昨天Google发布了最新的开源模型Gemma,今天我来体验一下
创业失败,又找不到工作,哎。。。看看以前写的文章,业余搞人工智能还是很早之前的事情了,之前为了高工资,一直想从事人工智能相关的工作都没有实现。现在终于可以安静地系统地学习一下了。也是一边学习一边写博客记录吧。昨天Google发布了最新的开源模型Gemma,今天我就来简单体验一下。
前言
看看以前写的文章,业余搞人工智能还是很早之前的事情了,之前为了高工资,一直想从事人工智能相关的工作都没有实现。现在终于可以安静地系统地学习一下了。也是一边学习一边写博客记录吧。
昨天Google发布了最新的开源模型Gemma,今天我就来简单体验一下
第一步 去Kaggle申请模型权限
https://www.kaggle.com/models/keras/gemma/
先用我的Google账户注册登陆一下Kaggle,然后在点击一下那个红框里面的按钮,填个申请表格,立马就可以了,下面是我申请后的样子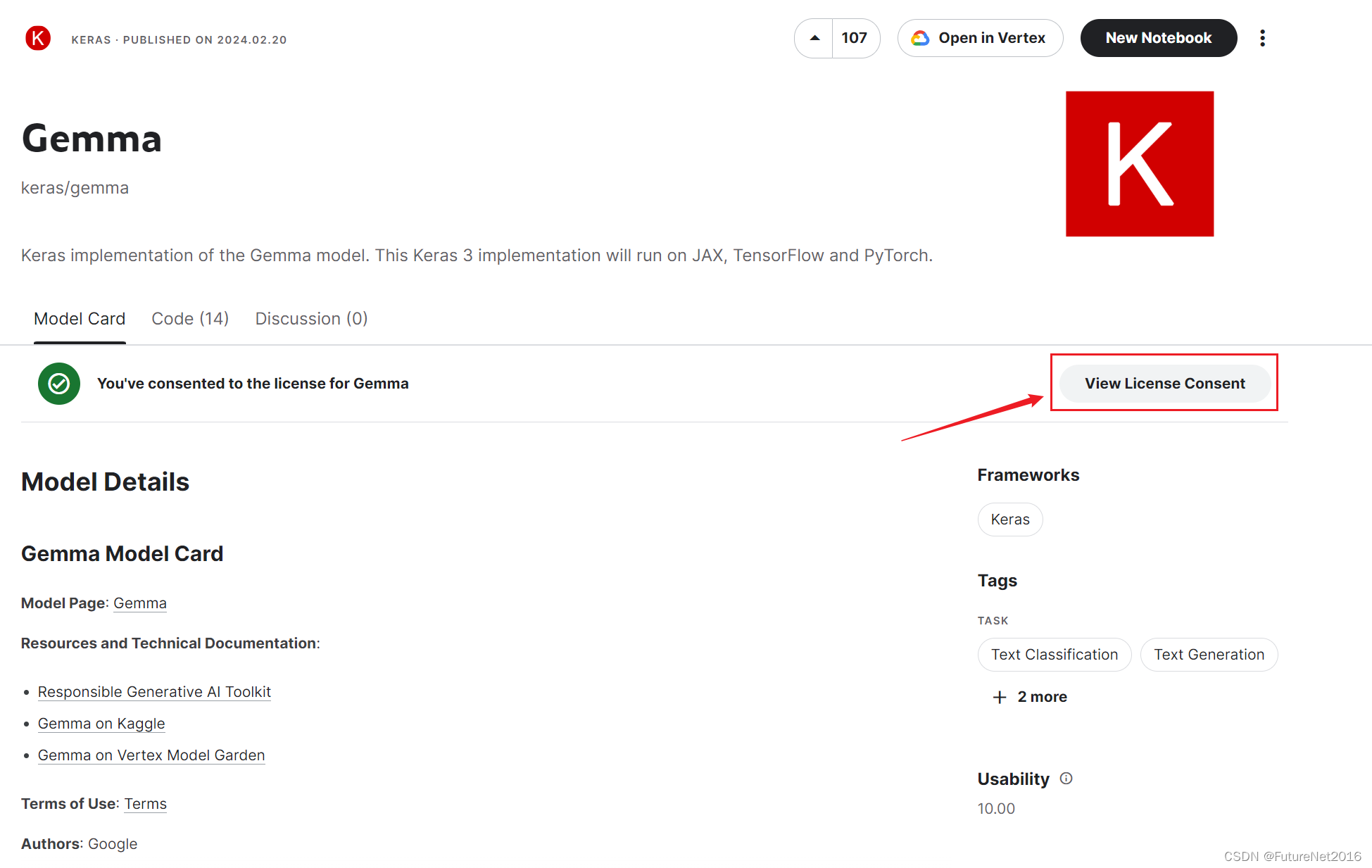
