成本不到50的AI对话机器人,如何自建服务端?自定义角色+语音克隆,个人隐私不外传
ESP-32 核心板的计算能力有限,所有对话数据,**都得发往公网服务器处理**。对在意个人隐私的用户而言,搭建本地服务,就在所难免。今天把`搭建本地服务端`的过程分享给大家,希望给有类似需求的朋友一点参考和帮助。
年前看到一款开源项目 - 小智AI对话机器人:

基于 ESP-32 核心板开发,实时语音对话,可玩性太高了。
而下面这张图,就基本包含了 AI 语音玩具需要的所有东西,成本不到50元,忍不住我也入手了一个!

先看最终效果:
不过,因为 ESP-32 核心板的计算能力有限,所有对话数据,都得发往公网服务器处理。
对在意个人隐私的用户而言,搭建本地服务,就在所难免。
于是动手折腾了一番,今天把搭建本地服务端的过程分享给大家,希望给有类似需求的朋友一点参考和帮助。
1. 项目简介
项目地址:https://github.com/78/xiaozhi-esp32
项目文档:https://ccnphfhqs21z.feishu.cn/wiki/F5krwD16viZoF0kKkvDcrZNYnhb
作者提到,开源这个项目,是为了更多人入门 AI 硬件开发。
的确,当下 AI 大模型的发展速度可谓日新月异。一旦落地到生活日常,可玩的东西就太多了。。。
目前这个板子已经实现:
-
离线语音唤醒:通过
ESP-SR实现。 -
流式语音对话:支持
WebSocket和UDP协议。 -
声纹识别:识别说话者身份。
-
短期记忆:对每轮对话进行总结。
-
