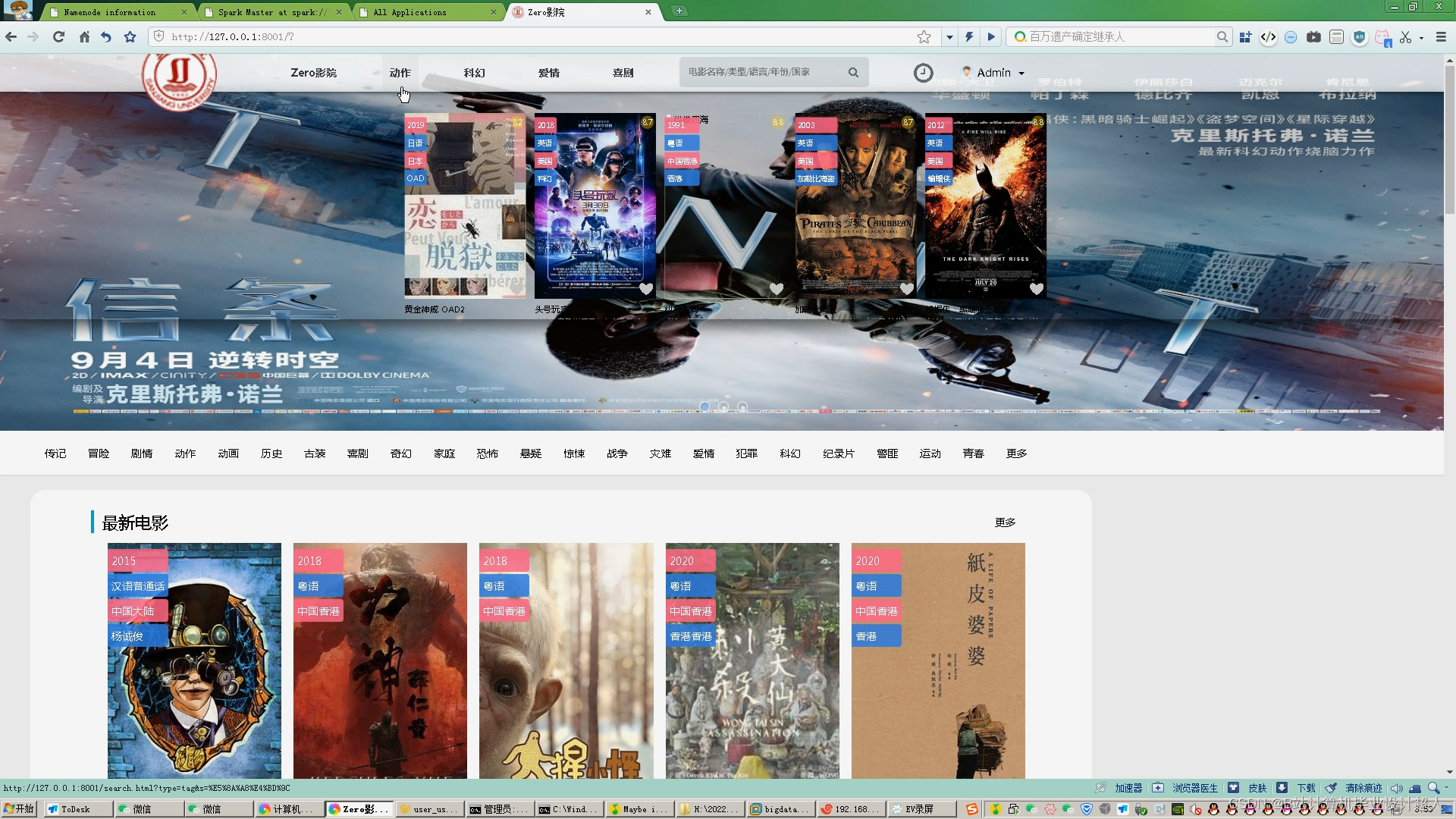
计算机毕业设计Hadoop+Spark电影推荐系统 电影用户画像系统 电影评论情感分析 电影爬虫 电影可视化 电影大数据 电影数据分析 大数据毕业设计 知识图谱 机器学习 深度学习 人工智能
计算机毕业设计Hadoop+Spark电影推荐系统 电影用户画像系统 电影评论情感分析 电影爬虫 电影可视化 电影大数据 电影数据分析 大数据毕业设计 知识图谱 机器学习 深度学习 人工智能
中国石油大学(北京)网络教育毕业设计(论文)管理规定
第一条 为切实保证学校网络教育毕业设计(论文)质量,制定本规定。
第二条 本规定适用于网络教育本科层次在籍学生。
第三条 毕业设计(论文)环节是远程教育本科学生必须完成的环节。
第四条 按照各专业培养方案已选课总学分80%以上,可选毕业论文课程,选课成功后方可进行论文写作。
第五条 学生在毕业论文选课后关注网络与继续教育学院学历教育官网首页公告、教学平台学生工作室和石大成教微信公众号上发布的相关信息,按照公布的论文进度安排完成毕业设计(论文)的各个环节。
第六条 学生严格按照学校毕业论文管理规定及写作模板撰写开题报告、论文、初稿、二稿和终稿,并以附件的形式上传到“学生工作室”—“毕业论文”栏目中。
第七条 在毕业设计(论文)写作过程中,在教学平台学生工作室与论文指导教师进行沟通,并严格按照教师给出的修改意见,认真完善论文的内容和格式。
第八条 符合答辩条件的学生按时在教学平台学生工作室申请答辩并告知学习中心老师,严格遵守答辩现场纪律,按照学院相关规定完成答辩。
第九条 毕业设计(论文)具体程序
(一) 时间安排
毕业设计(论文)写作每年安排2次:春季学期毕业(设计)论文写作时间为12月至次年5月;秋季学期毕业(设计)论文写作时间为6月至11月。
(二) 相关规定
在撰写毕业设计(论文)前,应认真阅读教学平台学生工作室中的“毕业论文”栏目中的“论文要求”,包括《毕业设计(论文)管理规定》、《毕业设计(论文)写作要求与格式规范》(英语专业学生阅读《英语专业论文写作要求与格式》);认真学习《毕业论文指导》视频、写作要求和规范。
(三) 论文选题
学生可以在论文指导教师给出的可供选择的题目范围内进行选题,题目确定后,学生开始撰写毕业设计(论文)开题报告。
(四) 开题报告
学生根据所确定的论文题目开始查阅资料、展开调研,完成《毕业设计(论文)开题报告》,并上传至教学平台学生工作室,由论文指导教师审核批阅。
(五) 论文初稿
学生参照指导教师对开题报告的批阅意见进一步收集资料,对资料进行加工整理,或进行相关试验和调查,以严肃认真、科学严谨的态度严格按照毕业设计(论文)的写作规范,独立撰写毕业设计(论文)初稿,提交到教学平台学生工作室后进行查重,由指导教师进行批阅。
(六) 论文二稿
学生参照指导教师对初稿的批阅意见,修改形成毕业设计(论文)二稿,提交到教学平台学生工作室后进行查重,由指导教师进行批阅。
(七) 论文终稿
学生参照指导教师对二稿的批阅意见,进行修改及完善后提交终稿并查重。终稿提交后,论文指导教师开始进行论文终稿的成绩评定工作。
(八) 毕业设计(论文)答辩
1.毕业设计(论文)答辩条件
毕业设计(论文)写作成绩良或优者,方可申请参加答辩,且仅有一次答辩机会。
2.毕业设计(论文)答辩要求
每学期,在毕业设计(论文)终稿评阅完毕后,安排毕业设计(论文)答辩工作(具体日期请注意教学平台上的通知)。
学生需要提前参加远程答辩系统的测试及相关培训,并提前准备好远程答辩需要具备的软硬件条件:电脑、耳麦及摄像头,保证网络畅通。
拟参加答辩的学生需提前制作答辩PPT。
答辩形式为远程答辩,具体要求请参考当期的论文答辩通知。
(九) 毕业设计(论文)最终成绩评定
毕业设计(论文)的写作成绩和答辩成绩按四个等级评定,包括:优秀(90~100分)、良好(89~80分)、及格(60~79分)、不及格(59分以下)。
未参加答辩的,毕业设计(论文)最终成绩以写作成绩为准;参加答辩的,毕业设计(论文)最终成绩以答辩成绩为准。
毕业设计(论文)成绩及格以上(含及格)者,可获得相应的学分。
成绩不及格者,无法获得毕业设计(论文)的学分,需要参加论文复核。由论文指导教师对复核论文进行指导、批阅并评定成绩,复核论文的最高成绩是及格。
(十) 成绩发布
每学期在毕业设计(论文)写作批阅完成后通过教学平台学生工作室公布成绩,学生可登录教学平台学生工作室查询。
(十一) 特别说明
1.凡申请学位的学生毕业设计(论文)答辩成绩必须达到良或优秀。
2.成绩为优秀的毕业设计(论文),学院将有权选取部分毕业设计(论文)全文汇编成集或者在网上公开发布。如因著作权发生纠纷,由学生本人负责。
3.毕业设计(论文)须独立完成。若有抄袭、雷同、代写等作弊行为,一经发现,其毕业设计(论文)成绩无效;已准予毕业者,收回毕业证书,取消毕业资格;已授予学位者,收回学位证书,取消学位资格。因作弊行为而成绩无效者,可以申请论文复核,论文复核最高按“及格”记载。
第十条 本规定自公布之日起实施。
第十一条 本规定由中国石油大学(北京)网络与继续教育学院负责解释。
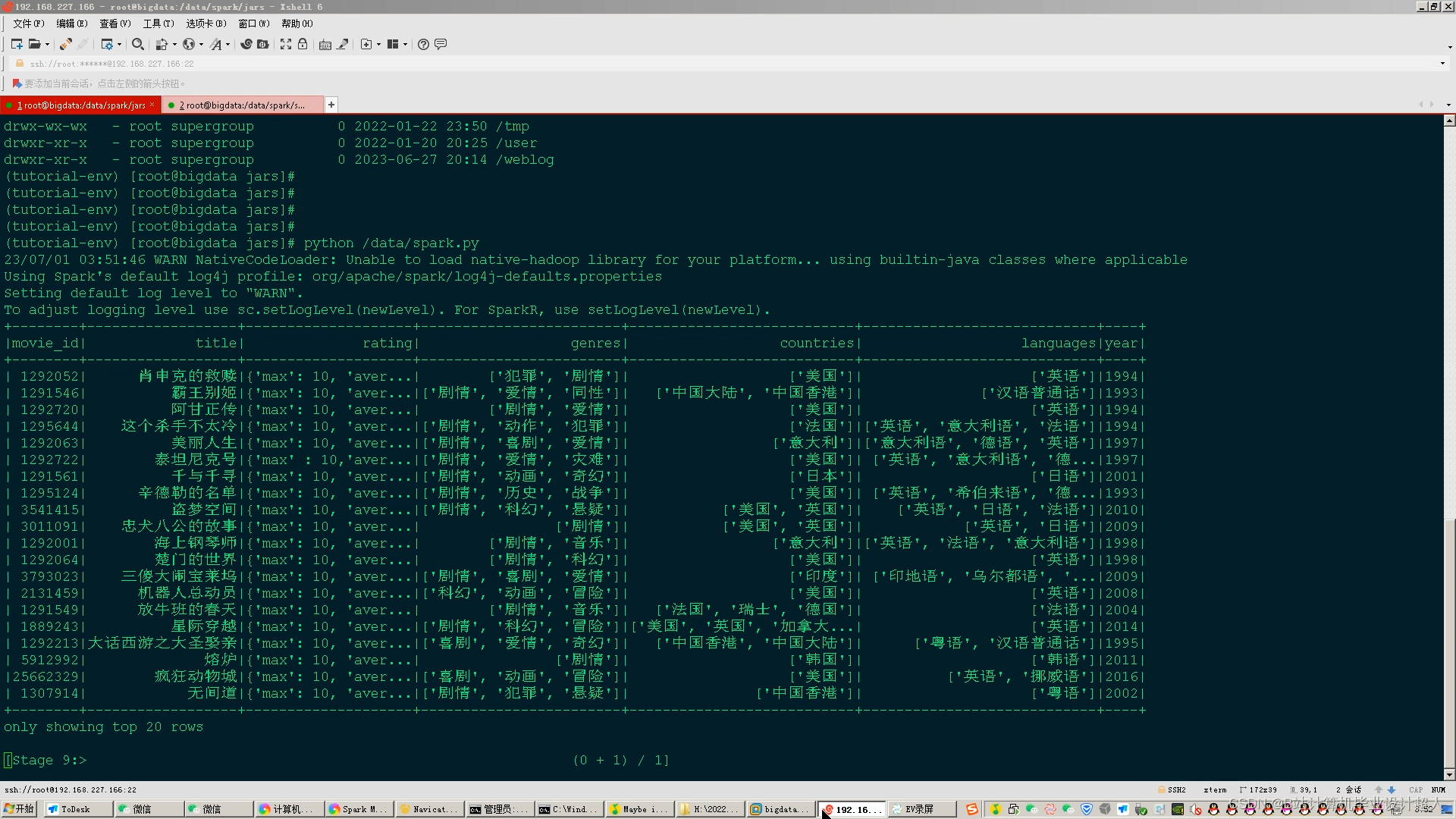
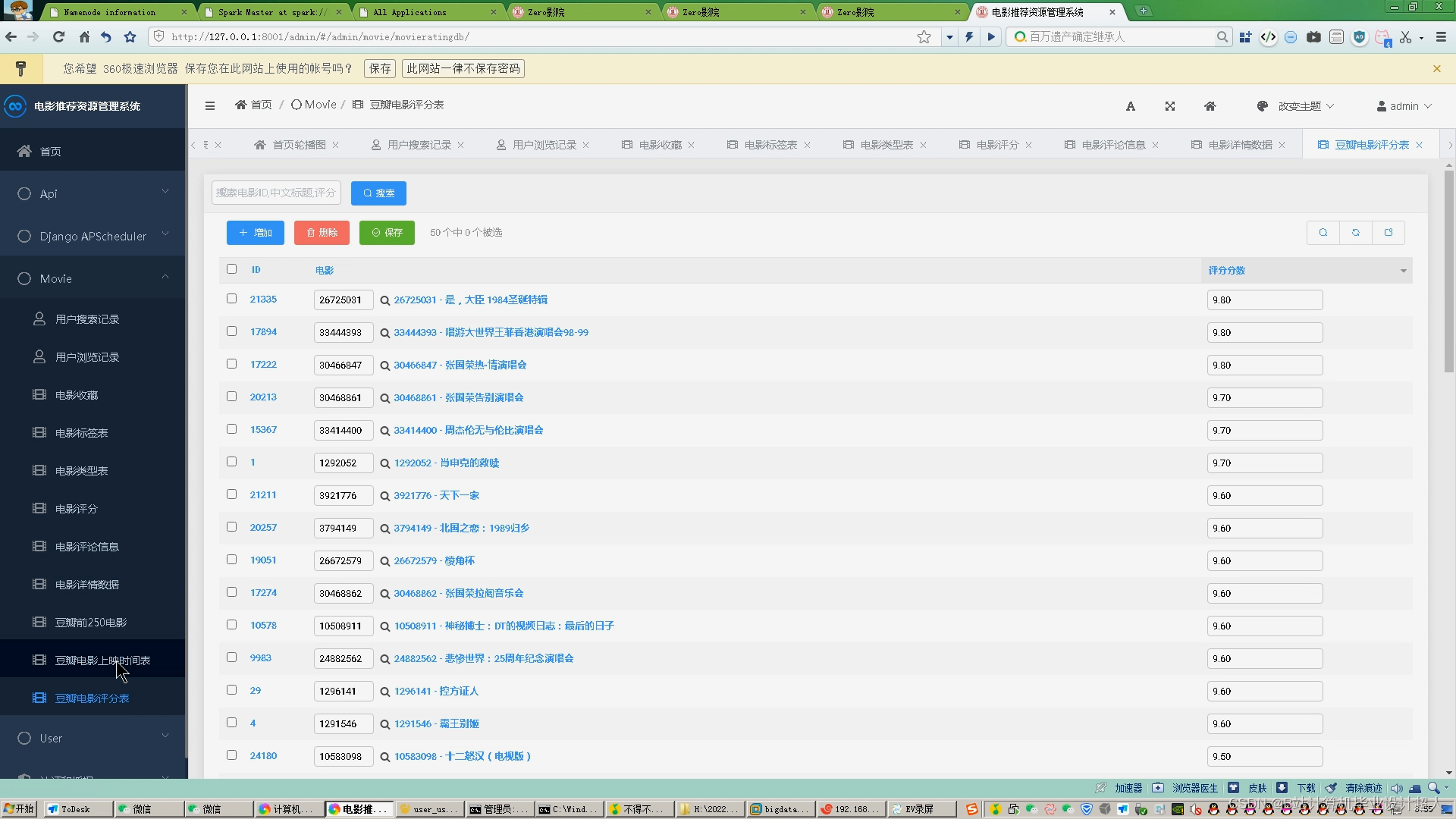
核心算法代码分享如下:
import ast
import collections
import datetime
import findspark
findspark.init()
import math
import numpy as np
import pandas as pd
from pyspark import Row, SparkContext, SparkConf
