit 框架作为其用户界面。最后,我还将分享我创建的开源存储库,让您可以自行探索和部署聊天机器人。
生活在现实世界的挑战
问题涉及从现实世界中检索大型语言模型 (LLM) 训练范围之外的信息。这可以是执行对专有 API 的调用,也可以是向 LLM 提供尚未训练的数据(例如文件或图像),然后基于这些数据促进讨论。我们预计代理可以将任务分解为更小、更易于管理的任务,确定适当的工具及其使用顺序。
代理商在应对这一挑战中的作用
Agent 具备各种功能,包括调用外部 API、执行 Google 搜索或根据特定指令生成图像。这些功能直接解决了我们面临的挑战,提供了全面的解决方案。不过,在寻找解决方案之前,首先了解 LangChain 框架中 Agent 的功能至关重要。
如图所示,该过程在后台展开:当收到用户的任务或查询时,代理会调用 LLM 进行推理,本质上将任务分解为较小的中间步骤。此后,代理会激活适当的工具,将其输出转发给 LLM 进行进一步分析。这个推理周期一直持续到问题完全解决并向用户提供解决方案为止。
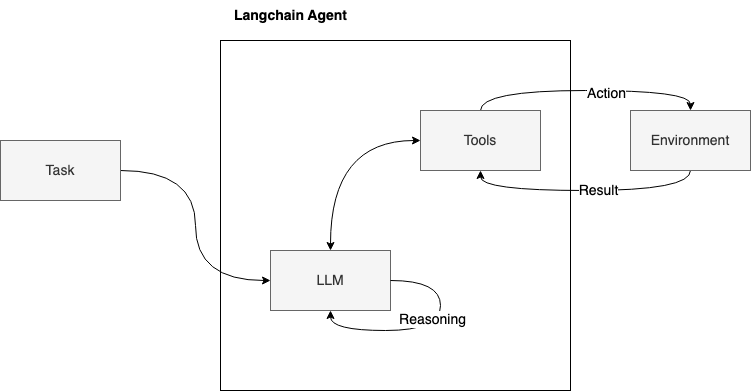
三种主要工具如何提供可能的解决方案
我制作的多模式聊天机器人由使用三种工具的代理支持:
-
REST 国家 API 链:可以检索有关国家的信息,调用此公共 API
-
DALL·E 3 图片生成器:根据国家名称生成国家图片
-
Google 搜索工具:用于从网络获取信息
我用 Python 开发了整个聊天机器人;以下是代理创建的代码片段:
def create\_agent():
tools = \[countries\_image\_generator,get\_countries\_by\_name,google\_search\]
functions = \[convert\_to\_openai\_function(f)for f in tools\]
model = ChatOpenAI(model\_name = “gpt-3.5-turbo-0125”)。bind(functions = functions)
prompt = ChatPromptTemplate.from\_messages(\[(“system”,“你是个乐于助人但又无礼的助手”),
MessagesPlaceholder(variable\_name = “chat\_history”),(“user”,“{input}”),
MessagesPlaceholder(variable\_name = “agent\_scratchpad”)\])
memory = ConversationBufferWindowMemory(return\_messages = True,memory\_key = “chat\_history”,k = 5)
