
【具身智能 Affordance learning论文精读系列】Learning Affordance Landscapes for Interaction Exploration in 3D Env
具身智能affordance learning论文精读系列。本文提出了 “交互探索” 的任务,并开发了可以学习在新环境中有效行动的代理(Agent),为下游交互任务做准备,同时构建物体affordance的内部模型。
前言
本系列面向两种读者:(1)想浅显、直观了解论文的主要方法(2)读论文的时候有地方不理解,想深入研究论文的细节
本文是NeurIPS 2020年的作品,来自FAIR(Facebook AI Research),通讯作者Kristen Grauman,目前76次引用。
- 论文地址:https://arxiv.org/abs/2008.09241
核心思想
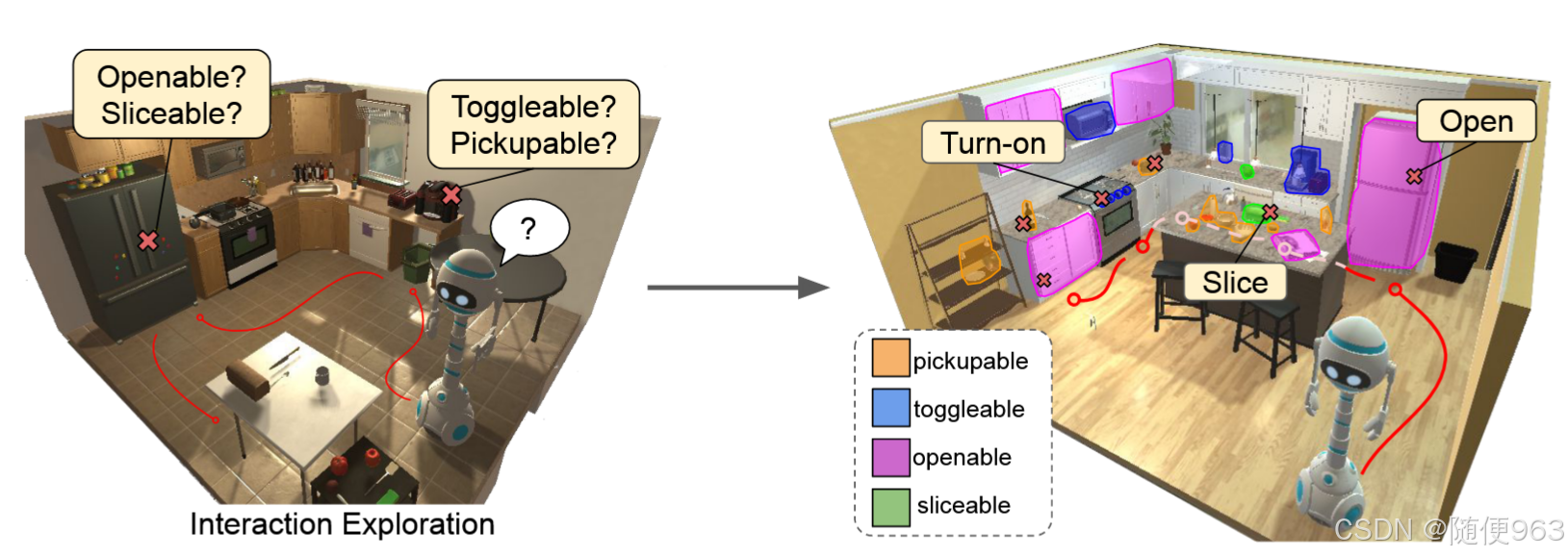
考虑机器人处于一个未知的环境中,具有大搜索空间和复杂的环境动态,很多物体可能是隐藏于视野外的,这时机器人应该如何了解环境?
不同于传统的视觉导航,作者希望让机器人具有迅速探索未知环境中的能力,了解环境中物体的属性(主要是affordance信息),因此把这一过程分为两阶段:
(1)探索环境:尽快的探索环境中所有物体可能的交互方式,从而获取数据
(2)预测affordance信息:根据上一阶段提供的数据监督训练。给定视觉信息,模型能从中提取affordance信息,用于下游任务。
探索阶段的动作集分别是(1)导航动作(navigation actions, 例如: move forward, turn left/right)(2)物体交互动作 (object interactions, 例如: take/put, open/close).