from pyspark.sql import SQLContext
from pyspark.sql.functions import col
# 该文件为系统的电影推荐的spark离线处理脚本
# 可放置linux下单独运行,只需在liunx下安装python3同时安装相应的库即可运行
# 当然也可放置在windows下运行,但环境配置较复杂容易出错,不建议
# 内部需要改动mysql数据库配置信息(35行)、spark信息(24行)、hadoop信息(39行)
# 注:该脚本做了数据量的限制,于 221行 可以取消数据量的限制
# 执行完成后会将数据更新到表“user_usermovierecommend”,同时在hadoop中路径movie_system会生成计算的相关相似度文件
class Calculator:
def __init__(self):
self.localClusterURL = "local[*]"
self.clusterMasterURL = "spark://192.168.227.166:7077"
self.conf = SparkConf().setAppName('Movie_System').setMaster(self.localClusterURL )
self.sc = SparkContext.getOrCreate(self.conf)
self.sqlContext = SQLContext(self.sc)
# spark 初始化
# self.sqlContext = SparkSession.Builder().appName('sql').master('spark://192.168.227.166:7077').getOrCreate()
# mysql 配置
self.prop = {'user': 'root',
'password': '123456',
'driver': 'com.mysql.jdbc.Driver'}
self.jdbcURL = "jdbc:mysql://localhost:3306/sql_bs" \
"?useUnicode=true&characterEncoding=utf-8&useSSL=false"
# user\rating\links\tags在hdfs中的位置 ===> 即推荐原料在hdfs中的存档路径
self.hdfs_data_path = 'hdfs://bigdata:9000/movie_system/'
self.date_time = datetime.datetime.now().strftime("%Y-%m-%d")
def __del__(self):
# 关闭spark会话
self.sc.stop()
del self.sc
def select(self, sql):
# 读取表
data = self.sqlContext.read.jdbc(url=self.jdbcURL, table=sql, properties=self.prop)
return data
# # 离线计算时从mysql加载movies数据到hive中
# movies_sql = self.sqlContext.read.format('jdbc') \
# .options(url=self.jdbcURL,
# driver=self.prop['dirver'],
# dbtable=self.movieTab,
# user=self.prop['user'],
# password=self.prop['password']).load()
def get_data(self, path):
data = self.sqlContext.read.parquet(path)
return data
# def show(self):
# sql = '(select user_id,tag_type,tag_weight,tag_name from user_usertag) aaa'
# data = self.select(sql)
# # 打印data数据类型 <class 'pyspark.sql.dataframe.DataFrame'>
# # print(type(data))
# # 展示数据
# data.show()
def write(self, data, path):
data.write.csv(path + "_csv", header=True, sep=",", mode='overwrite')
data.write.parquet(path, mode='overwrite')
def change_sql_data_to_hdfs(self, sql, path):
data = self.select(sql)
self.write(data, path)
# 根据电影类型、语言、国家、年份计算相似度
def calculator_movie_type(self, read_path, write_path):
dfMovies = self.get_data(read_path)
dfMovies.show()
"""计算两个rdd的笛卡尔积"""
rddMovieCartesianed = dfMovies.rdd.cartesian(dfMovies.rdd)
rddMovieIdAndGenre = rddMovieCartesianed.map(lambda line: Row(movie1=line[0]['movie_id'],
movie2=line[1]['movie_id'],