chain = RunnablePassthrough.assign(agent\_scratchpad = lambda x:format\_to\_openai\_functions(x \[ “intermediate\_steps” \])
)| 提示 | 模型 | OpenAIFunctionsAgentOutputParser()
agent\_executor = AgentExecutor(agent=chain,tools=tools,memory=memory,verbose= True)
返回agent\_executor
LangChain 框架为代理提供了全面的解决方案,无缝集成了各种组件,例如提示模板、内存管理、LLM、输出解析以及代理执行器中这些元素的编排。
create_agent() 函数是此方法的核心,旨在实例化和配置具有特定功能的 ChatGPT 代理,集成外部工具和自定义处理管道以处理用户输入并生成响应。
以下是其组成部分的分解:
-
工具集成:定义一系列工具,包括_countries_image_generator_、get_countries_by_name_和_google_search。然后将这些工具转换为 OpenAI 函数,允许在 ChatGPT 的处理管道中调用它们。
-
模型配置:该函数设置了一个 ChatGPT 模型,具体来说是“gpt-3.5-turbo-0125”。通过将该模型与之前转换的 OpenAI 函数绑定,该模型得到了增强,使模型能够在运行过程中利用这些外部工具。
-
提示模板:使用一系列预定义消息创建 ChatPromptTemplate ,包括系统定义的角色和动态内容(例如用户输入_)的占位符,以及中间步骤的暂存器。此模板指导对话流程和结构。_
-
内存管理:使用_ConversationBufferWindowMemory_管理对话历史记录,存储最后 5 条消息(由参数 k 控制)以供参考。此内存由“chat_history”索引,并配置为返回用于生成响应的消息。
-
处理管道:定义一个处理链,该链从_RunnablePassthrough_开始处理中间步骤,然后将上下文传递到准备好的提示模板、ChatGPT 模型本身,最后传递到 OpenAIFunctionsAgentOutputParser _。_该管道通过代理协调数据流,将模型的输出与函数调用集成并解析结果。它使用LangChain 表达语言(LCEL),这是一种轻松组合链的声明式方法。
-
代理执行器:该函数的核心创建一个 AgentExecutor,它封装了整个代理及其工具、内存管理和定义的处理管道。此执行器运行代理、处理输入并根据配置生成输出。
在 LangChain 中创建自定义工具
使用_@tool_装饰器是在 LangChain 框架中定义自定义工具的最简单方法。装饰器默认使用函数名称作为工具名称,可以通过传递字符串作为第一个参数来覆盖该名称。此外,装饰器使用函数的文档字符串作为工具的描述,因此必须提供文档字符串。