第二步 搞个Kaggle的API key 后面会用到
点击页面右上角的用户头像那里
选择Settings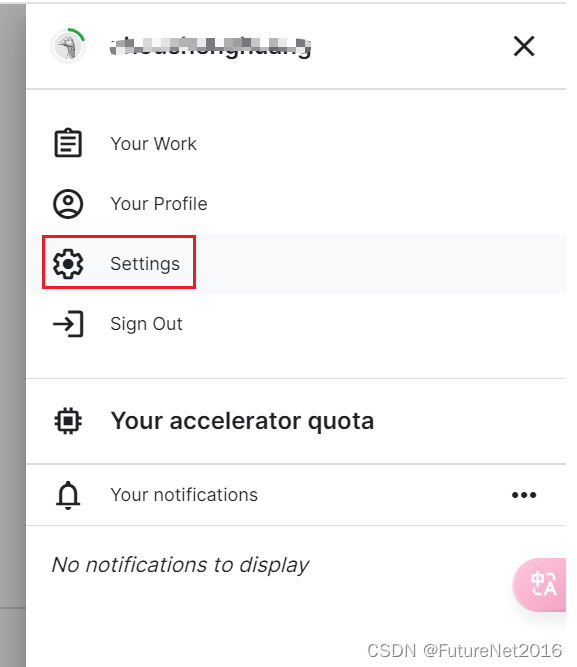
创建token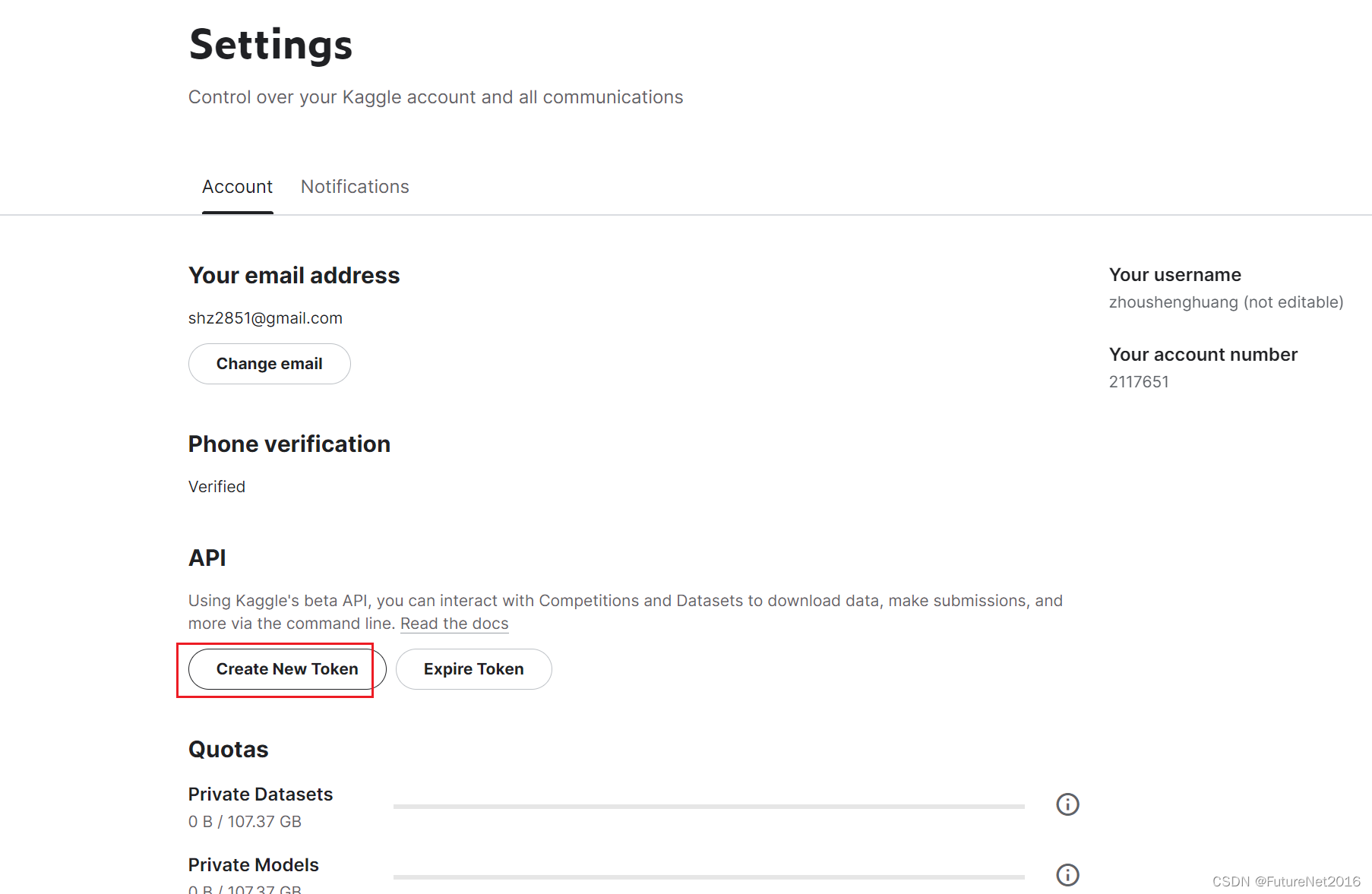
自动下载下来了
第三步,打开Google colab 运行模型
https://colab.research.google.com/