sim=countSimBetweenTwoMovie(line[0], line[1])))
dfFinal = self.sqlContext.createDataFrame(rddMovieIdAndGenre)
dfFinal.show()
self.write(dfFinal, write_path)
# 根据用户喜好、兴趣、年龄、城市计算相似度
def calculator_user_base(self, read_path, write_path):
dfUsers = self.get_data(read_path)
dfUsers.show()
"""计算两个rdd的笛卡尔积"""
rddUserCartesianed = dfUsers.rdd.cartesian(dfUsers.rdd)
rddUserIdAndGenre = rddUserCartesianed.map(lambda line: Row(user1=line[0]['user_id'],
user2=line[1]['user_id'],
sim=countSimBetweenTwoUser(line[0], line[1])))
dfFinal = self.sqlContext.createDataFrame(rddUserIdAndGenre)
dfFinal.show()
self.write(dfFinal, write_path)
# 根据用户的标签进行计算相似度
def calculator_user_tag(self, read_path, write_path):
dfUsers = self.get_data(read_path)
# dfUsers.show()
# print(change_user_tag_data(dfUsers.toPandas()))
dfUsers = self.sqlContext.createDataFrame(change_user_tag_data(dfUsers.toPandas()))
# dfUsers.show()
# """计算两个rdd的笛卡尔积"""
rddUserCartesianed = dfUsers.rdd.cartesian(dfUsers.rdd)
rddUserIdAndGenre = rddUserCartesianed.map(lambda line: Row(user1=line[0]['user_id'],
user2=line[1]['user_id'],
sim=countSimBetweenTwoUserByTag(line[0], line[1])))
dfFinal = self.sqlContext.createDataFrame(rddUserIdAndGenre)
# dfFinal.show()
self.write(dfFinal, write_path)
@staticmethod
def change_dataframe_to_li(data_frame, li_name):
data_frame = data_frame.toPandas()
data_li = np.array(data_frame[li_name])
data_li = data_li.tolist()
return data_li
# 查找相似的电影
def select_movie_to_movie(self, df_sim_movie, movie_id):
min_sim = 0.5
max_num = 300
df_sim_movie = df_sim_movie.orderBy('sim', ascending=0)\
.where(
(col('movie1') == movie_id) &
(col('sim').__ge__(min_sim)) &
(col('movie1') != col('movie2')))\
.limit(max_num).select('movie2')
df_sim_movie_li = self.change_dataframe_to_li(df_sim_movie, "movie2")
return df_sim_movie_li
# 查找相似的用户
def select_user_to_user(self, df_sim_user, user_id):
min_sim = 0.5
max_num = 300
df_sim_user = df_sim_user.orderBy('sim', ascending=0)\
.where(
(col('user1') == user_id) &
(col('sim').__ge__(min_sim)) &
(col('user1') != col('user2')))\
.limit(max_num).select('user2')
df_sim_user_li = self.change_dataframe_to_li(df_sim_user, "user2")
return df_sim_user_li
# 查询用户收藏、评论、评分良好的电影
def select_user_movie(self, df_users, user_id):
min_score = 3
max_num = 300
df_movies = df_users.orderBy('tag_weight', ascending=0) \
.where((
(col('tag_type') == 'like_movie_id') |
(col('tag_type') == 'rating_movie_id') |
(col('tag_type') == 'comment_movie_id')