您还可以通过将工具名称和 JSON 参数传递到工具装饰器中来自定义它们(请参阅下面的第二个工具 get_countries_by_name)。
代理将工具描述作为上下文添加到LLM中,以决定使用哪个工具。选择合适的描述至关重要。
让我分享一下我对每个工具的见解:
1)国家图片生成器工具
@tool
def countries\_image\_generator ( country: str ):
"""调用此函数获取某个国家/地区的图像"""
res = DallEAPIWrapper(model= "dall-e-3" ).run(
f"您生成一个代表最典型国家/地区特征的国家/地区图像,并结合其国旗。该国家/地区为{country} "
)
answer\_to\_agent = ( f"使用此格式 - 这是{country}的图像:\[ {country}图像\]"
f"url= {res} " )
return answer\_to\_agent
我使用 DallEAPIWrapper 调用 DALL·E 3 模型,并向其提供了关于我希望该国家/地区图像如何呈现的具体说明(例如,代表最典型的国家/地区特征、包含其国旗等)。但是,我添加了输出指令以响应代理,以使用国家/地区名称和生成的图像 URL 设置定义的格式。这对于识别代理的响应是图像而不仅仅是文本至关重要。
2)按名称获取国家/地区工具
def prepare\_and\_log\_request ( base\_url:str, params:Optional \[ dict \] = None ) -> PreparedRequest:
"""准备请求并记录完整的 URL。"""
req = PreparedRequest()
req.prepare\_url(base\_url,params)
print ( f'\\033\[92mCalling API:{req.url} \\033\[0m' )
return req
class Params ( BaseModel ):
fields:Optional \[conlist( str, min\_items= 1, max\_items= 27 )\] = Field(
default= None,
description= '用于过滤请求输出的字段。',
examples=\[ "name","topLevelDomain", " alpha2Code" , " alpha3Code" ,"currencies","capital","callingCodes","altSpellings","region","subregion" , "population" , "latlng" , "demonym" , "area" , "gini" , "timezones" , "borders" , "nativeName" , "numericCode" , "languages" , "flag" , "regionalBlocs" , "cioc" \]) class