SAM2从头训练自己的数据集
说点废话1.准备数据集2.配置训练文件3.开始训练4.预测结果。
·
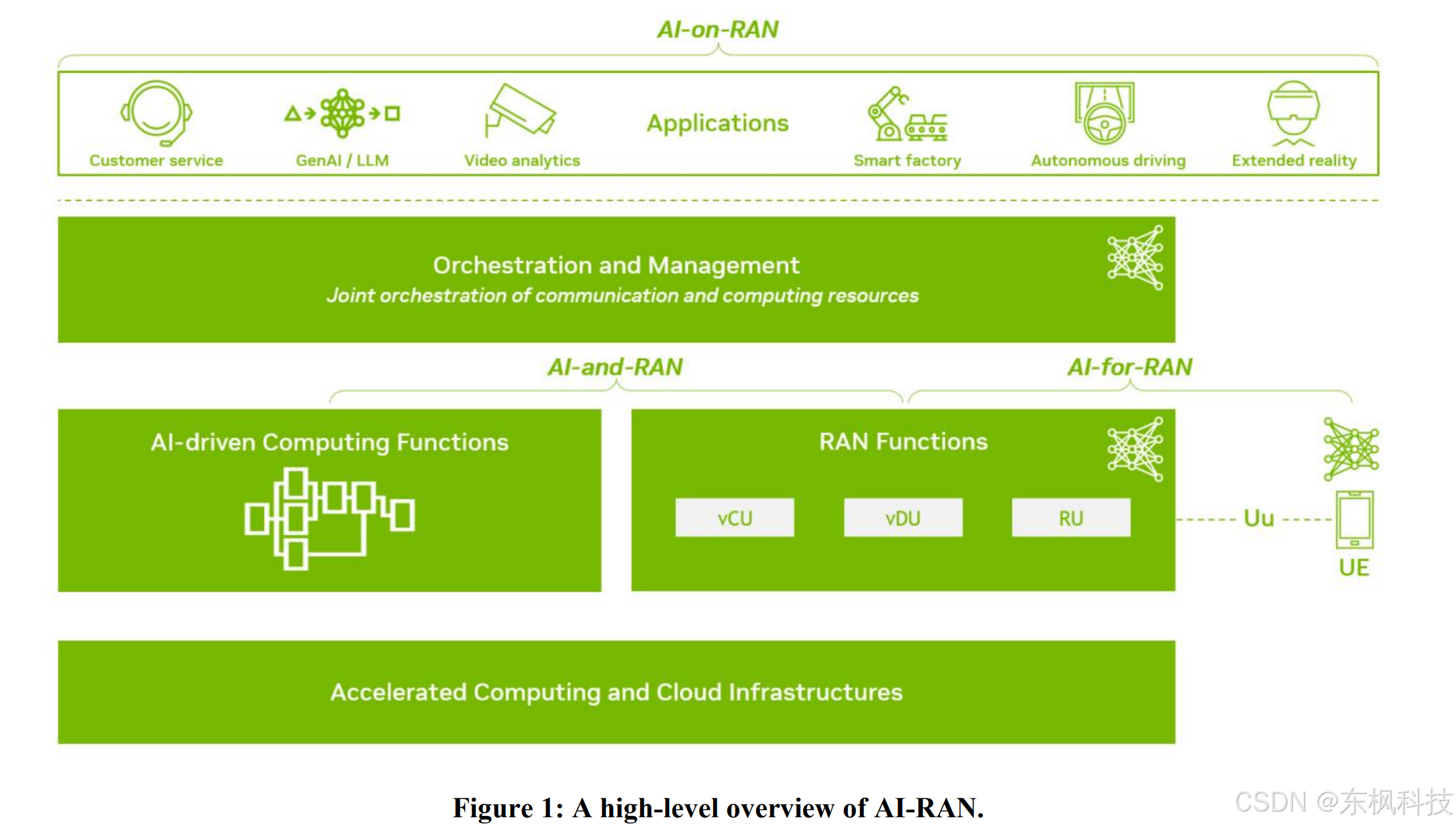
说点废话
硬件配置,一块3080GPU,系统为linux
我们默认你已经配置好了cuda,pytorch,可以正常推理,推理代码在官方提供的notebook中,我们只讲解训练部分,因为这部分我搜了一圈没人正儿八经的做,而且我仅仅做出了图像的训练,视频训练还没有做,那么好,我们开始
1.准备数据集
使用roboflow标注图像分割,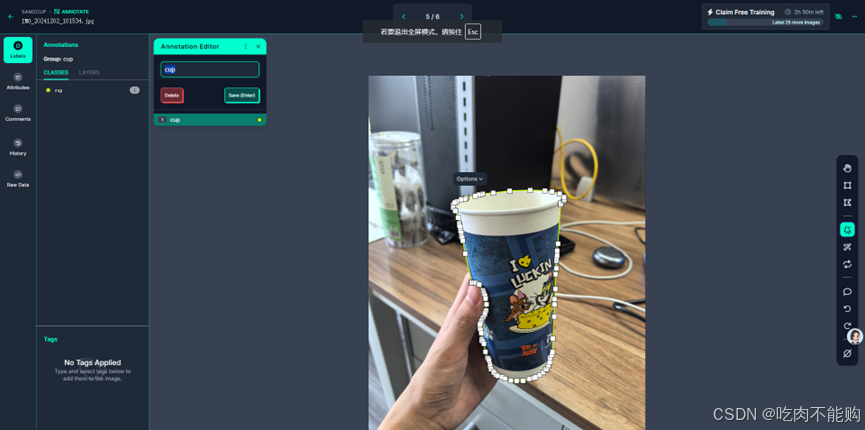
这里我选择了杯子,总共6张图片,我个人认为这6张图像特征清晰,足够SAM2学习了,
直接导出SAM2数据格式: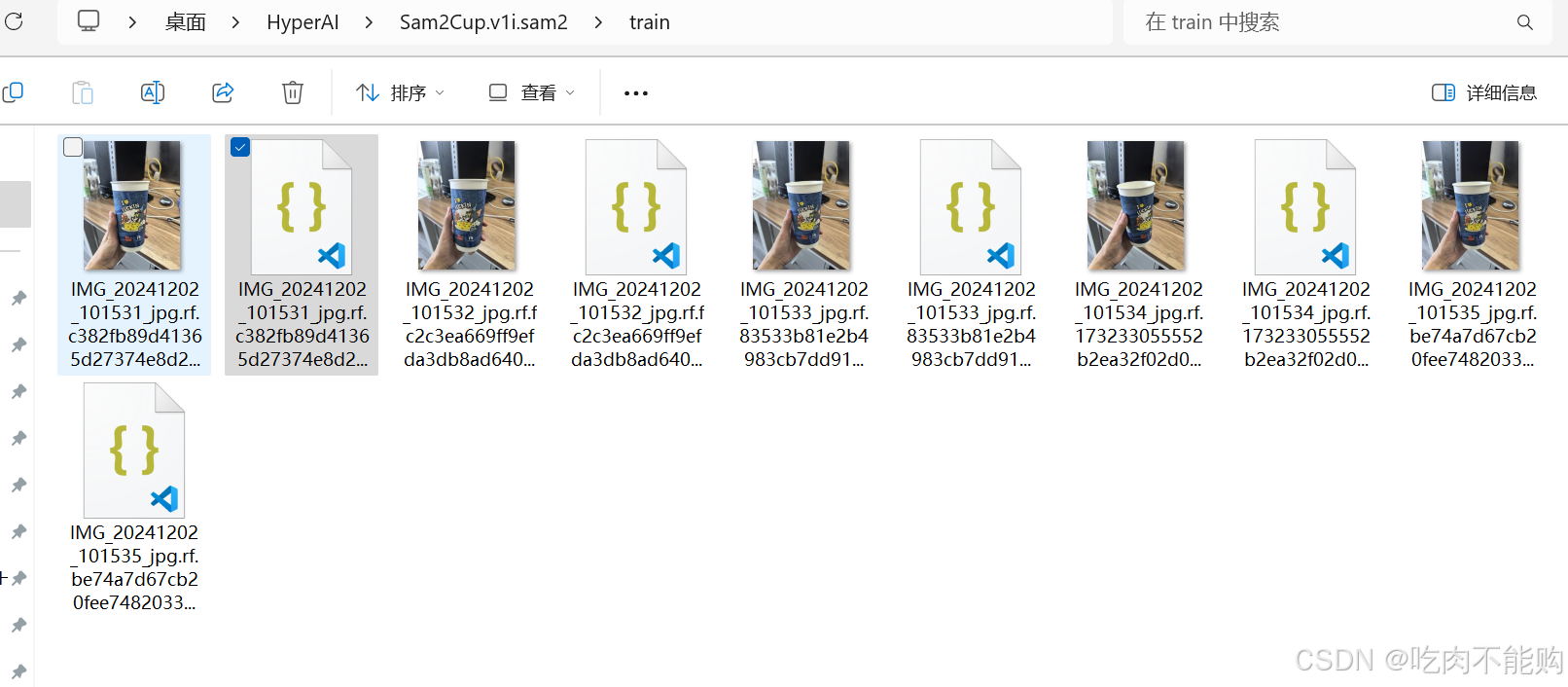
注意,roboflow导出的文件名xxx.rf.xxx.jpg,会让SAM2的dataloader识别错误,用脚本把多余的点替换成下划线
2.配置训练文件
改一下train.yaml的路径:
img_folder: /home//train
gt_folder: /home//train
3.开始训练
python training/train.py -c 'configs/train_xcb_cup.yaml' --use-cluster 0 --num-gpus 1
我觉得杯子比较简单,训练40轮足够了,用tensorboard查看训练曲线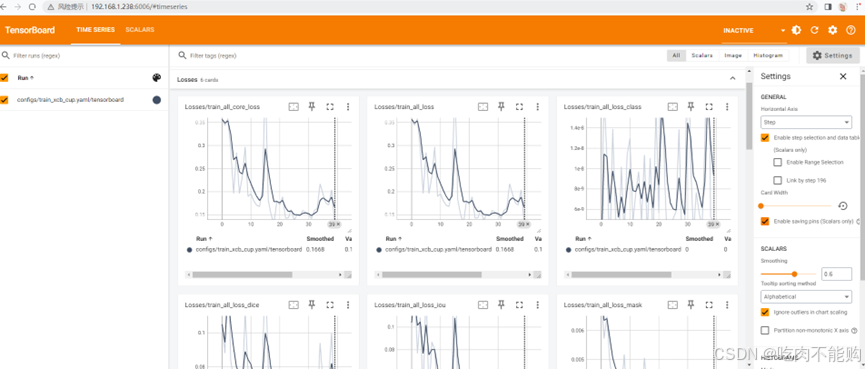
4.预测结果

注意:图像控制在1024分辨率以下,不然3080GPU显存不够,
——左侧为基础模型预测,所以杯子被分割成了许多部分,包括上,中,下,以及TOM的嘴巴和耳朵都被分开了
——右侧手动标注的杯子整体,被完整 的分割出来了。
最后附一个预测脚本吧,记得点个赞再复制:
import torch
from sam2.build_sam import build_sam2
from sam2.automatic_mask_generator import SAM2AutomaticMaskGenerator
import supervision as sv
import os
import random
from PIL import Image
import numpy as np
# use bfloat16 for the entire notebook
# from Meta notebook
torch.autocast("cuda", dtype=torch.bfloat16).__enter__()