# (col('tag_type') == 'rating_movie_id')
) & (col('tag_weight').__ge__(min_score)) & (col('user_id').__eq__(user_id))) \
.limit(max_num).select('tag_name').distinct()
movie_li = self.change_dataframe_to_li(df_movies, "tag_name")
# movie_li = np.array(df_movies.toPandas()["tag_name"])
# movie_li = movie_li.tolist()
return movie_li
def calculator_user_movie_recommend(self, user_path, tag_path, movie_sim_path, user_sim_path, calculator_type):
finial_rs = list()
# 取出用户信息user_id数据
df_users = self.get_data(user_path).select('user_id')
df_users.show()
# 读取用户标签信息
df_tag_users = self.get_data(tag_path)
df_tag_users.show()
# 读取电影相似度数据
df_movie_sim = self.get_data(movie_sim_path)
df_movie_sim.show()
# 读取用户相似度数据
df_user_sim = self.get_data(user_sim_path)
df_user_sim.show()
user_id_li = self.change_dataframe_to_li(df_users, "user_id")
if calculator_type == "movie": # 根据电影查找电影
for id, user_id in enumerate(list(user_id_li)):
user_movie_li = self.select_user_movie(df_tag_users, user_id)
user_movie_li_rs = list()
for user_movie_id in list(user_movie_li):
select_movie_to_movie_li = list(self.select_movie_to_movie(df_movie_sim, user_movie_id))
user_movie_li_rs = list(set(select_movie_to_movie_li + user_movie_li_rs)) # 合并List
user_movie_li_rs = ",".join(map(str, user_movie_li_rs)) # 转成字符串
finial_rs.append([id, user_id, user_movie_li_rs, datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')])
elif calculator_type == "user": # 根据用户查找电影
for id, user_id in enumerate(list(user_id_li)):
user_id_li_rs = self.select_user_to_user(df_user_sim, user_id)
user_movie_li_rs = list()
for user_id_rs in list(user_id_li_rs):
select_user_to_movie_li = list(self.select_user_movie(df_tag_users, user_id_rs))
user_movie_li_rs = list(set(select_user_to_movie_li + user_movie_li_rs)) # 合并List
user_movie_li_rs = ",".join(map(str, user_movie_li_rs)) # 转成字符串
finial_rs.append([id, user_id, user_movie_li_rs, datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')])
# print(finial_rs)
# 将数据转换
recommend = self.sqlContext.createDataFrame(finial_rs, ["id", "user_id", "movie_id_li", "create_time"])
# 写入数据库
recommend.write.jdbc(url=self.jdbcURL, table='user_usermovierecommend', mode='overwrite', properties=self.prop)
# 将数据从数据库中取出,并以parquet文件格式写入到HDFS里
def step_1(self):
sql1 = '(select user_id,tag_type,tag_weight,tag_name from user_usertag) user_tag_base'
path1 = self.hdfs_data_path + 'user_tag_base_'+self.date_time
self.change_sql_data_to_hdfs(sql1, path1)