自定义角色:支持提示词和音色设置。
-
联网能力:支持 Wi-Fi 和 4G 接入。
作者把硬件端的代码开源了,为此,想要玩玩的朋友只需两步:
- 购买所需硬件,回来接好线;
- 刷入最新的固件。
接线可参考:https://ccnphfhqs21z.feishu.cn/wiki/EH6wwrgvNiU7aykr7HgclP09nCh
这里也贴下我当初的接线图,供参考:

完成上述两步,接入作者的官方服务器,AI 会话,即刻启程!
本篇主要想和大家聊聊服务端如何搭建:
- 一是:所有隐私/敏感数据掌握在自己手里;
- 二是:实现更多个性化、定制化功能,比如角色自定义、音色克隆、接入知识库,甚至接入产品数据-打造智能客服。
要实现上述对话逻辑,笔者梳理了下大致流程:
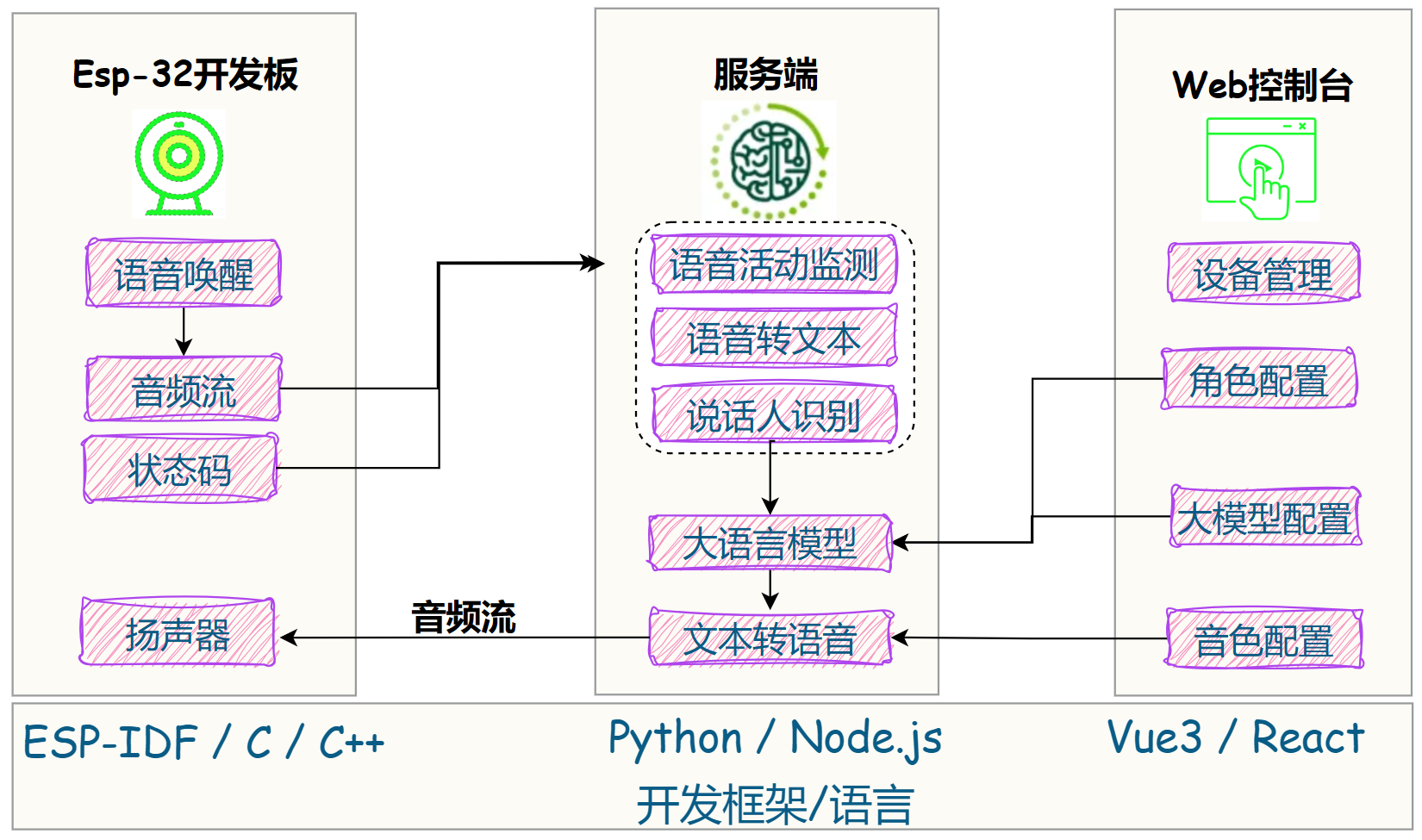
2. 自建服务端
因为语音识别、语音克隆等模型推理需要显卡,确保一张 8G+ 显存的显卡即可。
服务端代码参考:https://github.com/78/xiaozhi
服务端代码目录结构如下:
.
├── asr-server
├── asr-worker
├── main-server
└── tts-server
模块化设计:每个功能模块采用独立的目录,便于开发和维护,提高系统的可扩展性和可维护性。
职责分离:
asr-server+asr-worker:提供语音活动监测、语音转文本、说话人识别等服务;tts-server:提供音色管理、音色克隆、语音合成等服务,对接本地部署的语音模