PathParams ( BaseModel ):name: str = Field(..., description= '国家名称' ) class RequestModel ( BaseModel ):params: Optional \[Params\] = None path\_params: PathParams @tool( args\_schema=RequestModel ) def get\_countries\_by\_name ( path\_params: PathParams, params: Optional \[Params\] = None ): """当您需要回答有关国家的问题时很有用。输入应该是一个完整的问题。""" BASE\_URL = f'https://restcountries.com/v3.1/name/ {path\_params.name} ' effective\_params = { "fields" : "," .join(params.fields)}
if params and params.fields else None
req = prepare\_and\_log\_request(BASE\_URL, effective\_params)
\# 发出请求
response = request.get(req.url)
\# 如果请求不成功则引发异常
response.raise\_for\_status()
return response.json()
浏览这个特定的工具带来了独特的挑战。第一步涉及设计一个 REST API 参数模型,该模型按名称获取国家/地区信息。为了实现这一点,我开发了一个封装路径和查询参数的 Pydantic 模型。随后,我将这个模型与 LangChain 工具装饰器集成在一起。
这种方法的价值在于它向大型语言模型 (LLM) 全面提交了参数模型,包括每个参数的详细描述。这不仅仅是对工具本身的简单概述。这种方法大大增强了 LLM 根据用户提示精确确定函数正确参数的能力,确保交互更加准确和高效。
3)Google 搜索工具
@tool
def google\_search ( query: str ):
"""使用提供的查询字符串执行 Google 搜索。需要查找当前数据时请选择此工具"""
return SerpAPIWrapper().run(query)
为了通过 API 在 Google 上进行搜索,我使用了内置的 SerpAPIWrapper。值得一提的是,其操作需要 API 密钥。在我的GitHub Readme上了解如何获取此密钥。
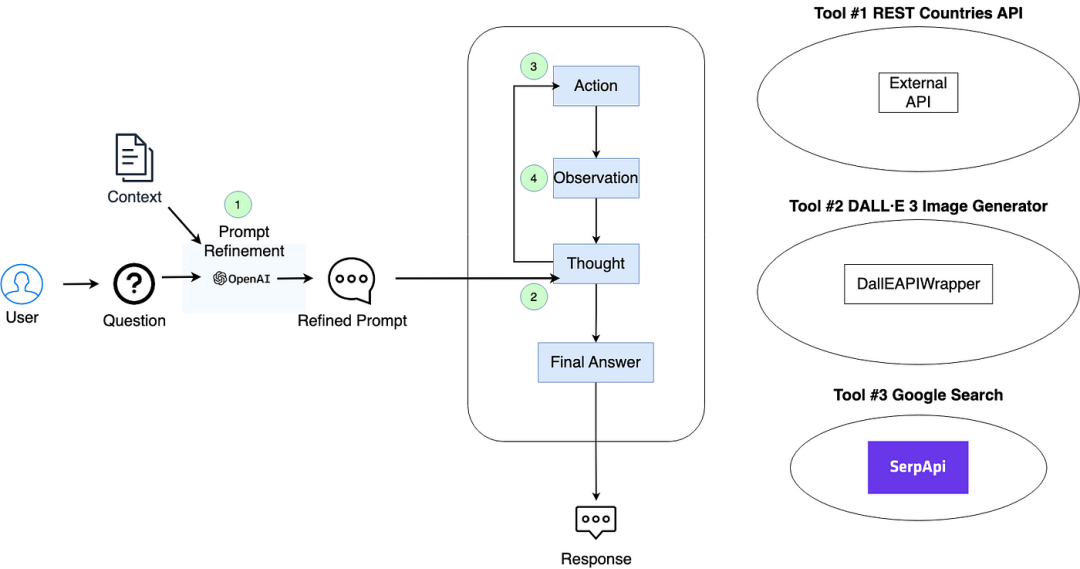
多模式聊天机器人架构
该图说明了多模式聊天机器人系统的结构:
-
提示细化。初始用户提示和对话历史记录的上下文被转发到 LLM(在本场景中为 ChatGPT),以将提示细化为更精确的查询。
-