# 测试时限制数量防止计算量过大
sql2 = '(SELECT `movie_id`,`title`,`rating`,`genres`,`countries`,`languages`,`year` FROM ' \
'movie_collectmoviedb limit 0,1000) movie_base'
path2 = self.hdfs_data_path + 'movie_base_'+self.date_time
self.change_sql_data_to_hdfs(sql2, path2)
# 用户信息
sql3 = '(select d.id user_id, b.user_gender gender, d.user_age age, d.user_prefer prefers, ' \
'd.user_hobbies hobbies, d.user_province province, d.user_city city, d.user_district district ' \
'from user_usersbase b join user_usersdetail d on b.id = d.user_id_id where b.user_status = 1) user_base'
path3 = self.hdfs_data_path + 'user_base_'+self.date_time
self.change_sql_data_to_hdfs(sql3, path3)
# 读取parquet文件,然后计算相似度
def step_2(self):
read_path1 = self.hdfs_data_path + 'user_tag_base_'+self.date_time
write_path1 = self.hdfs_data_path + 'user_tag_simContent_' + self.date_time
read_path2 = self.hdfs_data_path + 'movie_base_' + self.date_time
write_path2 = self.hdfs_data_path + 'movie_simContent_' + self.date_time
read_path3 = self.hdfs_data_path + 'user_base_'+self.date_time
write_path3 = self.hdfs_data_path + 'user_simContent_' + self.date_time
self.calculator_movie_type(read_path2, write_path2)
self.calculator_user_base(read_path3, write_path3)
self.calculator_user_tag(read_path1, write_path1)
# 读取parquet相似度数据,然后生成推荐内容,存储到mysql和HDFS
def step_3(self):
user_base_path = self.hdfs_data_path + 'user_base_'+self.date_time
user_tag_base_path = self.hdfs_data_path + 'user_tag_base_'+self.date_time
movie_sim_path = self.hdfs_data_path + 'movie_simContent_' + self.date_time
user_sim_path = self.hdfs_data_path + 'user_tag_simContent_'+self.date_time
# 根据相似用户进行推荐
# self.calculator_user_movie_recommend(user_base_path, user_tag_base_path,
# movie_sim_path, user_sim_path, "user")
# 根据相似电影进行推荐
self.calculator_user_movie_recommend(user_base_path, user_tag_base_path,
movie_sim_path, user_sim_path, "movie")
def countIntersectionForTwoSets(list1, list2):
"""计算两个集合的交集的模"""
count = 0
for i in range(len(list1)):
m = list1[i]
for j in range(len(list2)):
if list2[j] == m:
count = count + 1
break
return count
def countSimBetweenTwoList(list1, list2):
s1 = len(list1)
s2 = len(list2)
m = math.sqrt(s1 * s2)
if m == 0:
if s1 == 0 and s2 == 0:
return 1
else:
return 0
return countIntersectionForTwoSets(list1, list2) / m
def countSimBetweenTwoMovie(list1, list2):
"""计算两个Movie的相似度"""
movie_type_list1 = ast.literal_eval(list1['genres'])
movie_type_list2 = ast.literal_eval(list2['genres'])