作者的总结:
我们提出了 “交互探索” 的任务,并开发了可以学习在新环境中有效行动的代理(Agent),为下游交互任务做准备,同时构建物体affordance的内部模型。
相关工作
- 视觉affordance。以往的工作聚焦于在静态的数据中利用目标检测、语义分割等方式获取affordance信息,但本文力图在探索中适应动态环境,在获得affordance信息的同时,学习到探索交互的策略
- 3D 环境中的探索导航。作者强调他们的工作能实现在动态环境中探索交互(例如打开/关闭门,捡起物体)。他们的目标不是在探索中建立一个地图,而是尽快的在未知场景中探索可能的交互物体,从而获取到更多的affordance数据
方法
我们的动机是(1)为了更好的探索(explore)未知的区域,以及其可交互的affordance属性,从而获取充分的数据。(2)学习到场景中affordance的信息
探索
因为缺乏监督信息,所以使用RL技术进行探索。RL的标准配置如下,在t时刻:
- state s t = ( x t , θ t ) s_t=(x_t, θ_t) st=(xt,θt) ,分别代表RGB图像和里程计(odometry,不明白什么意思)
- action a t a_t at,请参见“配置”一节,包含导航(navigation,也就是移动)、交互(interact)两大类
- reward如下,只奖励没有探索过的区域,o表示object,
A
I
A_I
AI是交互动作的集合
R ( s t , a t , s t + 1 ) = { 1 if a t ∈ A I and c ( a t , o t ) = 0 0 otherwise , R(s_t, a_t, s_{t+1}) = \begin{cases} 1 & \text{if } a_t \in \mathcal{A}_I \text{ and } c(a_t, o_t) = 0 \\ 0 & \text{otherwise}, \end{cases} R(st,at,st+1)={10if at∈AI and c(at,ot)=0otherwise,
c ( a , o ) c(a,o) c(a,o) 计算交互 ( a , o ) (a, o) (a,o) 在过去成功发生的次数。这一策略只奖励机器人去探索不同的可交互物体,并尝试不同的动作。虽然navigation动作并没有reward,但是为了遇到更多的新奇物体,机器人必须学会移动并找到新的物体。
探索过程如下图所示:
预测affordance属性
作者把预测affordance属性看作了一个语义分割的问题,使用常用的分割模型Unet。
- 输入:RGB-D图像,C*H*W
- 输出:segmentation map,shape = ( A I A_I AI, H, W),通道维度为 A I A_I AI,代表交互动作的种类数量。简言之,对每个像素点专门为每一个动作预测一个affordance分数,这里的动作类别就是语义分割中的“语义标签”,每个通道对应一个动作
数据收集:
训练的ground truth label是不容易获取的,所以采用上一exploration阶段得到的轨迹数据对集合
M
=
{
(
p
t
,
a
t
,
z
t
)
}
t
=
t
1
.
.
t
N
M = \{(p_t, a_t, z_t)\}_{t=t_1..t_N}
M={(pt,at,zt)}t=t1..tN。
- p t p_t pt:使用逆透视投影(inverse perspective projection),计算出agent视野中心的(二维)坐标的对应世界(三维)坐标。同时反向传播到之前帧的相同点,请参见“训练”一节,这很重要。