新建一个笔记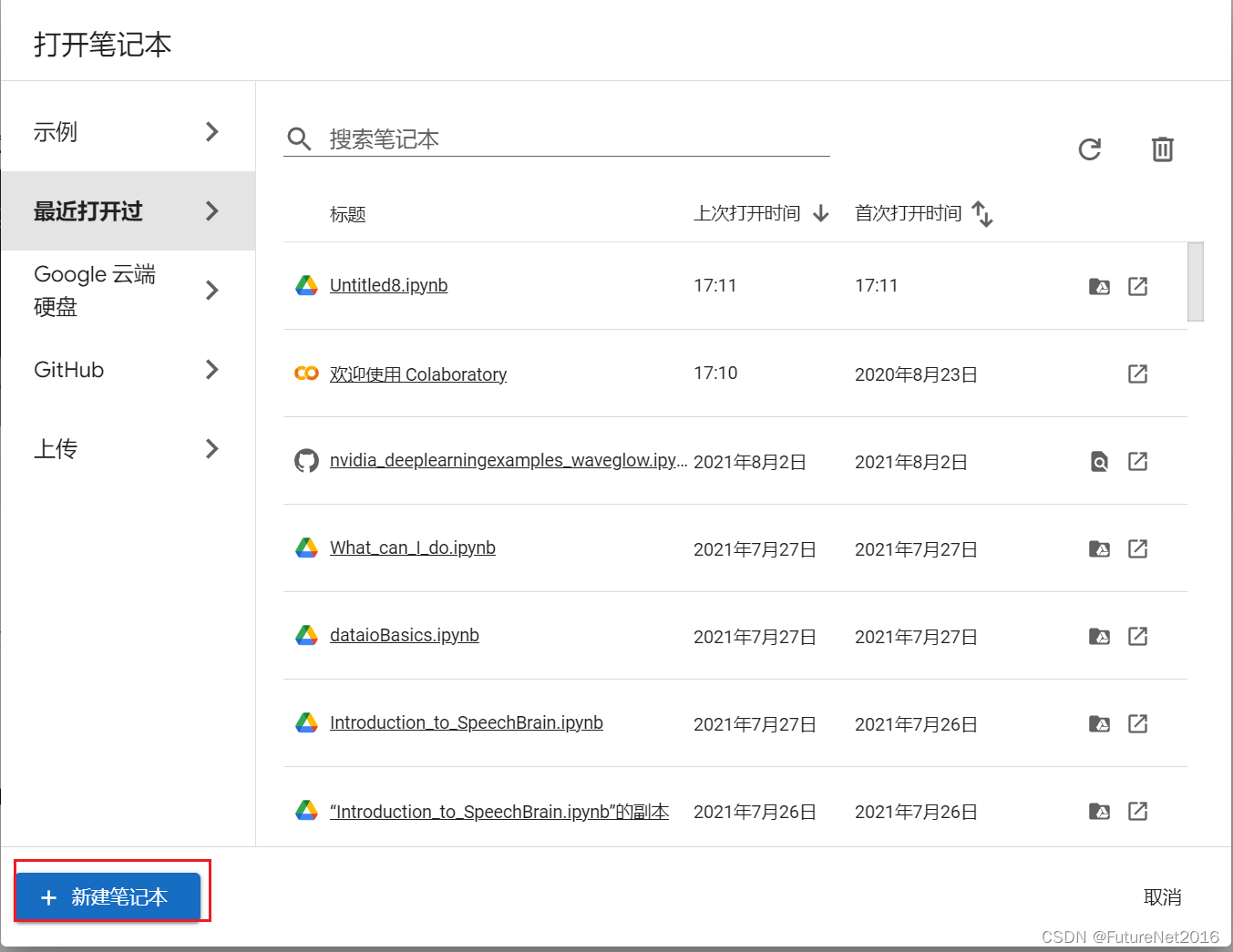
把刚才下载的Kaggle的apikey 填到colab中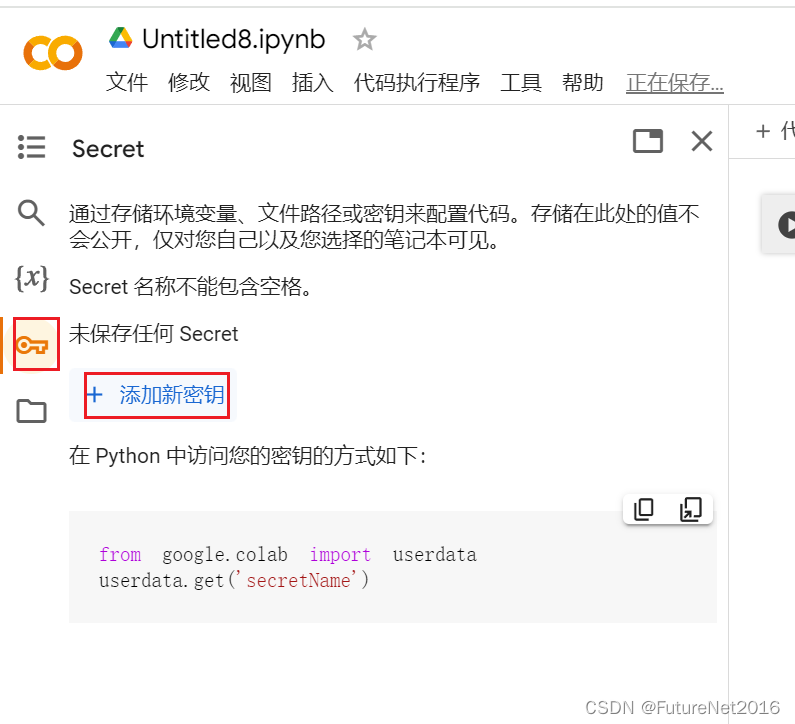
填好之后,把开关打开一下
设置两个:KAGGLE_USERNAME KAGGLE_KEY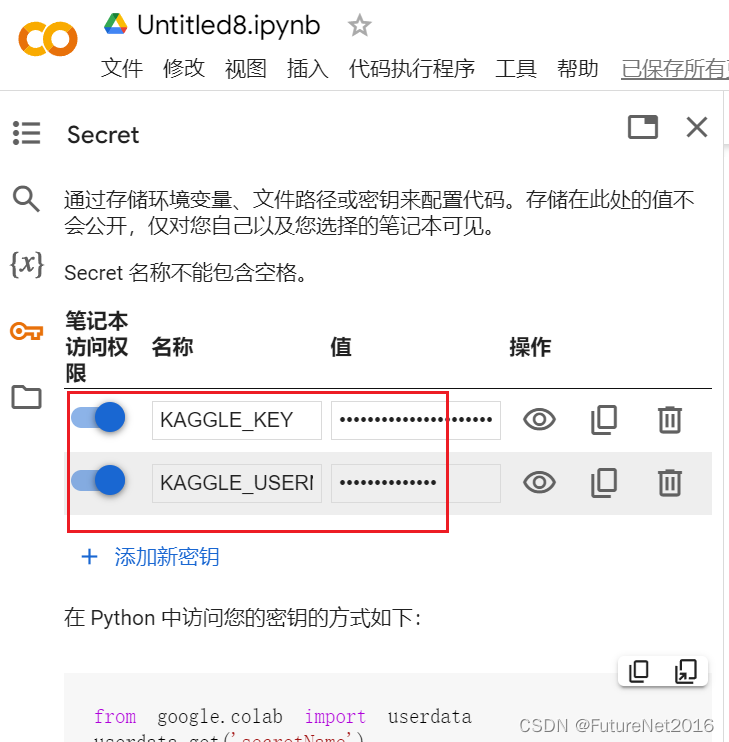
设置一下运行时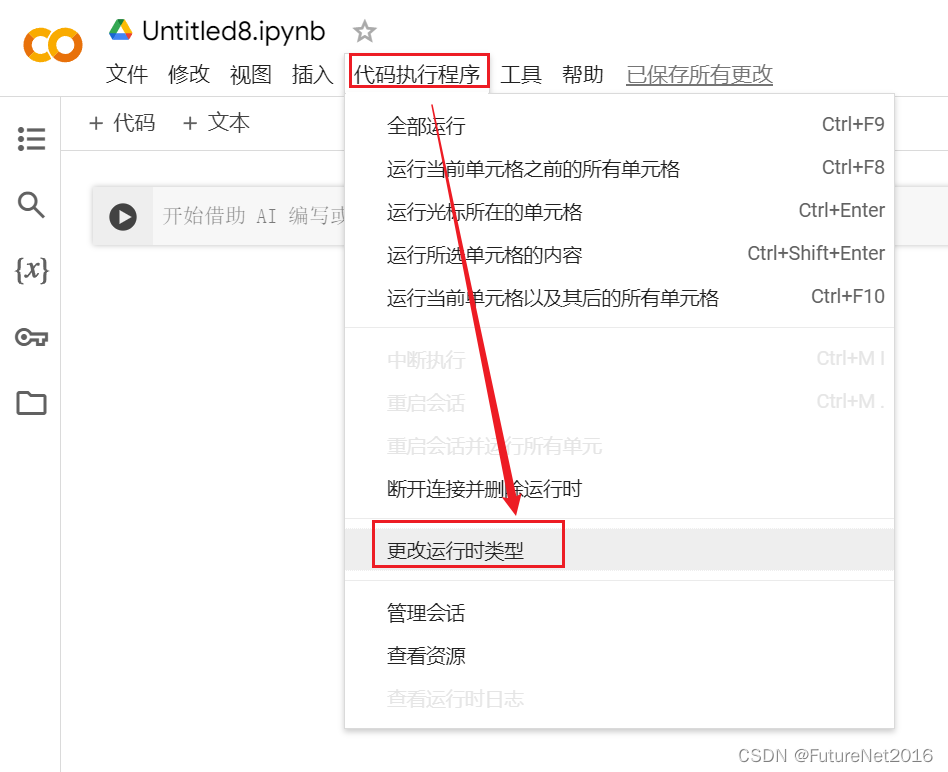