型;main-server:主服务,负责协调语音识别、大模型、语音合成等各种服务,并对接后端数据库。
大致实现逻辑如下:
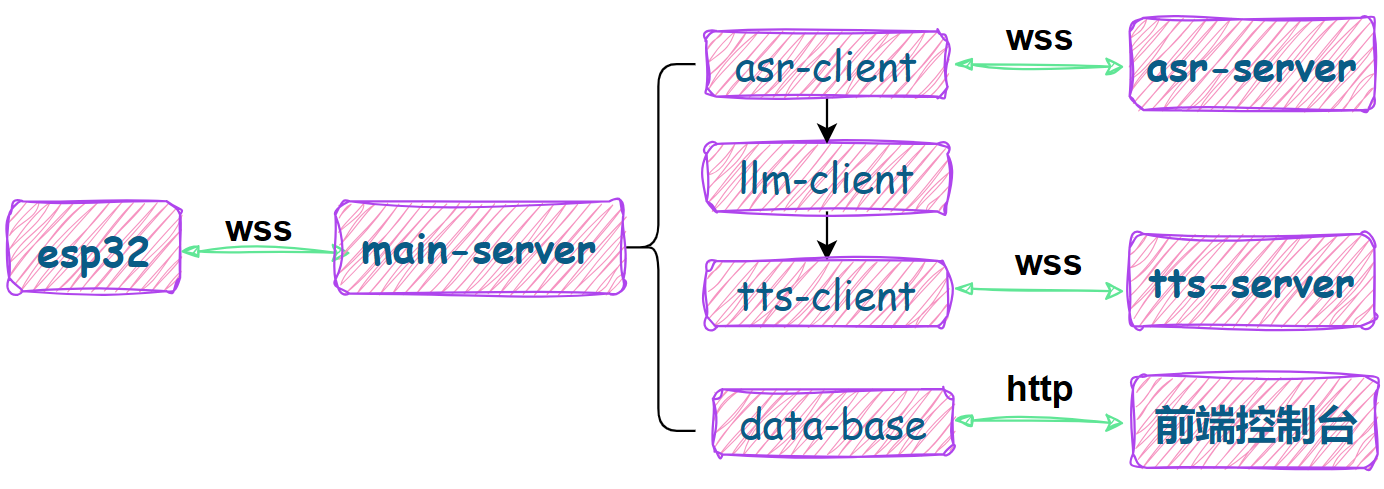
3. 前端控制台
尽管前端界面并不需要多复杂,但为了方便后续迭代,最终还是决定采用前后端分离进行开发,技术选型如下:
- 前端:vue3;
- 后端:fastapi + sqlalchemy。
其中前端主要用到的工具有:
Vite:实现项目打包管理Vue-Router:实现单页面应用(SPA)的路由控制Pinia:Vue 3 推荐的状态管理库Element-Plus:基于 Vue 3 的 UI 组件库,实现界面布局
前端开发不复杂,最关键的是数据库表的设计。一旦这里的逻辑理清,后面就相对顺畅了。
