Ultra-Fast-Lane-Detection车道线模型训练自己数据集(基于culane模型)
1、克隆项目2、创建虚拟环境,安装依赖包3、进行labelme标注关注下“labelme”、“points”
·
1、克隆项目
2、创建虚拟环境,安装依赖包
3、进行labelme标注
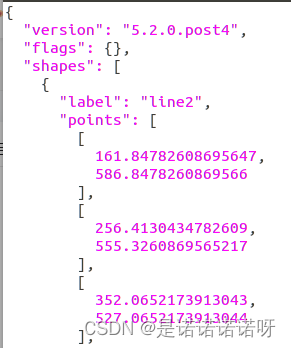 关注下“labelme”、“points”
关注下“labelme”、“points”
4、生成culane格式
以生成训练集为例
首先新建文件夹,放入图片集
mkdir train_dataset将json文件放入train_dataset中,执行
python scripts/json2culane.py 这时候会在train_dataset生成文件夹

其中images_dir存储原始图片;
labels_dir存储掩码图,打开基本漆黑一片,实际存车道线的掩码图;
train_gt.txt存储标签

执行$ python json2culane.py前需要修改下列部分
data_root = "/home/lyn/Desktop/cdx0822/train_dataset/"
json_file = "/home/lyn/Desktop/cdx0822/train_dataset/train_json/"
dir_img = '/images_dir/'
dir_labelimg = '/labels_dir/'
train_gt_txt = data_root + 'list/train_gt.txt'json2culane.py代码如下:
# encoding:utf-8
import argparse
import json
import os
import os.path as osp
import base64
import warnings
import PIL.Image
import yaml
from labelme import utils
#import cv2
import numpy as np
#from skimage import img_as_ubyte
def json2point_txt(path_json, path_txt): # 可修改生成格式生成
with open(path_json, 'r') as path_json:
jsonx = json.load(path_json)
with open(path_txt, 'w+') as ftxt:
for shape in jsonx['shapes']:
label = str(shape['label']) + ' '
xy = np.array(shape['points'])
strxy = ''
for m, n in xy:
m = int(m)
n = int(n)
# print('m:',m)
# print('n:',n)
strxy += str(m) + ' ' + str(n) + ' '
label = strxy
ftxt.writelines(label + "\n")
def json2gt_txt(path_json, path_img, path_labelimg, train_gt_txt): # 可修改生成格式
with open(path_json, 'r') as path_json:
jsonx = json.load(path_json)
with open(train_gt_txt, 'a+') as ftxt:
labelarray = [0,0,0,0]
for shape in jsonx['shapes']:
# label = int(shape['label'])
'''if(shape['label'] == "left_lanes"):
label =2
elif(shape['label'] == "right_lanes"):
label =3
else:
label =1'''
if(shape['label'] == "line1"):
label=1
elif(shape['label'] == "line2"):
label=2
elif(shape['label'] == "line3"):
label=3
elif(shape['label'] == "line4"):
label=4
if label == 1:
labelarray[0] = 1
if label == 2:
labelarray[1] = 1
if label == 3:
labelarray[2] = 1
if label == 4:
labelarray[3] = 1
labelstr = str(labelarray[0])+ " " + str(labelarray[1])+ " " + str(labelarray[2])+ " " + str(labelarray[3])
ftxt.writelines(labelstr + "\n")
def main():
#json_file = args.json_file
data_root = "/home/lyn/Desktop/cdx0829/val/"
json_file = "/home/lyn/Desktop/cdx0829/val/val_json/"
dir_img = '/images_dir/'
dir_labelimg = '/labels_dir/'
train_gt_txt = data_root + 'list/val_gt.txt'
list_path = os.listdir(json_file)
# line_txt = '/home/lyn/Desktop/cdx0829/val/line_txt/' # txt存储目录
list_dir = osp.join(data_root, 'list')
if not osp.exists(list_dir):
os.mkdir(list_dir)
images_dir = osp.join(data_root, 'images_dir')
if not osp.exists(images_dir):
os.mkdir(images_dir)
labels_dir = osp.join(data_root, 'labels_dir')
if not osp.exists(labels_dir):
os.mkdir(labels_dir)
# if not os.path.exists(line_txt):
# os.makedirs(line_txt)
for i in range(0, len(list_path)):
if list_path[i].endswith('.json'):
path_json = os.path.join(json_file, list_path[i])
if os.path.isfile(path_json):
data = json.load(open(path_json))
img = utils.img_b64_to_arr(data['imageData'])
lbl, lbl_names = utils.labelme_shapes_to_label(img.shape, data['shapes'])
captions = ['%d: %s' % (l, name) for l, name in enumerate(lbl_names)]
lbl_viz = utils.draw_label(lbl, img, captions)
save_file_name = osp.basename(path_json).split('.')[0]
PIL.Image.fromarray(img).save(osp.join(images_dir, '{}.jpg'.format(save_file_name)))
PIL.Image.fromarray(lbl).save(osp.join(labels_dir, '{}.png'.format(save_file_name)))
# 生成lines.txt
path_txt = images_dir + "/" + list_path[i].replace('.json', '.lines.txt')
# print(path_txt)
json2point_txt(path_json, path_txt)
# 生成train_gt_txt
path_img = dir_img + list_path[i].replace('.json', '.jpg')
path_labelimg = dir_labelimg + list_path[i].replace('.json', '.png')
with open(train_gt_txt, 'a+') as ftxt:
ftxt.writelines(path_img + " " + path_labelimg + " ") #写入txt文件
json2gt_txt(path_json, path_img, path_labelimg, train_gt_txt)
if __name__ == '__main__':
# base64path = argv[1]
main()5、配置culane参数,进行训练
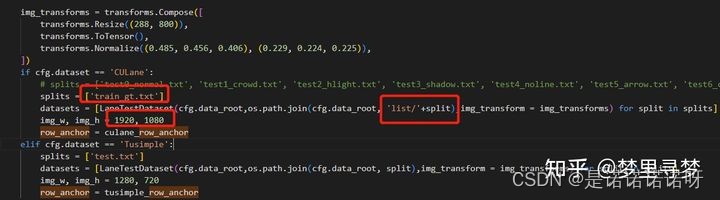
python train.py configs/culane.py
其中configs/culane.py 需要修改一下 训练集的数据 海可以更改训练参数比如:
# epoch , batch_size ,optimizer ,learning_rate,adam
其中log_path项必填
log_path = "./result"
dataset='CULane'
# 训练集的数据路径,
data_root = './train_dataset'
python train.py configs/culane.py --batch_size 8每一轮epoch都会生成一次pth
6、可视化日志
tensorboard --logdir ./result --bind_all7、demo展示生成avi
修改demo.py对应参数,其中train_gt.txt只是为了方便,此时你应该用你的验证集看看效果。不然训练的数据去看是不合理的。
python demo.py configs/culane.py --test_model xxx/xxx/ep099.pth(权重文件的地址)
DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 3
3 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)