Rasa中文聊天机器人项目学习笔记
RASA中文聊天机器人项目笔记项目结构解析项目结构解析文件/文件夹含义init.py空文件actions.py可以自定义的actions代码config.ymlRasa NLU和Rasa Core的配置文件credentials.yml定义和其他服务连接的一些细节data/nlu.mdRasa NLU的训练数据data/stories.mdRasa stories数据domain.ymlRasa
RASA中文聊天机器人项目笔记
配置过程
简单的参考官网来进行环境配置,这里使用python3.7环境,通过使用命令pip install rasa来配置rasa;再通过rasa init --no-prompt命令生成基本的项目结构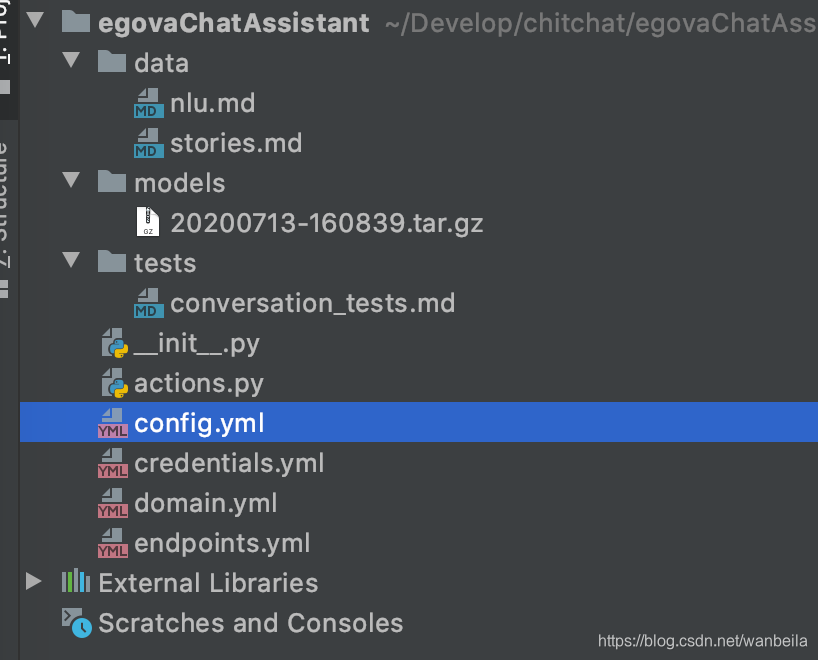
项目结构解析
| 文件/文件夹 | 含义 |
|---|---|
| init.py | 空文件 |
| actions.py | 可以自定义的actions代码 |
| config.yml | Rasa NLU和Rasa Core的配置文件 |
| credentials.yml | 定义和其他服务连接的一些细节 |
| data/nlu.md | Rasa NLU的训练数据 |
| data/stories.md | Rasa stories数据 |
| domain.yml | Rasa domain文件 |
| endpoints.yml | 和外部消息服务对接的endpoints配置 |
| models/.tar.gz | 训练模型数据 |
NLU模型
查看项目中的.nlu文件,首先NLU表示的是Natural Language Understanding,它的作用就是将用户自然语言信息转换为结构化的数据。也就是通过提供训练的样本来告诉rasa模型应该如何去理解用户的消息,然后根据这些样本来训练模型。下图展示的是根据rasa初始化生成的nlu.md文件内容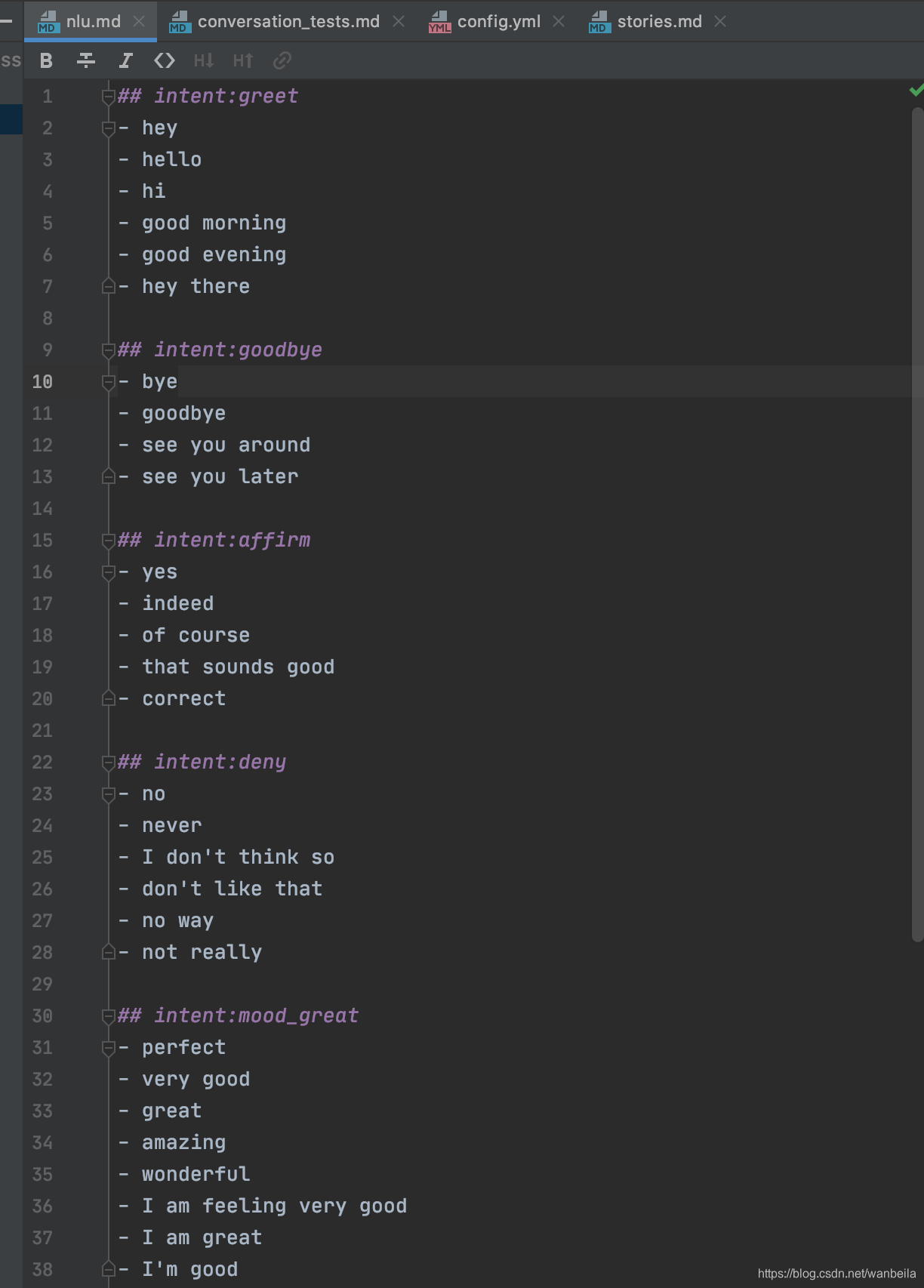
其中以##开头的表示的是用户的意图,下面是一组具有相同含义的名词的集合。Rasa的任务就是在用户输入新的消息时也能预测出正确的意图。
Policies选择