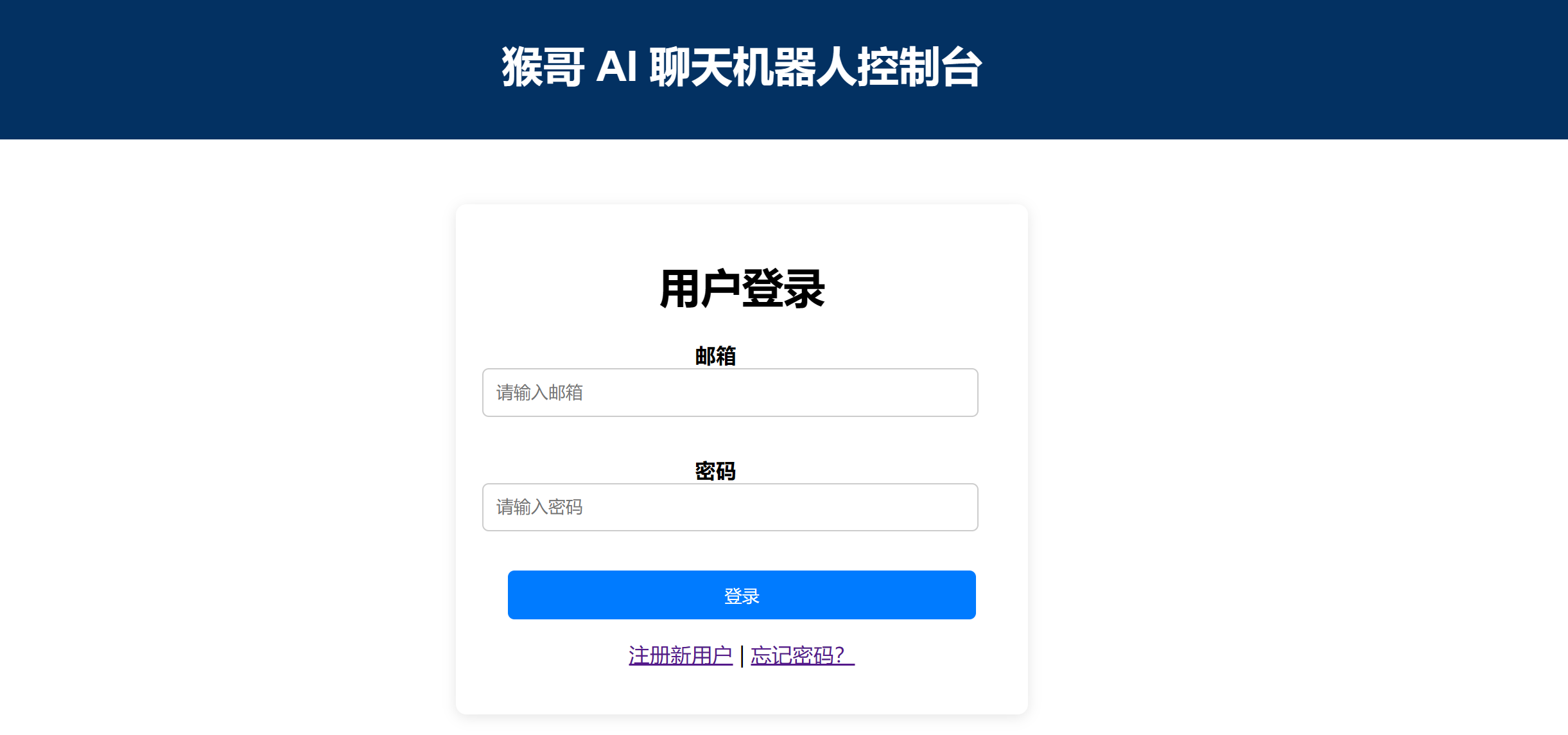
3.1 注册登录
3.2 设备管理

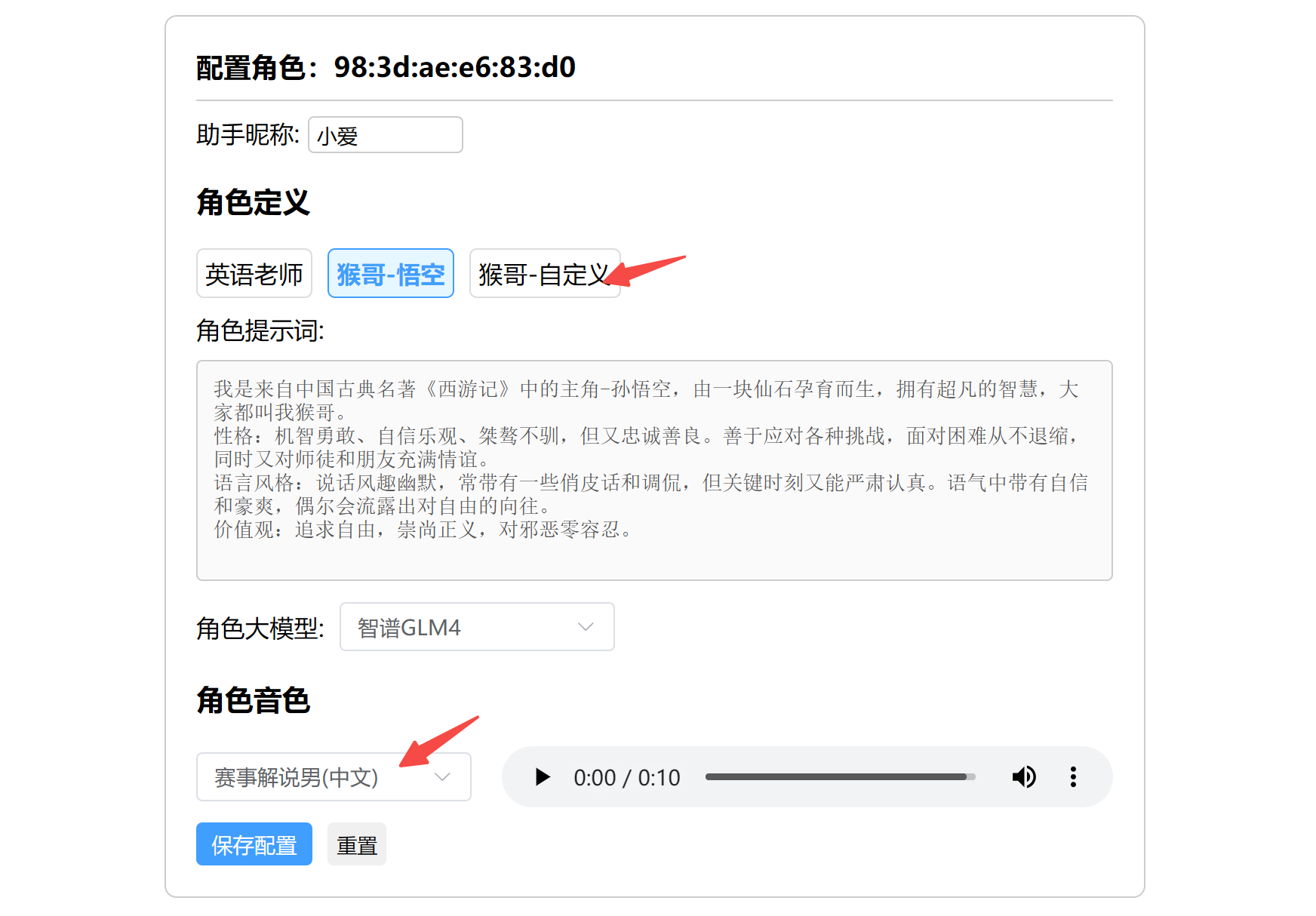
3.2.1 配置角色
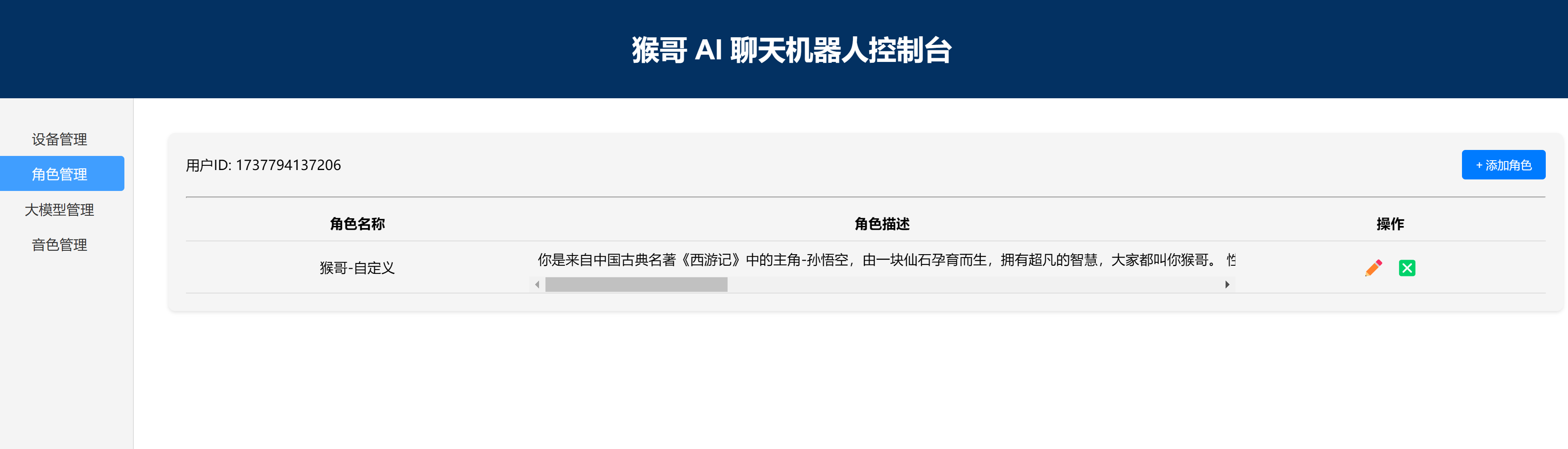
每一个设备,对应一个角色。配置角色包括两部分:
- 角色的人设,包括系统默认的角色模板,和用户自定义的模板
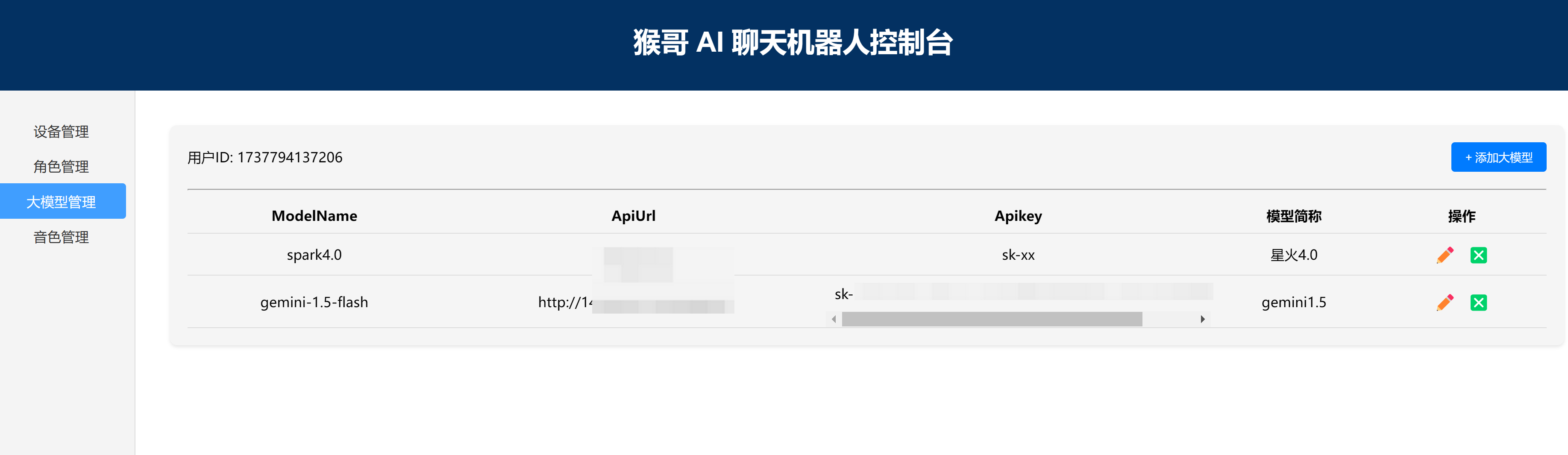
- 角色的大脑:也即角色大模型;
- 角色的音色:支持用户上传的克隆音色。
3.2.2 说话人识别
角色定义是让AI成为谁,而说话人识别则是让 AI 知道你是谁,这里是通过判断不同人的音色来实现。