movie_country_list1 = ast.literal_eval(list1['countries'])
movie_country_list2 = ast.literal_eval(list2['countries'])
movie_language_list1 = ast.literal_eval(list1['languages'])
movie_language_list2 = ast.literal_eval(list2['languages'])
movie_year1 = list1['year']
movie_year2 = list2['year']
movie_year = 1 if movie_year1 == movie_year2 else 0
movie_type = countSimBetweenTwoList(movie_type_list1, movie_type_list2)
movie_country = countSimBetweenTwoList(movie_country_list1, movie_country_list2)
movie_language = countSimBetweenTwoList(movie_language_list1, movie_language_list2)
sim = (movie_type * 5 + movie_country * 2 + movie_language * 2 + movie_year * 1) / 10
return sim
def countSimBetweenTwoUser(list1, list2):
"""计算两个User的相似度"""
user_prefer_list1 = list1['prefers'].split(",") if list1['prefers'] != '' and list1['prefers'] is not None else []
user_prefer_list2 = list2['prefers'].split(",") if list2['prefers'] != '' and list2['prefers'] is not None else []
user_hobbie_list1 = list1['hobbies'].split(",") if list1['hobbies'] != '' and list1['hobbies'] is not None else []
user_hobbie_list2 = list2['hobbies'].split(",") if list2['hobbies'] != '' and list2['hobbies'] is not None else []
user_gender = 1 if list1['gender'] == list2['gender'] else 0
user_province = 1 if list1['province'] == list2['province'] else 0
user_city = 1 if list1['city'] == list2['city'] else 0
user_district = 1 if list1['district'] == list2['district'] else 0
user_prefer = countSimBetweenTwoList(user_prefer_list1, user_prefer_list2)
user_hobbie = countSimBetweenTwoList(user_hobbie_list1, user_hobbie_list2)
sim = (user_prefer * 5 + user_hobbie * 2 + user_gender * 1 + user_province * 1 +
user_city * 0.5 + user_district * 0.5) / 10
return sim
def countSimBetweenTwoDict(info_movie_tag1_dict, info_movie_tag2_dict):
if not info_movie_tag1_dict and not info_movie_tag2_dict or info_movie_tag1_dict == info_movie_tag2_dict:
return 1
key_li1 = list(info_movie_tag1_dict.keys())
key_li2 = list(info_movie_tag2_dict.keys())
content_sim = countSimBetweenTwoList(key_li1, key_li2)
key_score = 0
if key_li1 and key_li2 and key_li1[0] == key_li2[0]:
key_score += 5
if len(key_li1) >= 2 and len(key_li2) >= 2 and key_li1[1] == key_li2[1]:
key_score += 3
if len(key_li1) >= 3 and len(key_li2) >= 3 and key_li1[2] == key_li2[2]:
key_score += 2
key_score = (content_sim + key_score / 10) / 2
return key_score
def countSimBetweenTwoUserByTag(list1, list2):
"""计算两个User的相似度"""
