Datax实现异构数据库全量同步和增量同步
2024-12-11 14:58:28.620 [0-0-0-writer] WARNCommonRdbmsWriter$Task - 回滚此次写入, 采用每次写入一行方式提交. 因为:Could not retrieve transation read-only status server。这里可以在写入之前执行sql,例如把表清空,postSql写入后执行, 但是要注意数据库账号权限,是写入模
1、环境
-
jdk1.8
-
python2.7.x/3.x
-
安装mysql客户端,使用mysql -h命令连接
-
查看Windowns/System32是否存在,命令echo %PATH%
2、datax.gz下载, windowns为例
https://github.com/alibaba/DataX/blob/master/userGuid.md
3、 推荐方法一下载解压即可,D:\bsd\datax
自检脚本,配置了datax的环境变量可不用进入bin目录
来到datx的bin目录下cmd执行python datax.py ../job/job.json
 出现这个页面就ok;乱码的可以先执行
出现这个页面就ok;乱码的可以先执行chcp 65001更改一下字符编码;
4、配置示例
datax是通过json文件配置job的运行规则的
通过python datax.py -r streamreader -w streamwriter可获得示例脚本
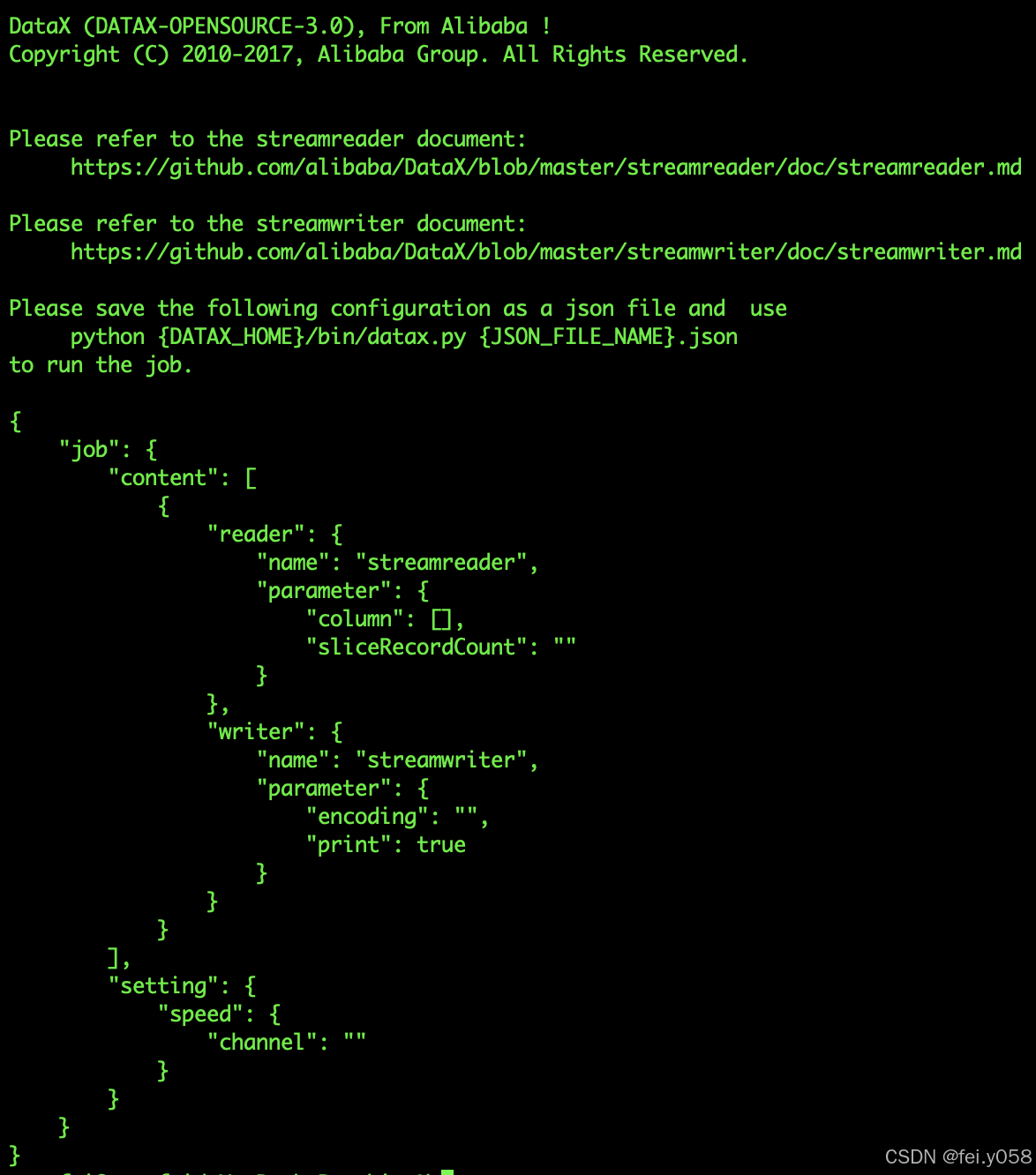
5、根据此模板在bin下新建stream.json文件
{
"job": {
"content": [
{
"reader": {
"name": "sqlserverreader",
"parameter": {
"username": "test",
"password": "test",
"column": [
"Id",
"Remark",
"UpdateTime"
],
"splitPk": "",
"connection": [
{
"table": ["[dbo].[test]"],
"jdbcUrl": ["jdbc:sqlserver://1.1.1.1:1500;DatabaseName=SummerFresh_SuperStationBD"]
}
],
"where": "id > ${last_max_id}"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "test",
"password": "test",
"column": [
"Id",
"Remark",
"UpdateTime"
],
"session": [
"set session sql_mode='ANSI'"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/test?useUnicode=true&characterEncoding=utf8",
"table": ["test"]
}
]
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
根据时间
"where": "UpdateTime > ${last_sync_time}"
reader是读,writer是写,这里要注意的是读取时我用了querySql来筛选数据,另外写入是preSql这里可以在写入之前执行sql,例如把表清空,postSql写入后执行, 但是要注意数据库账号权限,writeMode是写入模式,insert是追加,update是有则更新无则追加
6、bat脚本,根据id,时间更新
@echo off
REM 更加时间增量或全量同步的脚本,全量默认id为0,即查询>0的数据开始全量同步
REM 设置 DataX安装目录
set DATAX_HOME=D:\bsd\datax
REM 设置日志目录
set LOG_DIR=D:\bsd\datax\log
REM 设置配置文件目录
set JOB_DIR=D:\bsd\datax\job
REM 定义表名
set TABLE=test
REM 设置同步连接HOST
set HOST=127.0.0.1
REM 设置同步连接用户名
set USERNAME=test
REM 设置同步连接密码
set PASSWORD=test
REM 设置同步端口
set PORT=3306