- a t ∈ A I a_t \in A_I at∈AI:这里的时刻 t = t 1 . . t N t=t_1..t_N t=t1..tN是被选取过的,只保留了有交互时刻的交互动作,没有导航动作
- z t z_t zt:物体交互是否成功。问题是:如何确定是否成功?请看“问题”一节
请注意:确定交互物体位置的时候并没有明确定位到末端执行器的位置,而是取视野中心,默认为交互位置。
如何训练:
首先关注affordance分数的label是如何设置的:
对于 i 行 j 列 k 通道的点,预测一个affordance分数,ground truth(GT)标签为y:
y
i
j
k
=
{
0
if
min
(
p
,
a
,
z
)
∈
M
k
d
(
p
i
j
,
p
)
<
δ
and
z
=
0
1
if
min
(
p
,
a
,
z
)
∈
M
k
d
(
p
i
j
,
p
)
<
δ
and
z
=
1
−
1
otherwise
y^k_{ij} = \begin{cases} 0 & \text{if } \min_{(p,a,z)\in M_k} d(p_{ij}, p) < \delta \text{ and } z = 0 \\ 1 & \text{if } \min_{(p,a,z)\in M_k} d(p_{ij}, p) < \delta \text{ and } z = 1 \\ -1 & \text{otherwise} \end{cases}
yijk=⎩
⎨
⎧01−1if min(p,a,z)∈Mkd(pij,p)<δ and z=0if min(p,a,z)∈Mkd(pij,p)<δ and z=1otherwise
M
k
M_k
Mk表示数据对集合,d表示欧氏距离,
δ
\delta
δ设置为20cm,z表示是否成功
可见1分表示可交互,0分表示还可以,-1分表示完全不行。
作者考虑了两种标注label的方式,发现第二种更好一些,就是上面公式里的方法:
- 只标记交互的单个点为可交互的
- 标记交互点对应的物体,换句话说,如果物体交互成功,就标记周围像素为可交互的,y=1。
损失函数
作者说这些label是sparse and noisy的,因为尽管在其他条件下有效(例如,打开已打开的橱柜),但与物体的交互可能会失败,所以对y是否等于-1的两种情况分别设计了损失函数,这是一个二分类问题,所以采用交叉熵:
L ( y ^ A , y ^ I , y ) = L c e ( y ^ A , y , ∀ y i , j ≠ − 1 ) + L c e ( y ^ I , 1 [ y = − 1 ] , ∀ y i , j ) \mathcal{L}(\hat{y}_A, \hat{y}_I, y) = \mathcal{L}_{ce}(\hat{y}_A, y, \forall y_{i,j} \neq -1) + \mathcal{L}_{ce}(\hat{y}_I, \mathbf{1}[y=-1], \forall y_{i,j}) L(y^A,y^I,y)=Lce(y^A,y,∀yi,j=−1)+Lce(y^I,1[y=−1],∀yi,j)
前者 y A y_A yA表示在可交互点附近,要求判断是否可交互;后者 y I y_I yI表示对于所有点,判断是否在可交互点附近。