rasa.core.policies.Policy类主要是用来在每一次对话后决定采取哪一种action;一般来说都会有多个策略可供选择,默认情况下,代理最多可以在每个用户消息之后预测10个下一步操作。要更新此值,可以将环境变量MAX NUMBER OF prediction设置为所需的最大预测数。
policies:
- name: “KerasPolicy”
featurizer:
- name: MaxHistoryTrackerFeaturizer
max_history: 5
state_featurizer:
- name: BinarySingleStateFeaturizer
- name: “MemoizationPolicy”
max_history: 5- name: “FallbackPolicy”
nlu_threshold: 0.4
core_threshold: 0.3
fallback_action_name: “my_fallback_action”- name: “path.to.your.policy.class”
arg1: “…”
1、max_history
rasa核心的策略的一个重要的超参数即为max_history,它代表了模型将会根据多少条历史的对话来决定下一个action的选择。
* out_of_scope
- utter_default
* out_of_scope
- utter_default
* out_of_scope
- utter_help_message
类似于上述的方式,将max_history设置为4,当用户出现了多次意外的输入情况,就可以通过设置max_history来实现不同的相应结果。
但是当该值继续增大时,会导致模型的体量以及训练时间大大增加。如果确实有一些内容会影响到较为远的时间,可以通过将其设置为slot,Slot对于特征提取是永远有效的。
2、Data Augmentation
–数据集扩充处理
# thanks
* thankyou
- utter_youarewelcome
# bye
* goodbye
- utter_goodbye
当你使用的数据集为以上形式时,默认情况下,rasa会将故事文件中的片段进行随机的拼接形成更长的故事。
如果需要避免在故事之间不相关时忽略对话的历史过程,而只是针对问题进行特定的回答,可以通过设置–augmentation标志来实现。
3、Action Selection
以下策略,数字越大的优先级越高
5. FormPolicy
4. FallbackPolicy and TwoStageFallbackPolicy
3. MemoizationPolicy and AugmentedMemoizationPolicy
2. MappingPolicy
1. TEDPolicy, EmbeddingPolicy, KerasPolicy, and SklearnPolicy
Keras Policy
这里主要就是通过使用神经网络模型来决定下一步的action的选择。默认的模型采用的是LSTM,支持自定义;
Embedding Policy 重新命名为 TED Policy
Mapping Policy
直接通过映射来获取action。
例如:
intents:
- ask_is_bot:
triggers: action_is_bot
一个意图最多支持一个action的映射,当机器人收到触发的意图时就会调用对应的action。
此外,如果你不想让这种映射关系影响到对话历史,那么action的设计应当返回一个UserUtteranceReverted()事件,这样做能够删除掉用户的最后一条消息。这也意味着不要把这种intent-action写到故事文件中。
Memoization Policy
MemoizationPolicy只是在您的训练数据中存储对话。 如果训练数据中存在此确切对话,则它会以置信度1.0预测下一个动作,否则会以置信度0.0预测无。
Form Policy
是MemoizationPolicy的一个拓展。
Augmented Memoization Policy
Fallback Policy
这个应该就是一种缺省的策略。
policies:
- name: "FallbackPolicy"
nlu_threshold: 0.3
ambiguity_threshold: 0.1
core_threshold: 0.3
fallback_action_name: 'action_default_fallback'

Two-Stage Fallback Policy

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)