if torch.cuda.get_device_properties(0).major >= 8:
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
# 设置训练后模型的检查点和配置文件路径
checkpoint = "/home//sam2-main/sam2_logs/configs/train_xcb_cup.yaml/checkpoints/checkpoint.pt"
model_cfg = "configs/sam2.1/sam2.1_hiera_b+.yaml"
# 构建训练后的模型
sam2 = build_sam2(model_cfg, checkpoint, device="cuda")
mask_generator = SAM2AutomaticMaskGenerator(sam2)
# 设置基础模型的检查点和配置文件路径
checkpoint_base = "/home/sam2-main/checkpoints/sam2.1_hiera_base_plus.pt"
model_cfg_base = "configs/sam2.1/sam2.1_hiera_b+.yaml"
# 构建基础模型
sam2_base = build_sam2(model_cfg_base, checkpoint_base, device="cuda")
mask_generator_base = SAM2AutomaticMaskGenerator(sam2_base)
# 获取验证集图片列表并随机选择一张.jpg图片
validation_set = os.listdir("/home//valid/di")
image = random.choice([img for img in validation_set if img.endswith(".jpg")])
image = os.path.join("/home//valid/di", image)
# 打开图片并转换为RGB格式,再转换为numpy数组
opened_image = np.array(Image.open(image).convert("RGB"))
# 使用训练后的模型生成预测结果
result = mask_generator.generate(opened_image)
# 将预测结果转换为Detections对象
detections = sv.Detections.from_sam(sam_result=result)