REM 设置同步库名
set SYNC_DATABASE=testDb
REM 中文乱码处理
chcp 65001
REM 构造job文件
set JOB_FILE=%JOB_DIR%\%TABLE%.json
REM 构造log文件
set LOG_FILE=%LOG_DIR%\%TABLE%.log
set last_max_id=0
set flag=0
REM 查询同步的时间
cd /d D:\bsd\datax\bin
echo "json文件" %JOB_FILE%
for /f %%a in ('mysql -h %HOST% -P %PORT% -u %USERNAME% -p%PASSWORD% --default-character-set=utf8 %SYNC_DATABASE% -e "SELECT max(id) FROM %TABLE%"') do (
echo "从数据库获取到:" %%a
set last_max_id=%%a
set flag=1
)
if defined last_max_id (
if "%last_max_id%"=="NULL" (
set last_max_id=0
set flag=0
) else (
echo 变量last_max_id不为空,其值为:%last_max_id%
)
) else (
echo 变量last_max_id未定义
)
REM 执行 DataX 全量同步任务
python datax.py %JOB_FILE% -p "-Dlast_max_id=\"%last_max_id%\"" > %LOG_FILE% 2>&1 &
for /f %%a in ('mysql -h %HOST% -P %PORT% -u %USERNAME% -p%PASSWORD% --default-character-set=utf8 %SYNC_DATABASE% -e "SELECT max(id) FROM %TABLE%"') do (
echo "从数据库获取到:" %%a
set last_max_id=%%a
)
echo "last_max_id" %last_max_id%
echo "执行success" %errorlevel%
findstr /C:"successfully" %LOG_FILE% >nul
if %errorlevel% equ 0 (
if %flag% equ 0 (
echo '全量成功'
mysql -h %HOST% -P %PORT% -u %USERNAME% -p%PASSWORD% %SYNC_DATABASE% -e "INSERT INTO sync_status (table_name, last_max_id) VALUES ('%TABLE%', '%last_max_id%')"
) else (
mysql -h %HOST% -P %PORT% -u %USERNAME% -p%PASSWORD% %SYNC_DATABASE% -e "UPDATE sync_status SET last_max_id = '%last_max_id%' WHERE table_name = '%TABLE%'"
echo '增量成功'
)
) else (
echo '同步失败,请查看日志'
)
@echo off
REM 更加时间增量或全量同步的脚本,全量默认开始时间为1970-01-01 00:00:00
REM 设置 DataX安装目录
set DATAX_HOME=D:\bsd\datax
REM 设置日志目录
set LOG_DIR=D:\bsd\datax\log
REM 设置配置文件目录
set JOB_DIR=D:\bsd\datax\job
REM 定义表
set TABLE=test
REM 设置同步连接HOST
set HOST=127.0.0.1
REM 设置同步连接用户名
set USERNAME=test
REM 设置同步连接密码
set PASSWORD=test@
REM 设置同步端口
set PORT=3306
REM 设置同步库名
set SYNC_DATABASE=testDb
REM 中文乱码处理
chcp 65001
REM 构造job文件
set JOB_FILE=%JOB_DIR%\%TABLE%.json
REM 构造log文件
set LOG_FILE=%LOG_DIR%\%TABLE%.log
set last_sync_time=1970-01-01 00:00:00