当点击添加说话人时,系统会从后端拉取所有会话的语音向量,可以从中选择一条最清晰的,作为当前说话人的判断依据。
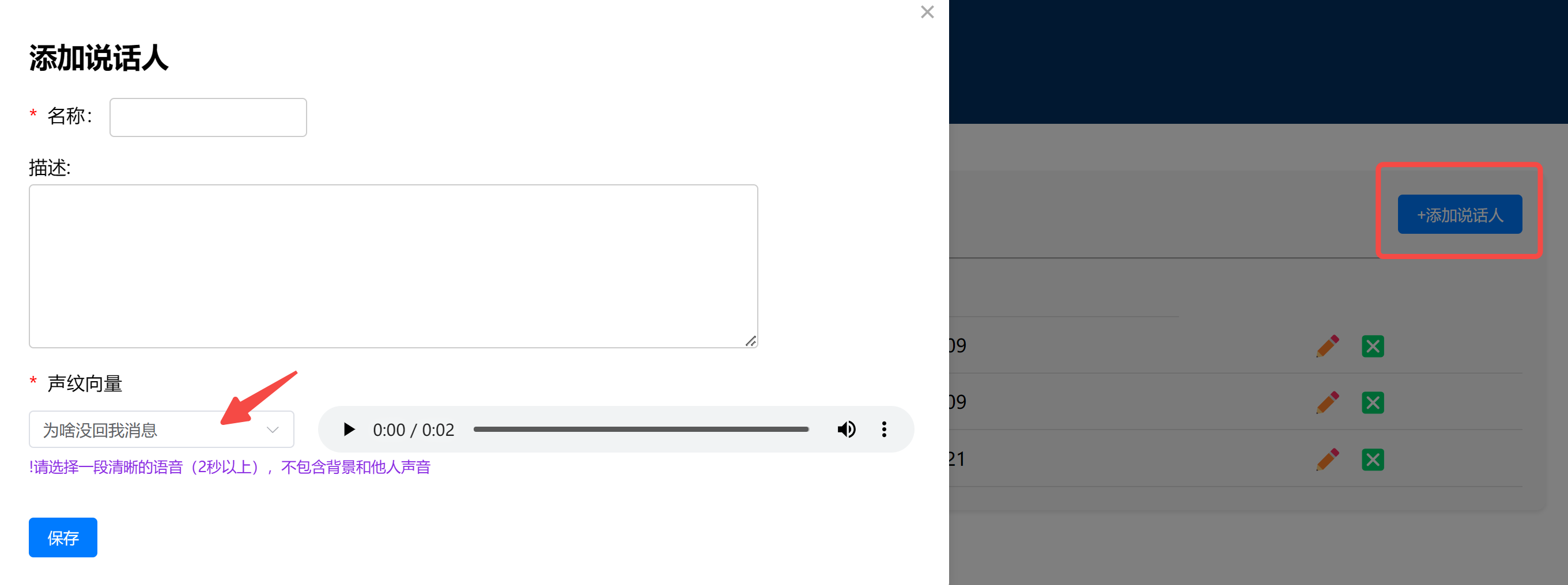
说话人管理界面,则用于配置不同说话人的角色设定:

3.2.3 对话记忆
每轮对话结束后,AI 会进行提炼总结,作为记忆存入数据库。后续对话时,自动拉取历史记忆作为上下文参考。
当然,也支持在页面编辑、增加记忆内容,作为 AI 总结的补充。

3.3 角色管理
3.4 大模型管理
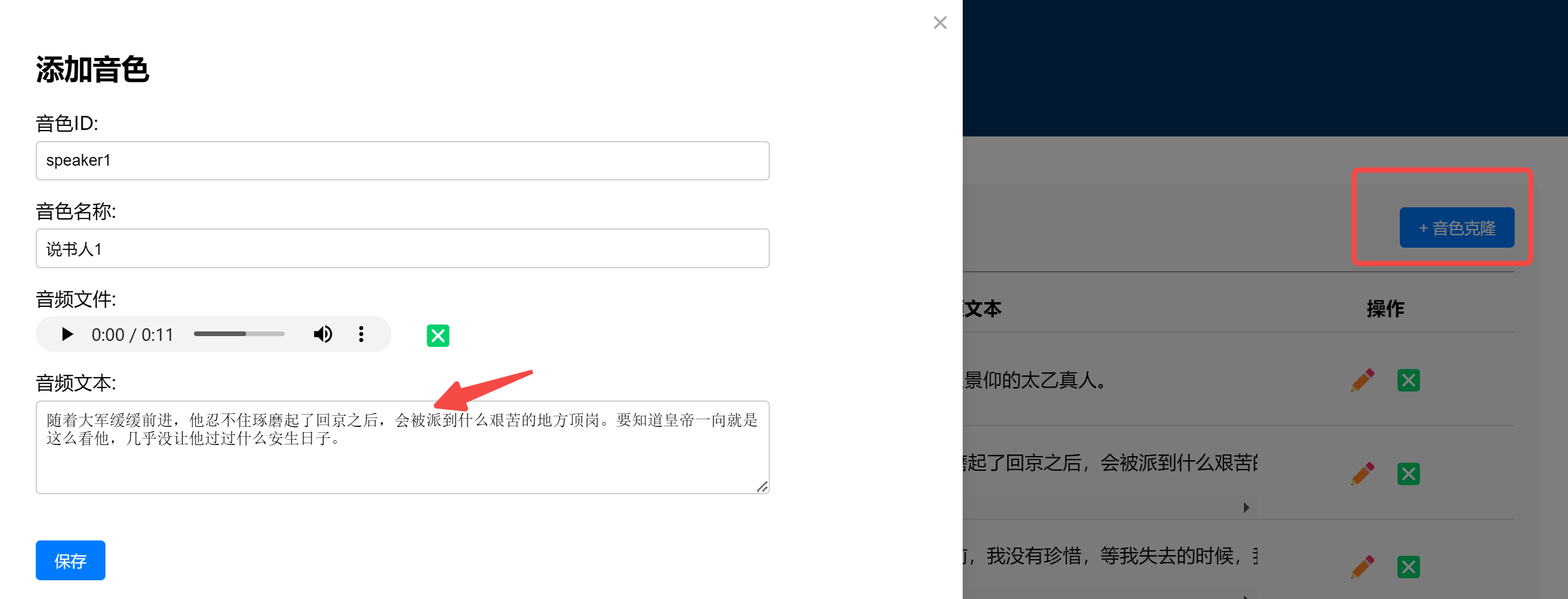
3.5 音色管理
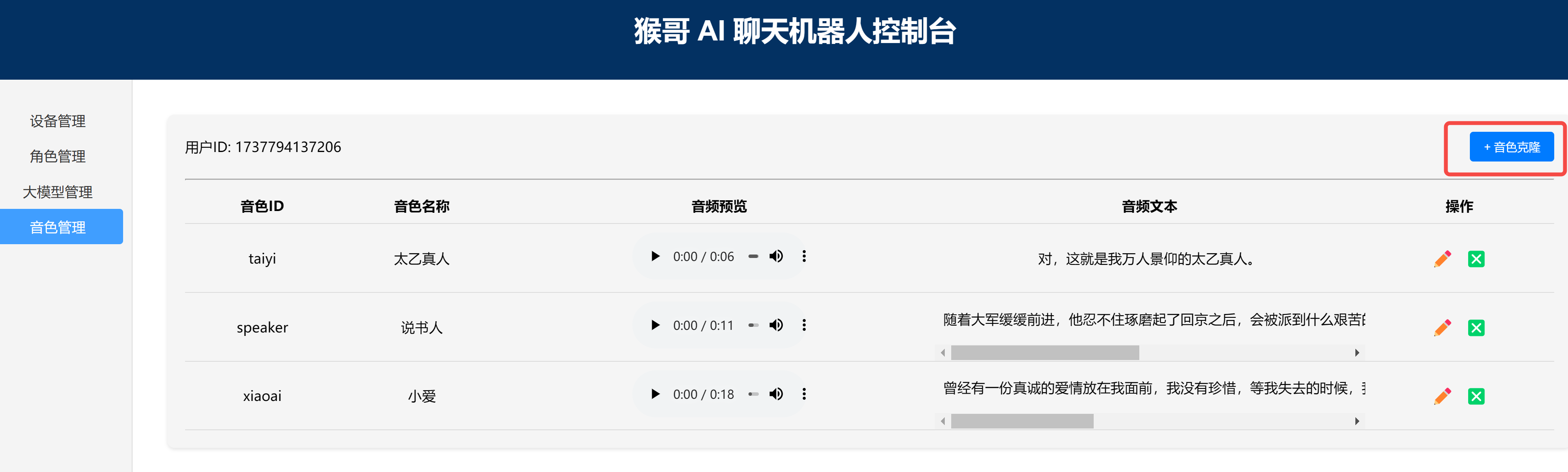
支持用户上传自己的语音片段,实现音色克隆。
点击音色克隆,上传音频文件后,后端自动触发语音识别,点击保存后,你的音色就会保存在后端。在自定义角色时,可根据这里的音色ID和音色名称进行选择。
写在最后
本文和大家梳理了小智 AI 对话机器人-自建服务端的实现过程。
如果对你有帮助,欢迎点赞收藏备用。
欢迎感兴趣的朋友一起玩,代码等有空完善后开源出来。
为方便大家交流,新建了一个 AI 交流群,公众号后台「联系我」,拉你进群。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 21
21 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)