# info_age、info_city、info_phone_city、info_province、info_sex
# info_movie_tag、info_movie_type
# List:like_movie_id、info_hobbies、rating_movie_id
user_tag_list1 = ast.literal_eval(list1['user_data'])
user_tag_list2 = ast.literal_eval(list2['user_data'])
info_age1 = user_tag_list1.get("user_info").get("info_age")
info_city1 = user_tag_list1.get("user_info").get("info_city")
info_phone_city1 = user_tag_list1.get("user_info").get("info_phone_city")
info_province1 = user_tag_list1.get("user_info").get("info_province")
info_sex1 = user_tag_list1.get("user_info").get("info_sex")
info_movie_tag1_dict = user_tag_list1.get("info_movie_tag")
info_movie_type1_dict = user_tag_list1.get("info_movie_type")
like_movie_id1_li = user_tag_list1.get("like_movie_id")
info_hobbies1_li = user_tag_list1.get("info_hobbies")
rating_movie_id1_li = user_tag_list1.get("rating_movie_id")
info_age2 = user_tag_list2.get("user_info").get("info_age")
info_city2 = user_tag_list2.get("user_info").get("info_city")
info_phone_city2 = user_tag_list2.get("user_info").get("info_phone_city")
info_province2 = user_tag_list2.get("user_info").get("info_province")
info_sex2 = user_tag_list2.get("user_info").get("info_sex")
info_movie_tag2_dict = user_tag_list2.get("info_movie_tag")
info_movie_type2_dict = user_tag_list2.get("info_movie_type")
like_movie_id2_li = user_tag_list2.get("like_movie_id")
info_hobbies2_li = user_tag_list2.get("info_hobbies")
rating_movie_id2_li = user_tag_list2.get("rating_movie_id")
if (info_age1 and info_age2 and int(info_age1) in range(int(info_age2)-3, int(info_age2)+3)) or \
(not info_age1 and not info_age2):
info_age = 1
else:
info_age = 0
info_city = is_exist_and_equal(info_city1, info_city2)
info_sex = is_exist_and_equal(info_sex1, info_sex2)
info_phone_city = is_exist_and_equal(info_phone_city1, info_phone_city2)
info_province = is_exist_and_equal(info_province1, info_province2)
like_movie_id_li = is_exist_and_equal_li(like_movie_id1_li, like_movie_id2_li)
info_hobbies_li = is_exist_and_equal_li(info_hobbies1_li, info_hobbies2_li)
rating_movie_id_li = is_exist_and_equal_li(rating_movie_id1_li, rating_movie_id2_li)
if (info_movie_tag1_dict and info_movie_tag2_dict) or (not info_movie_tag1_dict and not info_movie_tag2_dict):
info_movie_tag_dict = countSimBetweenTwoDict(info_movie_tag1_dict, info_movie_tag2_dict)
else:
info_movie_tag_dict = 0
if (info_movie_type1_dict and info_movie_type2_dict) or (not info_movie_type1_dict and not info_movie_type2_dict):