最后输出是: y ^ = y ^ A × ( 1 − y ^ I ) \hat{y} = \hat{y}_A \times (1 - \hat{y}_I) y^=y^A×(1−y^I),表示可交互的affordance分数。根据公式,可以看到 y I = 1 y_I=1 yI=1的部分被轻易排除,这时只要关注 y A y_A yA就好了。如果不分开算交叉熵损失,可能有正负样本不平衡的风险,模型不会把 y i , j ≠ − 1 y_{i,j}\neq -1 yi,j=−1的情况很好的分类。
训练
右图是Affordance的训练数据,可以看到有一个“反向传播”的过程,这很重要,保证在其他视角(哪怕是视野的边缘)也能检索到可交互的物体,而不是只当物体出现在视野中心才能判断它的affordance信息。
通过计算机图形学的技术,根据移动轨迹定位到之前帧中的可交互物体(图中绿色区域),分配给可交互的标签,参与训练。
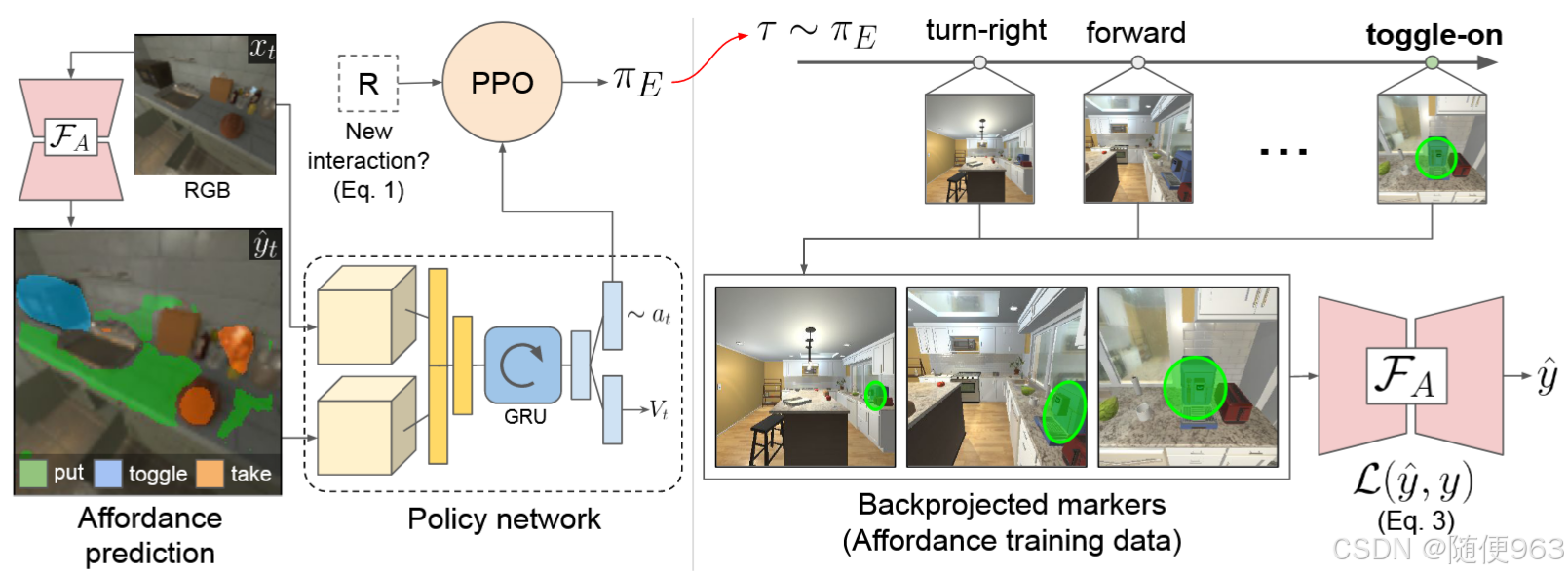
作者使用了actor-critic和PPO方法(这里需要对actor-critic架构有了解),没搞明白evalute阶段的critic: Q函数是怎么估计的
使用迭代方式轮流训练探索策略网络和分割模型(这是强化学习的惯用方式)。
(1)探索策略网络接收RGB图像和affordance信息图作为输入,经过CNN提取特征后concatenate起来,输入到GRU(因为RL需要之前时刻的信息)中产生动作
a
t
a_t
at
(2)使用前一阶段的数据对buffer,进行训练
配置
- AI2-iTHOR数据集
- ego-centric视角
- 导航动作(navigation): A N A_N AN = {move forward, turn left/right 30◦, look up/down 15◦}
- 交互动作(interact): A I A_I AI = {take, put, open, close, toggle-on,toggle-off, slice}
问题
-
视角是如何确定的?会随着探索而变化吗?
答:第一人称视角,如图所示

-
学习到的探索策略和affordance信息如何部署到下游任务中?
答:冻结探索策略网络和affordance网络,微调actor-critic线性层 -
如何判断物体是否被交互成功?也就是说,如何确定监督学习中的z的值?
答:对于给定动作:put, open, close,可能需要复杂的判断才能做到准确,也可以仅仅以物体移动了一段距离作为成功的标志。这点我没在论文中找到 -
如何执行high-level的动作,例如open?
答:我不太了解该环境配置,我猜AI2-iTHOR中直接提供了open这种动作
总结
我总结的limitation
从“配置”一节可以看出,这篇工作聚焦于high-level的动作空间,动作覆盖的范围有限,而且增加一种动作就要新增一个输出通道。数据采样的效率堪忧,而且强化学习训练不太稳定。
这篇文章的优点在于:
(1)动态、高效的探索巨大空间的环境
(2)具有连贯的第一视角,可以拥有上下文信息
(3) 可以快速探索未知新环境,具有适应性、泛化性
作者提出了展望:
未来的工作可以在可供性预测中对更多的环境状态进行建模(例如,代理持有什么或过去的交互),并将更复杂的策略架构与空间记忆相结合。
我觉得这对输入信息的要求更加复杂,需要拥有更多的环境信息。
想更深入了解Affordance learning,请关注本系列的其他文章。
笔者才刚刚入门,有什么问题欢迎指正!
参考
Learning Affordance Landscapes for Interaction Exploration in 3D Environments翻译
更多推荐

 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)