思维过程。代理将经过提炼的提示以及任何可选工具传递给 LLM 进行推理。在此基础上,代理决定使用哪种工具。如果在此阶段确定了最终答案,则直接将其传达给用户。
-
工具调用。代理执行所选工具。
-
观察。工具生成的输出由代理发送回 LLM 进行进一步推理。
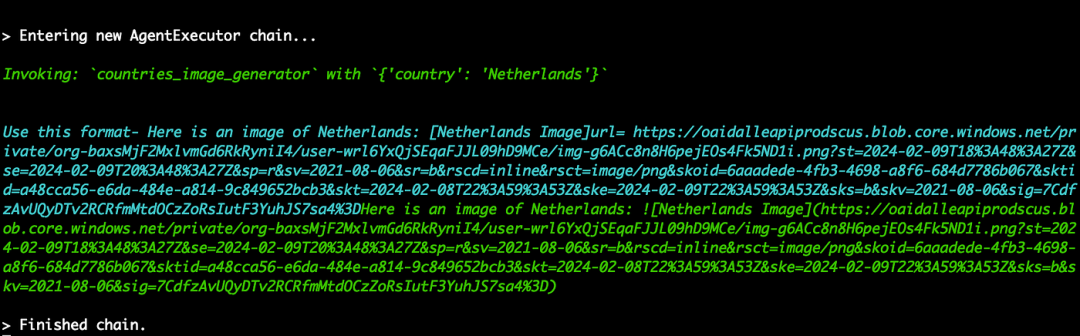
运行多模式聊天机器人
我问的第一个问题是创建荷兰的形象。

自行车漂浮在水面上的样子很有趣,对吧?我们还收到了一张荷兰的图片,捕捉了荷兰的精髓和国旗。
让我们来一睹幕后风采:
代理成功调用了“countries_image_generator”工具,输入了必要的参数:国家名称。接下来,我们以蓝色突出显示了函数的输出:“countries_image_generator”的返回值,显示了由 DALL·E 3 制作的图像的 URL。最后,我们以绿色看到了代理的决定性行动。
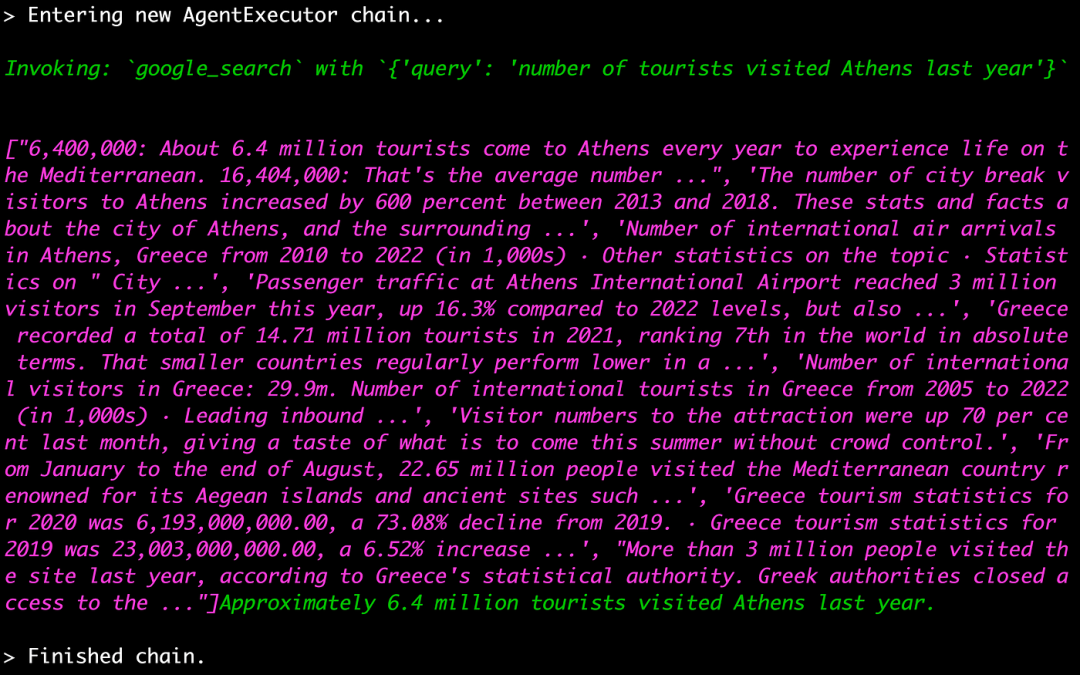
之后,我问:“去年有多少游客访问了雅典?”我得到的回答是,有 640 万游客访问了雅典。由于需要获取最新信息,因此使用了 Google 搜索工具。通过 Google 搜索“去年有多少游客访问了雅典”,我们得到了答案。

我又进行了更多询问:
-
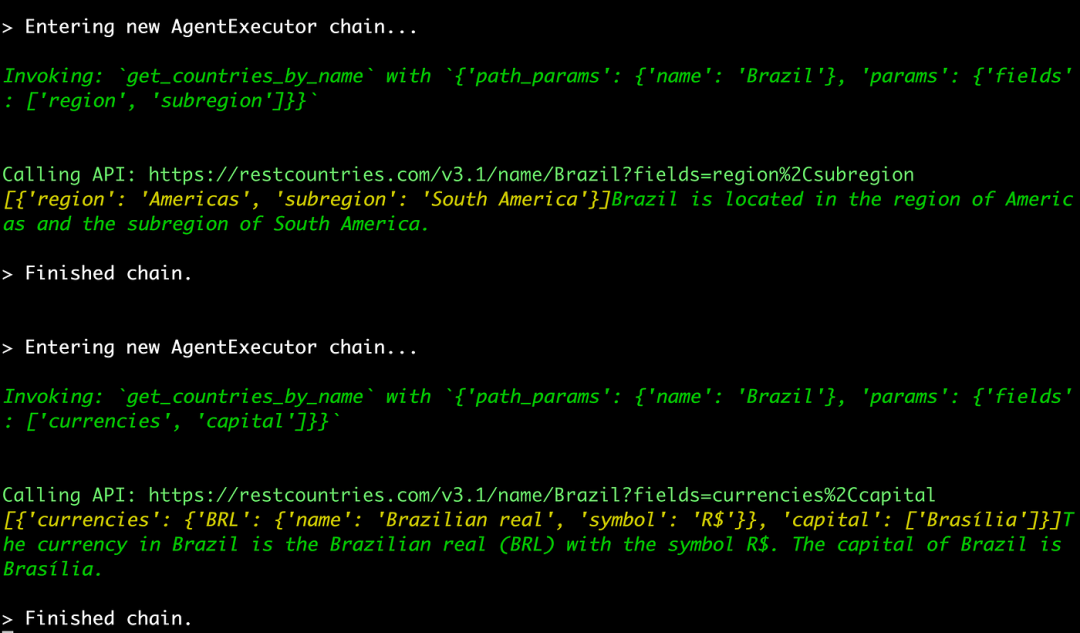
巴西的地区和子地区有哪些?
-
那里的货币和资本是什么?
对于这两个问题,我们采用了_get_countries_by_name工具并附带适当的参数。例如,对于第二个问题,我们通过使用__get_countries_by_name_工具激活该工具,参数为_{‘path_params’: {‘name’: ‘Brazil’}, ‘params’: {‘fields’: [‘currencies’, ‘capital’]}}_。
此外,这个多模式聊天机器人可以回忆以前的交互,这体现在它能够推断出有关货币和资本的后续问题的正确国家。
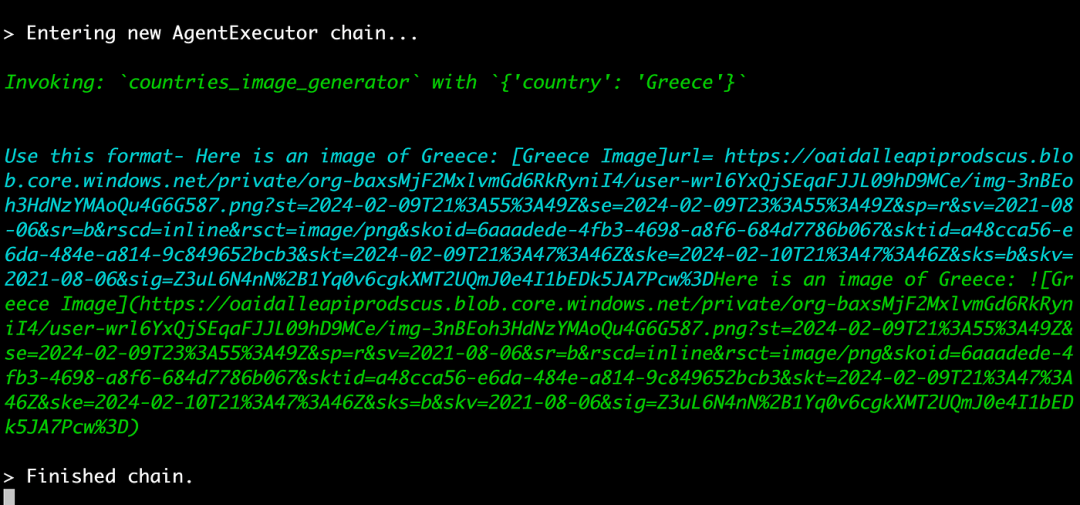
最后,我要求它创建一张希腊的图像:
利用代理解决实际问题
现在,您应该对代理在开发稳健应用程序中的关键作用有了更好的理解,特别是语言模型如何充当认知引擎。它智能地决定要执行的操作顺序,促进大型语言模型 (LLM) 与各种外部资源(包括 API、专有数据集和互联网搜索等其他潜在操作)的集成。我们还向您展示了 LangChain 框架在构建多功能聊天机器人方面的重要性。这个聊天机器人不仅能够调用外部 API 和浏览互联网,还可以创建图像,展示其多模式功能。
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 12
12 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

{kind=link}
所有评论(0)