info_movie_type_dict = countSimBetweenTwoDict(info_movie_type1_dict, info_movie_type2_dict)
else:
info_movie_type_dict = 0
sim = (info_movie_tag_dict * 2 + info_movie_type_dict * 2 + like_movie_id_li * 1 + info_hobbies_li * 1 +
rating_movie_id_li * 1 + info_age * 1 + info_city * 0.5 + info_sex * 0.5 + info_phone_city * 0.5 +
info_province * 0.5) / 10
return sim
def is_exist_and_equal_li(str1, str2):
if not str1 and not str2:
return 1
if str1 and str2:
return countSimBetweenTwoList(str1, str2)
else:
return 0
def is_exist_and_equal(str1, str2):
# if (str1 and str2 and str2 == str1) or (not str1 and not str2):
if str2 == str1:
return 1
else:
return 0
# 将用户的数据进行格式化
def change_user_tag_data(data):
list_tag = ["like_movie_id", "info_hobbies", "rating_movie_id"]
dict_tag = ["info_movie_tag", "info_movie_type"]
all_user_data_rs = list()
for user_data in data.groupby(["user_id"]):
user_data_rs = dict()
user_id = user_data[0]
user_data_rs["user_id"] = user_id
user_tag_rs = dict()
user_info_dict = dict()
for user_tag_data in pd.DataFrame(user_data[1]).drop("user_id", axis=1).groupby(["tag_type"]):
if user_tag_data[0] in dict_tag:
# print(user_data[1])
info_movie_tag = pd.DataFrame(user_tag_data[1]).drop(["tag_type"], axis=1).sort_values("tag_weight",
ascending=False)
info_movie_tag = collections.OrderedDict(zip(info_movie_tag["tag_name"], info_movie_tag["tag_weight"]))
user_tag_rs[user_tag_data[0]] = dict(info_movie_tag)
# print(dict(info_movie_tag))
elif user_tag_data[0] in list_tag:
# print(user_data[1])
like_movie_id = pd.DataFrame(user_tag_data[1]).drop(["tag_type"], axis=1).sort_values("tag_weight",
ascending=False)
like_movie_id = list(like_movie_id["tag_name"])
user_tag_rs[user_tag_data[0]] = like_movie_id
# print(like_movie_id)
else:
user_info = pd.DataFrame(user_tag_data[1]).drop(["tag_weight"], axis=1)
user_info_dict[user_info["tag_type"].values[0]] = user_info["tag_name"].values[0]
user_tag_rs["user_info"] = user_info_dict
user_data_rs["user_data"] = str(user_tag_rs)
all_user_data_rs.append(user_data_rs)
# print(all_user_data_rs)
# return all_user_data_rs
return pd.DataFrame(all_user_data_rs)
# 将数据从数据库中取出,并以parquet文件格式写入到HDFS里
calculator = Calculator()
try:
# 从HDFS中读取出
calculator.step_1()
calculator.step_2()
calculator.step_3()
except Exception as ex:
print(ex)
# 终止程序
calculator.sc.stop()
calculator.sc.stop()

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 13
13 0
0- 0



 已为社区贡献66条内容
已为社区贡献66条内容

所有评论(0)