# 创建MaskAnnotator对象用于标注图片
mask_annotator = sv.MaskAnnotator(color_lookup = sv.ColorLookup.INDEX)
# 复制原始图片用于标注
annotated_image = opened_image.copy()
# 对图片进行标注
annotated_image = mask_annotator.annotate(annotated_image, detections=detections)
# 创建用于基础模型标注的MaskAnnotator对象
base_annotator = sv.MaskAnnotator(color_lookup = sv.ColorLookup.INDEX)
# 使用基础模型生成预测结果
base_result = mask_generator_base.generate(opened_image)
# 将预测结果转换为Detections对象
base_detections = sv.Detections.from_sam(sam_result=base_result)
# 复制原始图片用于标注
base_annotated_image = opened_image.copy()
# 对图片进行标注
base_annotated_image = base_annotator.annotate(base_annotated_image, detections=base_detections)
# 将标注后的图像保存到本地磁盘,以便通过图像查看器查看
annotated_image_path = "/home//output/annotated_fine_tuned.jpg"
base_annotated_image_path = "/home//output/annotated_base.jpg"
Image.fromarray(annotated_image).save(annotated_image_path)
Image.fromarray(base_annotated_image).save(base_annotated_image_path)
print("标注后的精细调整模型图像已保存到:", annotated_image_path)
print("标注后的基础模型图像已保存到:", base_annotated_image_path)

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)