改为T4 GPU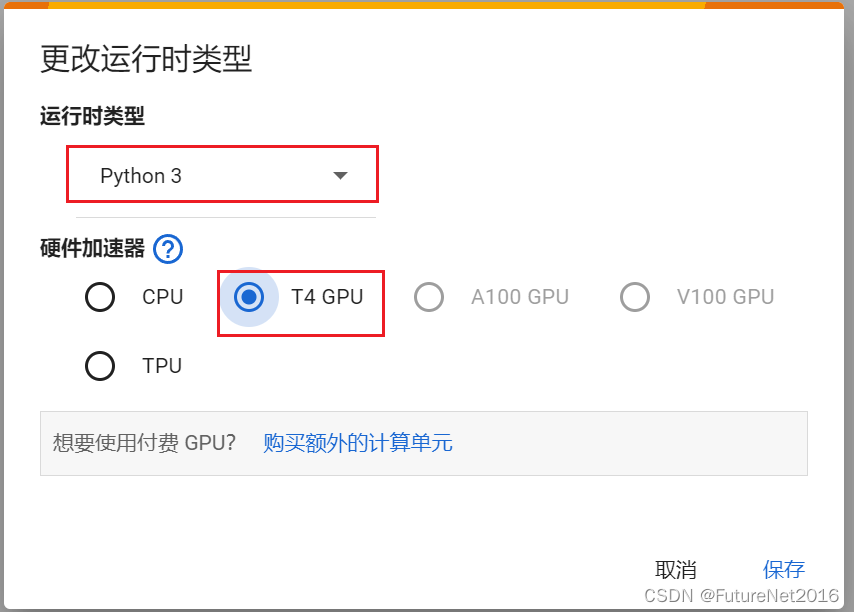
右上角连接资源后可以查看使用情况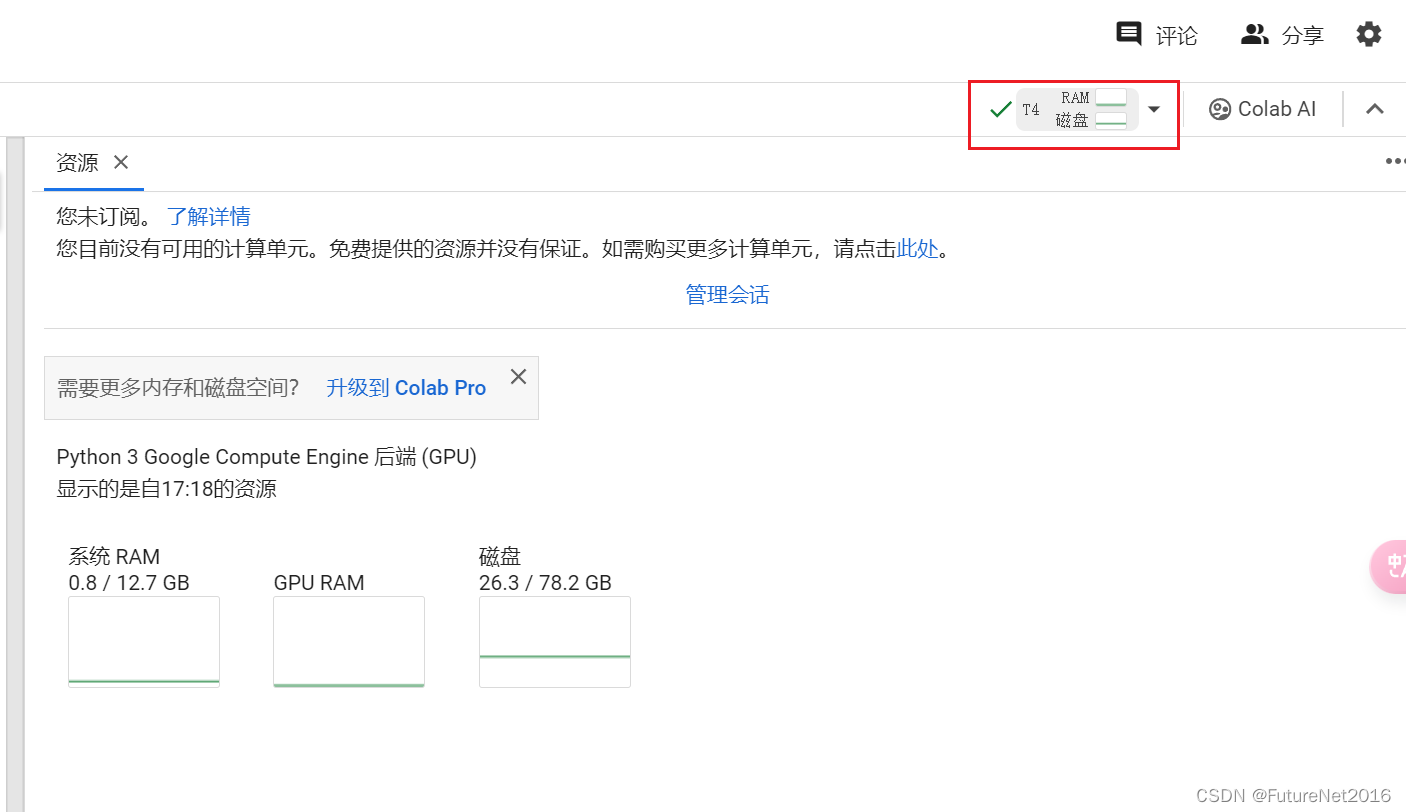
写代码:
# 先安装一下keras
!pip install -U keras-nlp
!pip install -U keras
# 引入包,验证一下keras版本,不能低于3.0
import keras
import keras_nlp