set flag=0
REM 查询同步的时间
for /f "tokens=1,2 delims= " %%a in ('mysql -h %HOST% -P %PORT% -u %USERNAME% -p%PASSWORD% --default-character-set=utf8 %SYNC_DATABASE% -e "SELECT last_sync_time FROM sync_log WHERE table_name = '%TABLE%'"') do (
echo "从数据库获取到:" %%a %%b
set last_sync_time=%%a %%b
set flag=1
)
echo %last_sync_time%
rem 获取当前时间,格式调整为 HH:mm:ss
for /f "tokens=1-2 delims=:" %%a in ("%time%") do (
set "hour=0%%a"
set "min=0%%b"
)
set "hour=%hour:~-2%"
set "min=%min:~-2%"
set "sec=%time:~6,2%"
rem 组合成最终格式的时间字符串
set currentTime=%date% %hour%:%min%:%sec%
echo 当前时间:%currentTime%
cd /d D:\bsd\datax\bin
echo "json文件" %JOB_FILE%
REM 执行 DataX 全量同步任务
python datax.py %JOB_FILE% -p "-Dlast_sync_time=\"%last_sync_time%\"" > %LOG_FILE% 2>&1 &
echo "执行success" %errorlevel%
findstr /C:"successfully" %LOG_FILE% >nul
if %errorlevel% equ 0 (
if %flag% equ 0 (
echo '全量成功'
mysql -h %HOST% -P %PORT% -u %USERNAME% -p%PASSWORD% %SYNC_DATABASE% -e "INSERT INTO sync_log (table_name, last_sync_time) VALUES ('%TABLE%', '%currentTime%')"
) else (
mysql -h %HOST% -P %PORT% -u %USERNAME% -p%PASSWORD% %SYNC_DATABASE% -e "UPDATE sync_log SET last_sync_time = '%currentTime%' WHERE table_name = '%TABLE%'"
echo '增量成功'
)
) else (
echo '同步失败,请查看日志'
)
多个表一个bat,可以通过for循环实现
7、同步表sql-mysql
#根据id
CREATE TABLE `sync_status` (
`id` int NOT NULL AUTO_INCREMENT,
`table_name` varchar(64) DEFAULT NULL,
`last_max_id` bigint DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB COMMENT='数据同步id记录表';
#根据时间
CREATE TABLE `sync_log` (
`table_name` varchar(100) '表名',
`last_sync_time` datetime NOT NULL COMMENT '最新同步时间',
PRIMARY KEY (`table_name`)
) ENGINE=InnoDB COMMENT='数据同步时间记录表';7、bat执行,双击
通过 Windows 任务计划程序新建任务来执行 BAT 脚本
- 打开 “任务计划程序”:可以通过在 Windows 搜索框中输入 “任务计划程序” 并回车来打开它。
- 在任务计划程序中,点击 “操作” 菜单,然后选择 “创建任务”。
- 在 “常规” 选项卡中:
- 为任务输入一个名称(例如 “执行 BAT 脚本任务”)和描述(可选)。
- 根据需要设置任务的安全选项,如以何种用户身份运行任务。
- 切换到 “触发器” 选项卡:
- 点击 “新建” 按钮来设置任务的触发条件。例如,可以设置任务在每天特定时间运行、在系统启动时运行、在登录时运行等。比如,设置任务在每天下午 3 点运行,就可以选择 “按日程安排”,然后在 “设置” 中选择 “每天”,并将时间设置为 15:00:00。
- 切换到 “操作” 选项卡:
- 点击 “新建” 按钮,在 “操作” 下拉菜单中选择 “启动程序”。
- 在 “程序或脚本” 字段中,输入 BAT 脚本文件的完整路径。例如,如果
test.bat文件保存在桌面上,路径可能是D:\bsd\datax\job\test.bat。
- 切换到 “条件” 和 “设置” 选项卡:
- 根据需要设置任务运行的条件(如仅当计算机空闲时运行等)和其他设置(如任务运行失败后的重试策略等)。
- 完成设置后,点击 “确定” 保存任务。这样,根据设置的触发条件,Windows 就会自动执行 BAT 脚本
- 通过任务计划程序执行多个 BAT 脚本
- 方式一:创建多个任务
- 打开 “任务计划程序”,按照前面步骤为每个 BAT 脚本分别创建任务。每个任务都有自己独立的名称、触发条件和操作。例如,对于
test.bat设置一个每天早上 9 点执行的任务,对于test2.bat设置一个每周一晚上 8 点执行的任务。
- 打开 “任务计划程序”,按照前面步骤为每个 BAT 脚本分别创建任务。每个任务都有自己独立的名称、触发条件和操作。例如,对于
- 方式二:在一个 BAT 脚本中调用其他 BAT 脚本
- 创建一个主 BAT 脚本(例如
main.bat),内容如下
- 创建一个主 BAT 脚本(例如
- 方式一:创建多个任务
-
@echo off call C:\Scripts\test.bat call C:\Scripts\test2.bat - 这样,当执行
main.bat时,它会依次调用test.bat和test2.bat。然后在任务计划程序中,只需要创建一个执行main.bat的任务即可。设置这个任务的触发条件,如每月 1 号执行,就可以通过这个任务同时运行多个 BAT 脚本。
8、DataX3.0支持的插件,也就是能在这些数据源直接根据json脚本配置互相同步数据
| 类型 | 数据源 | Reader(读) | Writer(写) | 文档 |
|---|---|---|---|---|
| RDBMS 关系型数据库 | MySQL | √ | √ | 读 、写 |
| Oracle | √ | √ | 读 、写 | |
| OceanBase | √ | √ | 读 、写 | |
| SQLServer | √ | √ | 读 、写 | |
| PostgreSQL | √ | √ | 读 、写 | |
| DRDS | √ | √ | 读 、写 | |
| 达梦 | √ | √ | 读 、写 | |
| 通用RDBMS(支持所有关系型数据库) | √ | √ | 读 、写 | |
| 阿里云数仓数据存储 | ODPS | √ | √ | 读 、写 |
| ADS | √ | 写 | ||
| OSS | √ | √ | 读 、写 | |
| OCS | √ | √ | 读 、写 | |
| NoSQL数据存储 | OTS | √ | √ | 读 、写 |
| Hbase0.94 | √ | √ | 读 、写 | |
| Hbase1.1 | √ | √ | 读 、写 | |
| MongoDB | √ | √ | 读 、写 | |
| Hive | √ | √ | 读 、写 | |
| 无结构化数据存储 | TxtFile | √ | √ | 读 、写 |
| FTP | √ | √ | 读 、写 | |
| HDFS | √ | √ | 读 、写 | |
| Elasticsearch | √ | 写 |
9、异常
2024-12-11 14:58:28.620 [0-0-0-writer] WARN CommonRdbmsWriter$Task - 回滚此次写入, 采用每次写入一行方式提交. 因为:Could not retrieve transation read-only status server
rm -rf /Users/**/Documents/datax/plugin/writer/.DS_Store
10、无id,时间的,全量同步
json文件 writer
"preSql": [ "TRUNCATE TABLE test" ]
11、reader和writer字段不一致的按顺序列字段即可

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)