import numpy as np
print(keras.__version__)
#设置环境变量
import os
from google.colab import userdata
os.environ["KAGGLE_USERNAME"] = userdata.get('KAGGLE_USERNAME')
os.environ["KAGGLE_KEY"] = userdata.get('KAGGLE_KEY')
# 选择一个较小的模型试试
gemma_lm = keras_nlp.models.GemmaCausalLM.from_preset("gemma_instruct_2b_en")
# 文本补全任务调用generate函数
gemma_lm.generate("Keras is a", max_length=30)
# generate函数,也可也完成批量补全
gemma_lm.generate(["Keras is a", "The sky is blue because"], max_length=30)
执行结果: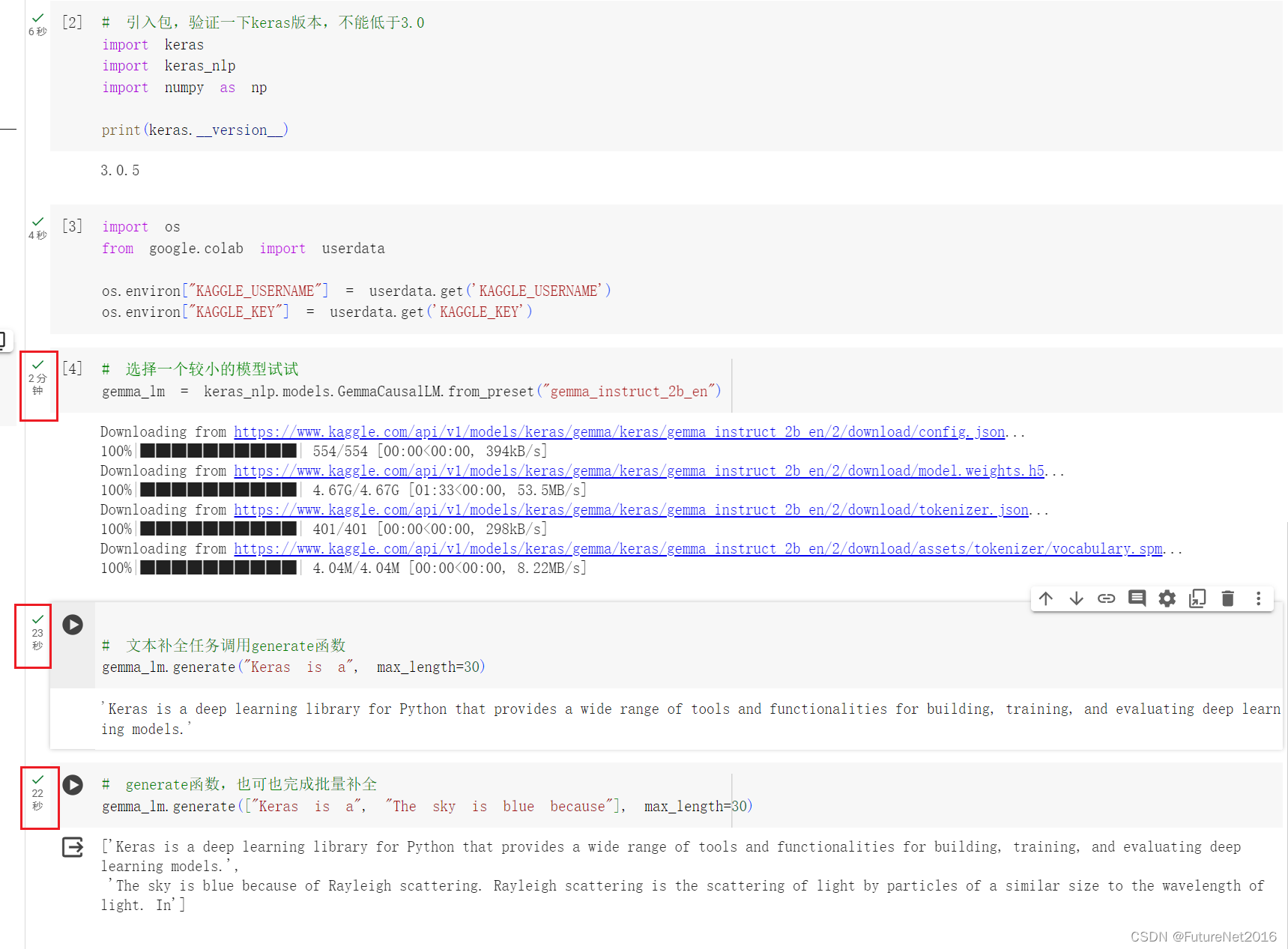
资源占用:
感觉好慢。。。
而且显存占用太多了。。。
结果
后面再写一篇本地部署运行的文章,看看效果怎么样
我的电脑配置:
CPU: 12th Gen Intel® Core™ i7-12700F 2.10 GHz
内存32G,显卡RTX3060 12G

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)